

wheel
-
Posts
236 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by wheel
-
Aaaaand my IP just dropped and renewed on that box again out of nowhere. Logging from that happening up to most current log entry: Jan 8 17:14:39 Tower3 kernel: mdcmd (1048): spindown 4 Jan 8 17:49:39 Tower3 kernel: mdcmd (1049): spindown 1 Jan 8 18:00:38 Tower3 dhcpcd[1703]: eth0: NAK: from 10.0.0.1 Jan 8 18:00:38 Tower3 avahi-daemon[3554]: Withdrawing address record for 10.0.0.9 on eth0. Jan 8 18:00:38 Tower3 avahi-daemon[3554]: Leaving mDNS multicast group on interface eth0.IPv4 with address 10.0.0.9. Jan 8 18:00:38 Tower3 avahi-daemon[3554]: Interface eth0.IPv4 no longer relevant for mDNS. Jan 8 18:00:38 Tower3 dhcpcd[1703]: eth0: deleting route to 10.0.0.0/24 Jan 8 18:00:38 Tower3 dhcpcd[1703]: eth0: deleting default route via 10.0.0.1 Jan 8 18:00:38 Tower3 dnsmasq[4383]: no servers found in /etc/resolv.conf, will retry Jan 8 18:00:38 Tower3 dhcpcd[1703]: eth0: soliciting a DHCP lease Jan 8 18:00:39 Tower3 dhcpcd[1703]: eth0: offered 10.0.0.17 from 10.0.0.1 Jan 8 18:00:39 Tower3 dhcpcd[1703]: eth0: probing address 10.0.0.17/24 Jan 8 18:00:43 Tower3 dhcpcd[1703]: eth0: leased 10.0.0.17 for 86400 seconds Jan 8 18:00:43 Tower3 dhcpcd[1703]: eth0: adding route to 10.0.0.0/24 Jan 8 18:00:43 Tower3 dhcpcd[1703]: eth0: adding default route via 10.0.0.1 Jan 8 18:00:43 Tower3 avahi-daemon[3554]: Joining mDNS multicast group on interface eth0.IPv4 with address 10.0.0.17. Jan 8 18:00:43 Tower3 avahi-daemon[3554]: New relevant interface eth0.IPv4 for mDNS. Jan 8 18:00:43 Tower3 avahi-daemon[3554]: Registering new address record for 10.0.0.17 on eth0.IPv4. Jan 8 18:00:43 Tower3 dnsmasq[4383]: reading /etc/resolv.conf Jan 8 18:00:43 Tower3 dnsmasq[4383]: using nameserver 10.0.0.1#53 Jan 8 18:19:10 Tower3 in.telnetd[17347]: connect from 10.0.0.16 (10.0.0.16) Jan 8 18:19:11 Tower3 login[17348]: ROOT LOGIN on '/dev/pts/2' from '10.0.0.16'
-
Yeah, Kodi buddies were mystified too and said it must have something to do with unraid. I'll probably just ignore it for now unless more weird things happen - no real "oh man someone's looking at my stuff" issues so much as "don't want my box to be part of some botnet" concerns.
-
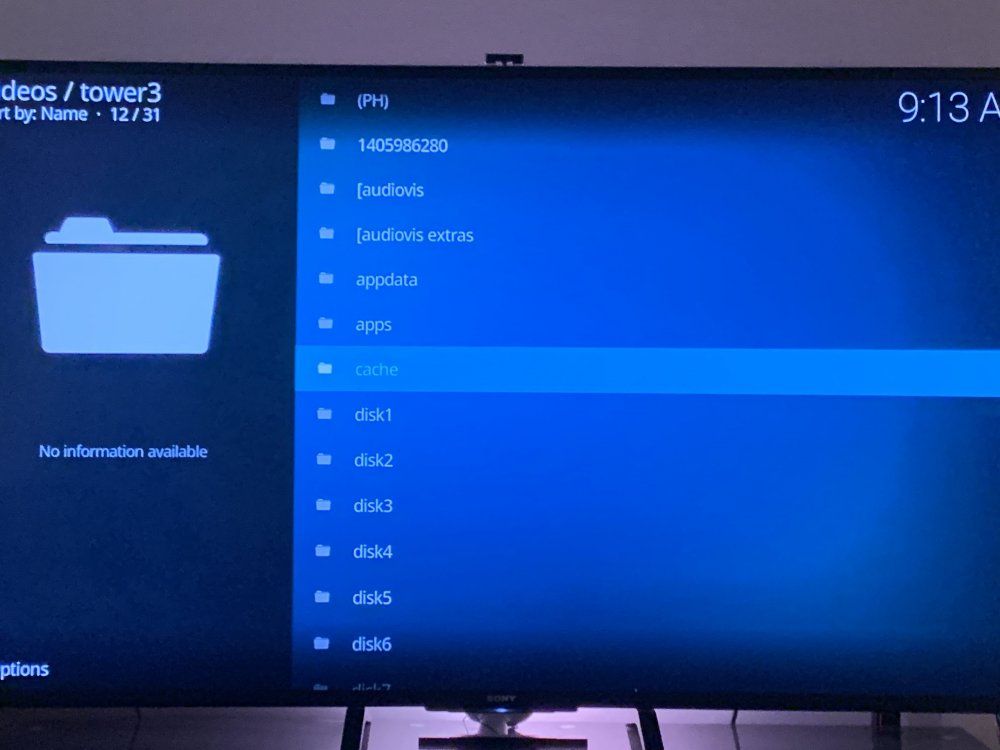
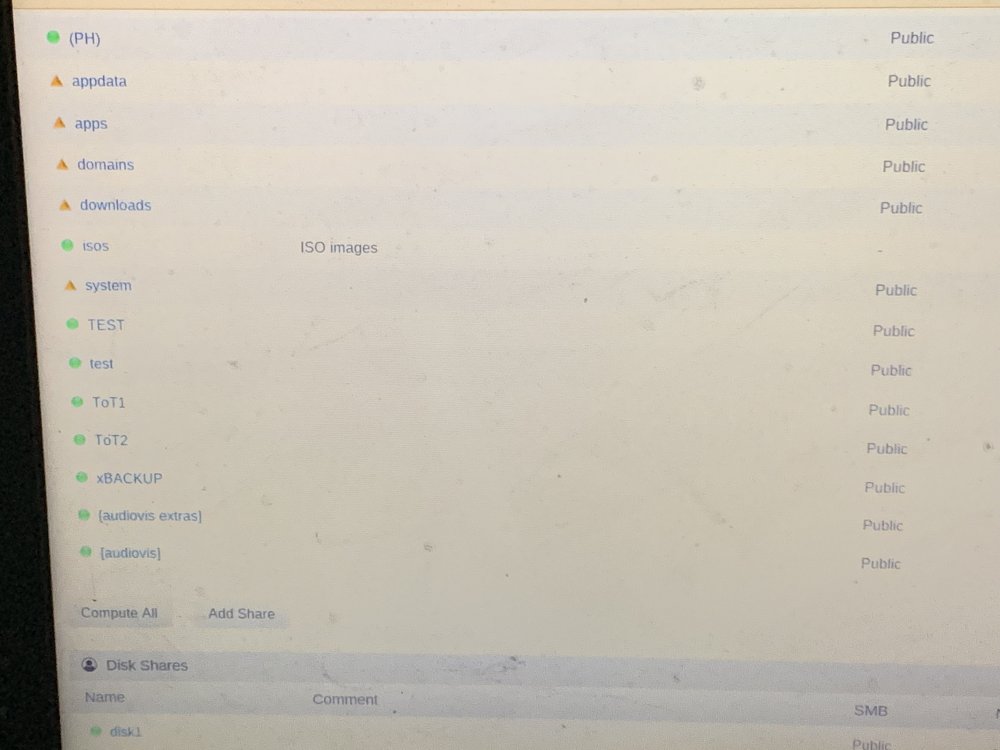
Screenshots attached; "1405986280" is the weirdly inaccessible / not visible on the unraid side folder (Kodi's listing everything that shows up in the root directory of the unraid tower, including shares and actual disks). Thanks for the swift response! And yeah, knew about the DHCP setting, but I feel like I've never had an unraid tower "drop itself" and swap addresses with another device in the middle of a nighttime period of otherwise zero activity for a good while on either side - this and the weird folder got my paranoia tingling.
-
Strangeness continues, with no new ideas on the Kodi front. Woke up this morning, and my tower's weirdly assigned to a different IP address. Feels like it's the first time it's ever happened in a decade of unraid usage. No new strange wireless or wired devices showing up on my network, but the old unraid address is now being held by a wireless device (iPad) which was turned on, connected to wifi, in the home, and completely untouched for hours before and hours after the swap. This looks like where it happened in the log; full diagnostics attached again. tower3-diagnostics-20200108-1542.zip
-
Yeah, I've been meaning to work on circulation - weekend project for sure! I ran ls -ail /mnt/user, and the 10-digit folder doesn't show up. Everything else looks in order. If nothing else seems off from the unraid end of things, I'm going to check with Kodi forums to see if that software has a history of "creating" weird folders like this that only it can see. Thanks for the swift help!
-
Random, and possibly innocuous, but figured I'd check to see if this has ever happened to anyone before and been a warning sign: A strange folder is showing up among all my other user shares (named "1405986280") when I look at my unraid box's list of usual user shares in Kodi. It's not showing up in any of the individual drives viewed by Windows or Putty terminal. It's not showing up under /user or /user0. When I click on it in Kodi to try and access it, I'm warned that the share is not available. If I reset the Kodi system and go back to the folder list, the strange 10-digit folder is there and still inaccessible. Could someone have compromised my Unraid box and created some sort of folder like this for whatever purpose? If so, is there a good way to go about finding out when it happened if it didn't occur during my system's current log uptime? tower3-diagnostics-20200104-0231.zip
-
Earlier this year, a disk inexplicably dropped from my array (but looked fine on SMART), and my Marvell AOC-SASLP-MV8 PCI Express x4 Low Profile Controllers were identified as the culprit (see attached logs for where the machine was left last time it was active - I have not turned it back on since they were captured). Those cards were totally fine in my 5.0 days, but I'm on 6.0+ now and forever with this box, so... I'm finally ready to make the LSI Controller upgrade and get this box back up and running! I thought I'd ask three big questions in here before I put any money down just to be safe: (1) From what I've read on IT flashing, I personally won't have an easy time of doing it (will need to disable and mess with a pretty crowded active unraid box regardless of which board I use to flash the controller), so unless the cost difference is double or more what I'd pay for something I need to flash, I'm fine with paying a premium for a plug-n-play return to form. It sounds like Dell H310 6Gbps SAS HBA LSI 9211-8i P20 IT Mode Low Profile or HP H220 6Gbps SAS PCI-E 3.0 HBA LSI 9207-8i P20 cards might be good options for my setup, but I figured I'd check in here with my diagnostics to be safe. (2) If I'm getting Dell H310 6Gbps SAS HBA LSI 9211-8i P20 IT Mode Low Profile or HP H220 6Gbps SAS PCI-E 3.0 HBA LSI 9207-8i P20 or something completely different, is there a particular retailer I should steer toward or country I should avoid in hopes of getting my shipment within a week or so of ordering? Right now I'm leaning toward "The Art of Server" on eBay, who pre-flashes, prices seem right (especially for the Dell) and seems fast on shipping. (3) Once the cards arrive, should I take any special steps in terms of re-attaching drive cables, or do anything on the unraid GUI before I remove the SASLPs and install the LSIs? Since the April problem disk's apparently physically fine, I'm hoping to get everything back to where it was in April by simply buying new cards and replacing the old ones, but I'm paranoid there's a step I'm missing despite all the threads I've gone through on these Marvell issues. Bonus Question: Am I looking at this entirely wrong? Am I stuck in the past and there's something new I could be doing with controller cards vs getting another pair of low-profile 8-SAS-lane cards, and I'm completely overlooking it? I think I'm on the right track, but again, asking to be safe; I don't upgrade often, so I may as well future proof as much as possible (don't really need more drive performance day to day, but faster parity checks would be nice). Thanks in advance to everyone for any guidance before I embark on my biggest unraid hardware upgrade since I started using the product 8 years ago! tower-diagnostics-20190418-2316.zip tower-diagnostics-20190418-2344.zip
-
Well, hell. Nothing like staying up late to complete a rebuild and starting the parity check immediately after and doing it half-cocked because I'm half-asleep. Hopefully the slew of errors during the correcting check didn't screw me on a rebuild, but if I lost a few things, c'est la data.
-
Definitely was a non-correcting parity check as usual, which is what I figured was going to make it easy to pick up where I left off. Looking at the log I'd initially posted, no obvious errors during the rebuild. Damn glad to hear it - thanks for the help/confirmation!
-
So I booted back up after reseating the disk in the drive cage and nothing changed; zero recognition of the disk being present at all. Removed the disk, put it in an esata caddy attached to another unraid box I occasionally use for preclearing, and turned it on. Drive had a very labored spin up sound and loudly beeped twice almost immediately upon starting up. Disk is detectable in UnRaid GUI, but when I try to manually run a SMART report using the disk's unraid ID (sdo, in this case), a "scsi error device not ready" prompt kills the attempt. SMART reports running fine on everything else. Amazingly, this 8tb drive may have survived 3 full cycles of preclear, a full rebuild cycle, and then promptly died about 40 minutes into the parity check for that preclear cycle based on the timing in my logs. I went out and got another 8tb and am in the process of preclearing that one - despite not successfully finshing the parity check after the successful rebuild, can I just drop the new 8tb where the old 8tb was and run the rebuild process again, or do I need to reuse the old 4tb that was there to return to the "old parity" before attempting to expand that slot again with the 8tb?
-
OK, stopped the array, shut the system down without issue. Restarted after a few minutes, and the GUI says there's no device at all on Disk 10. I'm thinking I might need to disconnect and reconnect the drive from the hotswap cage for Unraid to detect it again, but I'm going to wait on doing that for a little while in case anyone thinks I should do anything else first. EDIT: Actually may have made a mistake. When I booted back up, the 8tb drive that had just been rebuilt was showing in the italics below the dropdown box, but no drive was available to select in the dropdown box. I started the array in maintenance mode to see if that would allow recognition of the drive that threw up all the errors (Disk 10) so I could run a SMART test. It didn't, so I exited maintenance mode and powered down. I've started the system up again, and the GUI shows "not installed" under the redballed Disk 10 entry (vs. the previous ST800DM... text). From what I'm reading, I don't think I screwed anything up by going into maintenance mode, but I'm going to wait to take further steps until someone from the community lets me know what safe steps I should be taking next. Again, I can go back to the original 4TB drive that the 8TB replaced if necessary. I'm thinking about putting the 8TB into an enclosure attached to another box and running SMART there.
-
From reading other threads, I'm thinking I should reboot so I can run a SMART check on Disk 10, but the fact that this is v5 not v6 has me wondering if something is wrong other than the standard SASLP/Marvell issues that seem to happen a lot on v6 boxes. I'm concerned that once I restart to get the SMART, I may lose the opportunity to make changes or get data that may be recommended in here. I'm going to run a few errands and leave the array on / box running, and if nobody's jumped into this thread to say "wait don't turn it off yet" by the time I'm back tonight, I'll go ahead with what seems like the standard post-redball operating procedure for some of the error messages I searched from my syslogs.
-
Bringing this thread back to life because I think I can finally afford the upgrade SASLP controllers to LSI (hoping this is the only box I need to do it on, but guessing my new issues on a 5.0.6 box are going to be chalked up to something similar, so...). I've been searching through threads that include discussion of the SASLP problems and the LSI solutions, but I can't seem to find a comprehensive guide on what specifics I should be looking for when shopping (all I can gather is that I might need to "IT Flash" some that I purchase, and I can't tell whether I'll need a separate device or cable for one of my non-unraid machines to make this flash happen). Am I completely missing some obvious FAQ on the "upgrading your old box to LSI controllers" issue since old SASLP controllers seem to be such a widespread problem for 6.0+ Unraid boxes?
-
Subject says it all; precleared an external 8TB on 3 cycles, shucked it, and the replace/rebuild process finished late last night. I immediately started the parity check and went to bed. Now the GUI is orange, the disc is redballed with 768 errors, and I can't make heads nor tails of the error log. NOTE: This was a non-correcting parity check and I still have the original 4TB drive that was in the slot for Disk 10 to replace and restart everything... if the issue's just a disk that precleared 3x and rebuilt fine but promptly died immediately after the rebuild. Apologies for not being up to date on this box's version, but it's my "least featured" box and needing to upgrade my SAS cards to work with newer versions of Unraid on other boxes kept me from upgrading this one as fast as I did the others. Really hoping that doesn't come back to bite me with a lost disk now... I'm going to leave it powered up and where it was for now in case that helps with resolving this. Thanks in advance for any help anyone can provide! EDIT: Other weirdness; GUI gives me the option to stop the array (which I feel like wouldn't be a bad idea to do?) and Spin Up/Spin Down/Clear Statistics, but no other info. EDIT 2: Tried running SMART on Disk 10 from the command line; results say user capacity is 600 petabytes, which seems a bit high. Logical block size 774843950 bytes, physical block size 3099375800 bytes. Lowest aligned LBA: 14896. On the scsiModePageOffset line(s), it says "response length too short, resp_len=47 offset=50 bd_len=46. "Terminate command early due to bad response to IEC mode page." EDIT 3: It looks like this string of the log is where things went wrong right before the massive stretch of errors on Disk 10: Jul 29 19:30:06 Tower2 kernel: md: sync done. time=113721sec Jul 29 19:30:06 Tower2 kernel: md: recovery thread sync completion status: 0 Jul 29 19:34:42 Tower2 kernel: mdcmd (78): check NOCORRECT Jul 29 19:34:42 Tower2 kernel: md: recovery thread woken up ... Jul 29 19:34:42 Tower2 kernel: md: recovery thread checking parity... Jul 29 19:34:42 Tower2 kernel: md: using 1536k window, over a total of 7814026532 blocks. Jul 29 20:11:26 Tower2 kernel: sd 6:0:2:0: [sdp] command f72d9900 timed out Jul 29 20:11:27 Tower2 kernel: sd 6:0:2:0: [sdp] command eeacbe40 timed out Jul 29 20:11:27 Tower2 kernel: sd 6:0:2:0: [sdp] command eeacb3c0 timed out Jul 29 20:11:27 Tower2 kernel: sd 6:0:2:0: [sdp] command eeacb480 timed out Jul 29 20:11:27 Tower2 kernel: sd 6:0:2:0: [sdp] command eeacb840 timed out Jul 29 20:11:27 Tower2 kernel: sd 6:0:2:0: [sdp] command f73059c0 timed out Jul 29 20:11:27 Tower2 kernel: sas: Enter sas_scsi_recover_host busy: 6 failed: 6 Jul 29 20:11:27 Tower2 kernel: sas: trying to find task 0xf703f900 syslog-5.0.6-postrebuild.txt
-
Well, damn. Looks like I may need an entire new motherboard to go LSI, so this just got interesting. I definitely don’t have the funds or time for a major rebuild anytime soon, and mounting/unplugging/replugging feels crazy risky with one disk potentially on the fritz. Knowing myself personally, if I put resolving this disabled disk situation off until I can replace my motherboard and controller cards, I may as well write this tower off until the end of summer. So since I’m stuck with SASLP for now, if I have to run the risk of losing the disk (hate to do it, but versus almost any other disk it’d be preferable), is there a good way to “grade” my other 18 disks and see if any are close enough to failure that I’m better off using what disk lifespan I have left for a straight rebuild instead of a safety parity check first? Also (and this may be crazy), since it sounds like most of the SASLP issues started with 6 (I know I’d never had any for years), could I conceivably roll back to a pre-6 unraid that still supported >4TB drives (of which I think there were a few stable?) and just keep using that with this box? I can live without plugins or any real bells and whistles so long as I have my parity and can keep that box running along without upgrades.
-
Good to know, thanks! I’ll dig into threads on that now. Timing wise, are the SASLP cards such an issue that I need to fix them before I run my next parity check / disk upgrade? Regardless of disk failure, I was planning on upgrading a random disk in this tower next week anyway. Also, I’m an idiot on 12/13. Just saw that in my screenshot of the webgui now.
-
This just got weird. I turned the tower back on to get a temperature read on all the drives, and now Disk 13 is disabled but Disk 12 looks fine? Edit: yeah, this is weird. Now both 12 and 13 are showing a pass on SMART overall health tests in the Dashboard menu despite 13 being disabled. I’m just going to power down for safety’s sake until I hear some ideas on concrete next steps from here. I don’t have a replacement drive ready to go, but I should have one soon. Attaching new diagnostics. tower-diagnostics-20190418-2344.zip
-
Just had a disk go disabled when I was writing to an unrelated disk (same share folder on both disks, though; hardly any read/writes on the disabled disk since the system was last booted up a couple of days ago, just noticed it disabled when it threw up 2 error messages a little while ago). My instinct is to replace it, but the lack of writes made me think something may be up, and since it's been close to 2 months since my last parity check (was planning on one this weekend), I'd like to put the disk back in for at least a parity check before I upgrade it to a 6TB as planned anyway. Before pulling diagnostics and shutting the system down, I checked the dashboard data and unraid wasn't able to pull any SMART data at all. Is this a giant red flag that the disk is totally dead and I shouldn't even bother the FAQ process of clearing the disabled slot's ID data with an array start missing the disk, and a second start with the disabled disk reinstalled? Somewhat related but not directly: is there a "best practices" guide anywhere on how to keep an eye on potentially failing disks? I'm planning to upgrade quite a few in the next month or so, and I'd rather upgrade ones that I know are leaning towards death if there's a solid way to predict which are heading that way beyond obvious SMART reallocation or error numbers. tower-diagnostics-20190418-2316.zip
-
Drive Clearly Hurting in Non-Corr ParityChk; Run Correcting or Replace Now?
wheel replied to wheel's topic in General Support
Yeah, the age alone has had this disk on my "watch list" for awhile now. If the errors are related to my docker.img being on the problem drive, does that change my stance on the risks of running a correcting parity check vs just replacing the drive now? -
Drive Clearly Hurting in Non-Corr ParityChk; Run Correcting or Replace Now?
wheel replied to wheel's topic in General Support
Diagnostics attached; was just about to start the replacement / rebuild this morning, but I'll leave this here and wait til I get home again before messing with anything in case something in the log is throwing up flags I'm oblivious to with my limited knowledge. Thanks! EDIT: Just noticed my docker.img is sitting on the troubled disk (#8) somehow, instead of in the cache. Errors make more sense now since I hadn't been writing much of anything to that drive lately, but I've got a feeling I need to shift that file to my cache drive somehow. Going to research that process when I get home, too. tower3-diagnostics-20190301-1725.zip -
Figured I’d check in here before I embark on the current plan I have based on threads I’ve read so far: an old disk in my array is showing the Orange Triangle in its dashboard status with reported uncorrect: 1, and my monthly non-correcting parity check is almost past that drive’s maximum terabyte position with 310 sync errors detected. It’s running hot at 51 C and heating the drives nearby it as well. From what I can tell, my choices are basically roll the dice either way. If I run the correcting parity check to fix the 310 sync errors, the whole drive could die during that second round (I’m still not 100% sure it’ll survive this one, but the drive should spin down in an hour or so when the check moves on to the higher capacity drives exclusively). If I replace the drive, whatever errors I’m sitting on right now will be rebuilt into the replacement drive, which isn’t great, but feels way better than risking losing the entire drive’s worth of data. Nothing added recently is irreplaceable, but the drive as a whole would be a huge pain to repopulate. So despite the sync errors on this parity check, based on what I’ve read, I’m making an educated gamble and planning to throw the replacement drive in there and start a build tomorrow morning when this parity check completes. If I’m absolutely misreading the risks in either approach and should run another correcting parity check no matter what, I’d greatly appreciate anyone warning me off my current path!
-
Seagate 8TB Shingled Drives in UnRAID
wheel replied to garycase's topic in Storage Devices and Controllers
So last month, I started having some issues writing to certain 8TB drives, but never took note of which specifically since no parity errors ever popped up before or after checks. I was looking into adding more 8TBs to a 19-disk array this week when I realized I’ve been adding ST8000DM004-2CX188s left and right over the past couple of years. SIX disks in a nineteen-disk array (not counting parity) are SMR drives (one is ST8000AS). Some have been going for years with decently intense read use and no real issues now, but reading this thread has me kind of freaking out about the possibility of multiple SMR drives failing simultaneously. Instead of looking to expand, which I still really need to do, I’m now wondering if I’m better off using my next 3-4 HD purchases to replace some of these 8TB SMR drives before I even try swapping some 4 or 6TB drives out with 8TBs. If I’ve made it this far without any failing (three pre-shuck preclears on each drive, too), is there any safe way to stress-test each SMR drive individually and maybe figure out which should be replaced first - or, ideally, if some look like they’ll be more reliable than others, which can stay in safely for awhile, so I don’t need to immediately replace 4 and just leave those 8TBs lying around to eventually replace the SMR 8TB “slot” whenever it inevitably fails? Whole situation feels wasteful, but that’s on me for continuing to buy these drives without looking here for guidance each time... Any help or ideas would be greatly appreciated! -
Amazingly enough, I think things are back to normal. Disk 5 appeared to rebuild correctly (spot-check on a few files seems to confirm) and parity check's only a few minutes away from completion with no issues. Thanks again, johnnie.black! Now I'm off to research which stable build of unraid that supports long-term syslog recording is a good fit for my current needs and upgrade before I do anything else - maybe get to the bottom of that self-shutoff issue that way. Damn glad I didn't lose a couple disks' worth of data getting there!
-
OK, AHCI set, disabled drive replaced, ready for rebuild. In an abundance of caution, I'm posting the boot syslog in case there's anything weird. I'll start the rebuild in a few hours if nobody flags anything. johnnie.black in particular, thank you for all of your very specific help with this! syslog-2017-05-24.txt
-
Sounds like a plan. Just checked SMART reports on all other drives and didn't see anything weird except for the non-response from 5 and 10. Possibly tricky question: either my controller has always been in IDE mode or UnRaid somehow changed it for me (I definitely haven't messed with that setting in the BIOS at any time); if I need to change that setting, is there a way to do so from UnRaid, or do I need to hook a monitor up and change it myself through BIOS before UnRaid boots?


