

SomeRandomSod
-
Posts
20 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by SomeRandomSod
-
Haven't got around installing it yet but a big ty @ich777 for your reactivity ! Satisfactory dedicated servers barely announced & you already on it TY !
-
[6.9.0] Shares disappeared and an unclean shutdown through GUI
SomeRandomSod commented on eagle470's report in Stable Releases
IMO if you want stability, roll back to 6.8.3 if you can, it works beautifully if you don't need the new multiple cache pools feature. It's what I did after a few bugs and instability under 6.9. You'll just need to recreate the cache since the setup files for the cache have been moved between 6.8.3 and 6.9. -
[6.9.0] Write errors since 6.9 update - disk disabled
SomeRandomSod posted a report in Stable Releases
Write errors across multiple disks since updating to 6.9 Appeared for the first time during the night after installation (see below, logs included in that post) Then today new errors on another disk leading to the device being disabled by UNRAID. Both disks are ST8000VN004, through Broadcom / LSI SAS2008. Forced to reverse back to 6.8.3 and rebuild array. NB : had no issues at all with disk spin up or down -
Multiple errors on < 1yo SeaGate 8TB HDD since 6.9 upgrade
SomeRandomSod replied to SomeRandomSod's topic in General Support
Can confirm, it disabled one of my disks today. Reverted back to 6.8.3 and rebuilding parity now. Hopefully this will be fixed pretty soon, I really needed those multiple pools -
U using hardware encoding? If so you need to install the nvidia drivers plugin (CA) first Also, not urgent (ie : Server crash, data loss, or other showstopper).
-
Multiple errors on < 1yo SeaGate 8TB HDD since 6.9 upgrade
SomeRandomSod replied to SomeRandomSod's topic in General Support
Thanks. Quick question, is this more of a "technical" error or is there an actual chance of data loss? -
Multiple errors on < 1yo SeaGate 8TB HDD since 6.9 upgrade
SomeRandomSod replied to SomeRandomSod's topic in General Support
Ty for the answer, is this to do with the 6.9 update? If so I'll probably just roll back, my unraid server is a good 10h drive away and to switch the ports would be a pain. -
Hello all, Today I saw on my server in the /Main tab 896 errors on one of my hard drives. I narrowed down these errors to 01h30 on the 03/03/2021. 1h30 of the first Wednesday of the month is when I run my monthly parity check, so it was during the start of the parity check that the errors popped up. The errors concern disk 1. In the logs this repeats multiple times : The device is relatively new, less than a year old. It's a 8TB Seagate Ironwolf drive. I set an extended SMART test to run, seems to be stuck at 10% for the last 2h or so. I attached the logs to this post. Any help is appreciated, Regards, George. tower-diagnostics-20210304-1325.zip
-
[Support] SpaceinvaderOne - Macinabox
SomeRandomSod replied to SpaceInvaderOne's topic in Docker Containers
Just to rebound off this @SpaceInvaderOne, I did this multiple times and with 0 doubt renamed the disk (as you do in your video tutorial) but it still shows up in the way the previous person showed. It somehow returns to this screen even though I name the disk "Big Sur". Using method 2 btw for install (not sure what difference it makes). At the end of the installation process, it retakes the correct name though -
[Support] selfhosters.net's Template Repository
SomeRandomSod replied to Roxedus's topic in Docker Containers
I'm having issues setting the "openldap" container up. Firstly the certificate issues (shared with letsencrypt), but that's sorted. Main issue now is slapd not starting 5fd381ba daemon: listen(ldap://XXXXX:389, 5) failed errno=98 (Address already in use) Seems to be related to this issue : https://github.com/osixia/docker-openldap/issues/252 This is driving me crazy EDIT : Resolved by removing HOSTNAME variable from template Also, for others wanting to set this up, you can run into certificate issues where the container says to share volumes between LETSENCRYPT and OPENLDAP. It's a pain, easy fix is : set the LDAP SSL Certificate Variable to : /mnt/user/appdata/swag/etc/letsencrypt/ Then the 3 above variables need setting to : live/DOMAIN.com/cert.pem live/DOMAIN.com/privkey.pem live/DOMAIN.com/fullchain.pem -
Unraid Forum 100K Giveaway
SomeRandomSod replied to SpencerJ's topic in Unraid Blog and Uncast Show Discussion
Best thing is defo the VM support, it's amazingly well done. I'd love to see an integrated nginx reverse proxy, not having to use a docker but having it built in, ready to go and easy to configure ! -
@bastl I'm so retarded, forgot that the driver version I had was for my 1060 I used for testing the IOMMU capabilities (to be sure the issue was the GPU) ! Downloaded the correct version of the drivers and they installed perfectly Thanks a ton for your help it all seems to be working great now
-
Thanks for the advice ! I did as you requested and it's somewhat better, I can use the 550ti as primary GPU and it's now outputting to a monitor from that HDMI port so it's progress ! However I can't at all get the 550ti to show up in device manager, it's obviously working (I've got a monitor hooked up to it !) but it's not showing up. Just shows "Microsoft Basic Display Adaptor". I cannot install drivers for it either since the OS does not detect the card so Nvidia just says it cannot continue because it can't find compatible hardware. Any advice?
-
Hey guys, I've been browsing the forums and various youtube and online tutorials but still cannot get my GTX 550Ti to passthrough to my VM. I can boot the machine ok with that card passed through, it shows up as functional and good both in GPU-z & in device manager (no error 43, no nothing, just says all is good). The issue is that after about 30s or so the machine fully locks down & my remote session is terminated. The 4 cores assigned are then pinned to 100% for the indefinite future. During this "crash" I get no syslog error, no VM error in the logs, nothing. I really have no idea how to sort this since I don't seem to be getting any error messages I can google. Other things to note : I'm using a bios I dumped from the card with my main PC (older card so don't need to modify header). The card is working ok on my main PC. I can pass through a 1060 no problem, with no crashes & no issue, with identical XML (except card & bios location ofc). Only the 550Ti is causing me issues. Tried both PCIE slots on my MOBO. Tried turning Hyper-V off (? read it somewhere, changes nothing). I'm connecting using Microsoft RDP. If I use VNC as primary and GTX550ti as secondary I still get the same crash and everything just freezes (no BSOD, nothing). Something that seems important : my default XML config with my GTX550ti only allows me one good boot, once it has inevitable crashed the VM will still launch, but gets stuck on some sort of 100% CPU pin that eventually settles down but allows me no access. The logs are still good during this second weird boot. The only way to get my GTX550ti back into a VM without a full server reboot is setting it a secondary GPU with either iGPU as primary or VNC, but it will also crash after 30s. After a HARD server reboot I can start up (only once) my VM again with 550 as primary GPU. I cannot for the life of me be able to get some sort of HDMI output from the card when the VM is launched, I can remote in no problems, but a monitor plugged into the card's HDMI port shows no input (?) Running the whole thing on an i7 3770 (non K), both HVM: Enabled and IOMMU: Enabled in unRAID GUI. Both diagnostics and XML can be found attached to this post. Any help or pointers would be greatly appreciated. tower-diagnostics-20190713-0826.zip xml for windows VM.txt
-
I'm running 6.6.7 and it seems the syslog feature is not available with your plugin, but also not available in the Settings tab (available as of 6.7). Could do with an easy way of tailing syslog but can't seem to be able to until I either upgrade to 6.7 or find some other solution
-
(SOLVED) UNRAID 6.6.6 crashes, can't seem to find the issue
SomeRandomSod replied to SomeRandomSod's topic in General Support
Good to know thank you ! I'll look into it if I'm still getting issues ! -
(SOLVED) UNRAID 6.6.6 crashes, can't seem to find the issue
SomeRandomSod replied to SomeRandomSod's topic in General Support
UPDATE : Tried removing my old ram & keeping only the new ram & seems to have solved the issue. A Memtest86+ pass lead me to believe that the RAM was OK but evidently not ! -
Hey guys, My UNRAID server, ever since I set it up just seems to have random crashes every 3 days or so. It becomes unresponsive over the web, over SSH, and plugging a monitor in to the back just gives no output. It's still physically running though, ie. I can hear the disks spin, the fans on etc. but no noise of read & writes to the HDD's, just spinning idle. I ran the troubleshooting plugin to no avail. And this morning as I got up I saw it had crashed overnight and was hoping to get some telling logs from the advanced troubleshooting mode, but I can't see much in them, they just abruptly end when it crashed this morning at around 6:10 AM. This is concordant with the time my router says it was last on (cf. attached photo) It doesn't seem to be heat related, it's well cooled & the crashes don't seem to be happening under load. Also ran 2 passes of Memtest86+ that came back with 0 errors. Attached you will find the tail log, and the syslog. Any help would be greatly appreciated. Regards, George NB : My setup is the following : Intel i7 3770 at clock speeds ASUS P8H77-M PRO motherboard (cg8270 variant) 14GB of DDR3 RAM (initial 2+4GB at 1666MHz, just added another 2x4GB at 1333MHz recently)(note the crashes were happening before I added the new RAM). 2 x 3TB Seagate NAS drives 2 x 250GB SSD for cache FCPsyslog_tail.txt syslog.txt
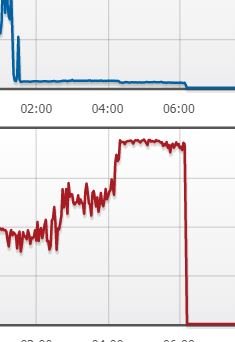
-
You're perfect thank you @Squid❤️
-
Hey ! I'm currently having the same issue, with other plugins that download from raw.github.com After a quick search github haven't acknowledged the issue yet however multiple tweets (dating from up to about 2-3h ago) confirm this. Everyone is getting "Error 503 Backend unavailable, connection timeout". Soooo, just need to wait for github to fix the issue. Regards,


