

mcrommert
-
Posts
39 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by mcrommert
-
-
doublechurch-diagnostics-20240216-1849
I downloaded the update for 6.12.8 and when i tried to reboot the server to finish the upgrade it hung on syncing filesystems and wont shutdown or reboot
-
So far my logs are a lot quieter - just NUT warnings and the random segfault from plex transcoder
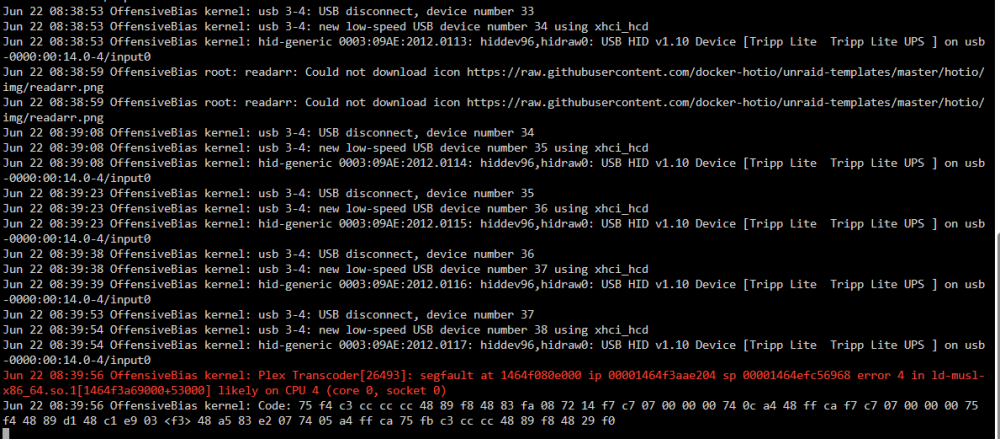
-
Will do - i also saw the macvlan warning - i had been seeing some syslog activity regarding macvlan but not having seen that warning i originally dismissed it
It also did not show up in common issues - but i switched to ipvlan
Will let you know what i see -
On 6/19/2023 at 8:02 AM, JorgeB said:
Reboot and run another scrub, if you still see the errors and the files are not there possibly best to backup and re-format the pool.
Okay so I got rid of the errors but for whatever reason when I went back to 6.12 the parity needed to be rebuilt…no issue
over the last three days the server has hard crashed about 10 hours after boot while rebuilding the parity twice now and both times all containers have dropped and the webui and ssh is inaccessible
as I have taken 12.1 now I need to revert somehow back to 6.11 where I didn’t have these issues
-
Yes - it showed these two (it scrolled too fast to take a screenshot)
But i had already deleted them4 hours ago, JorgeB said:Syslog should show the corrupt file(s)
-
1 hour ago, JorgeB said:
Look in the syslog for the corrupt file(s), delete/restore from backup then run another scrub.
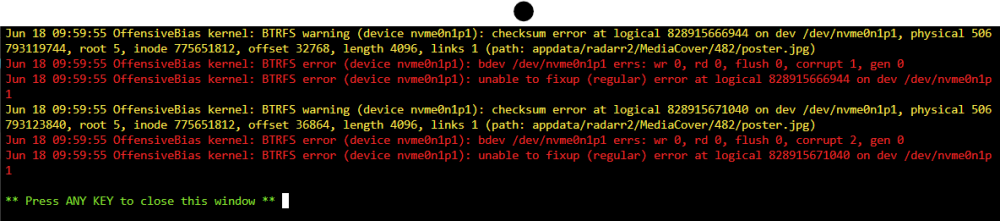
So i deleted this file over smb (actually i deleted the whole folder) ran scrub again and still this errors the same -
Will do
also panic restored back to 6.11.x
-
ran this from the other cache not mounting thread
btrfs rescue zero-log /dev/nvme0n1p1
And then i ran a scrub
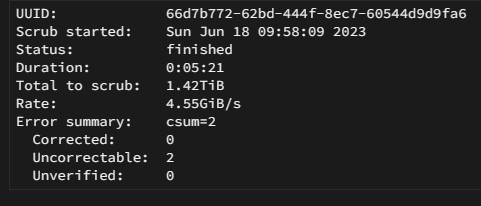
-
Literally exactly the same thing happened to me in exactly the same way
-
So i updated yesterday to 6.12 - today i noticed that my dockers weren't running - Had a "Unraid service failed to start" - rebooted the server and had to dirty shutdown as it wouldn't shut down
When it booted docker started with no containers - and now the cache drive has "Unmountable: Unsupported or no file system"
This is the logJun 18 09:24:49 OffensiveBias kernel: nvme0n1: p1
Jun 18 09:24:49 OffensiveBias kernel: BTRFS: device fsid 66d7b772-62bd-444f-8ec7-60544d9d9fa6 devid 1 transid 3904928 /dev/nvme0n1p1 scanned by udevd (914)
Jun 18 09:25:43 OffensiveBias root: [092543] system.php:1187 @ loop: Scanning: N:0:0:1 Node: /dev/nvme0n1
Jun 18 09:26:31 OffensiveBias emhttpd: MS1PC5ED3ORA3.2T_S2T7NA0J601609 (nvme0n1) 512 6251233968
Jun 18 09:26:31 OffensiveBias emhttpd: import 31 cache device: (nvme0n1) MS1PC5ED3ORA3.2T_S2T7NA0J601609
Jun 18 09:26:32 OffensiveBias emhttpd: read SMART /dev/nvme0n1
Jun 18 09:26:48 OffensiveBias emhttpd: /sbin/btrfs filesystem show /dev/nvme0n1p1 2>&1
Jun 18 09:26:49 OffensiveBias emhttpd: devid 1 size 2.91TiB used 1.64TiB path /dev/nvme0n1p1
Jun 18 09:26:49 OffensiveBias emhttpd: shcmd (81): mount -t btrfs -o noatime,space_cache=v2 /dev/nvme0n1p1 /mnt/cache
Jun 18 09:26:49 OffensiveBias kernel: BTRFS info (device nvme0n1p1): using crc32c (crc32c-intel) checksum algorithm
Jun 18 09:26:49 OffensiveBias kernel: BTRFS info (device nvme0n1p1): using free space tree
Jun 18 09:26:49 OffensiveBias kernel: BTRFS info (device nvme0n1p1): enabling ssd optimizations
Jun 18 09:26:49 OffensiveBias kernel: BTRFS info (device nvme0n1p1): start tree-log replay
Jun 18 09:26:49 OffensiveBias kernel: BTRFS error (device nvme0n1p1): incorrect extent count for 1095761920; counted 4528, expected 4521
Jun 18 09:26:49 OffensiveBias kernel: BTRFS: error (device nvme0n1p1) in btrfs_replay_log:2409: errno=-5 IO failure (Failed to recover log tree)
Jun 18 09:26:49 OffensiveBias root: mount: /mnt/cache: can't read superblock on /dev/nvme0n1p1.
Jun 18 09:26:49 OffensiveBias kernel: BTRFS error (device nvme0n1p1: state E): open_ctree failed
Wondering what i can do - really really want to restore as i don't have super up to date backups -
same this no longer works
-
i just kept restarting my container until it worked - glad to see i'm not the only one having this issue
-
So mine says joined and does not error out - but it never shows up in the zerotier interface to approve
Anyway to pull the name of this one so i can whitelist it manually in the zerotier interface?EDIT: When i change to bridge it changes to online but still doesn't work
Under host it says
200 info xxxxxxxxx 1.6.2 OFFLINE -
Well like the last rc - you still can't set the alarm temp for cache (at least) drives
-
-
It basically looks on my install like --allow-other is not functioning correctly all of a sudden - i can even do backup/restore backups to google drive no issue - but all my containers have lost their ability to read the files
Edit: https://forum.rclone.org/t/issue-with-allow-other-in-beta/18133
-
Okay here's where it sits - in terminal at /mnt/disks/Google everything is mounted correctly and can be seen - when i go to share the folder to a container in edit it shows all the subfolders just like you would expect
In any of the containers or smb share - it sees nothing and has nothing contained in it
I have force unmounted the folders and deleted them before remounting using rclone mount - same issue and it doesn't resolve anythingEDIT: My sync script for rclone also continues to run with no issues
-
Sorry i didn't respond - that fixed the issue - i had updated ud but i hadn't yet done a reboot.
Thanks for the help
-
 1
1
-
-
Sooooo....not quite sure what happened but realized today my rclone using google drive wasn't working - it wasn't mounted. Turns out it complaining that here are files in the mount directory - i have been running sync jobs constantly - but i'm not sure why this is happening that its writing to the mount directory. Anyways, any tips for clearing the folder so i can once again mount, as i'm not finding an easy way to delete the files that are there
EDIT: I can see the files and folders if in terminal i ls them - they don't exist at all if i try to mount to smb or any container
-
-
I had a major power outage and unfortunately i've overloaded my ups so it didn't shut down the server in time before the ups power ran out. So after the outage i booted back up and of course it was doing a parity check - but also had strange status next to array status i have never seen. After the array check i rebooted again but it is still there. I haven't seen any other issues so I am wondering how to resolve this

-
17 minutes ago, rix said:
I am afraid "eject" will not work from within docker for your external drive. You need to find an alternative and replace the eject command in ripper.sh
Strange - I did a different dvd and it seemed to work
will look for another solution
-
So for ripper i'm getting eject issues - the disc rips - it moves the files to finished - says eject and never does and then just keeps ripping the disc over and over again
I see this in the log
eject: tried to use `devtmpfs' as device name but it is no block device
eject: unable to find or open device for: `/dev/sr0'I have done a reboot to my unraid server - i'm using an external usb dvd drive
Edit: here is my devices
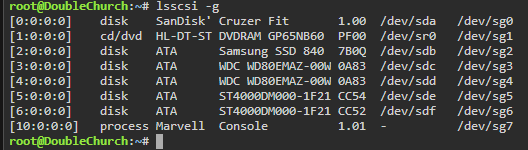
-
3 hours ago, CHBMB said:
If you're using this with GPU passthrough
<config> <!-- Client Control --> <fold-anon v='true'/> <!-- Folding Slot Configuration --> <gpu v='true'/> <!-- HTTP Server --> #Following allows access from local network <allow v='192.168.0.0/24'/> <!-- Remote Command Server --> #Change password for remote access <password v='PASSWORD'/> <!-- User Information --> #Change Team Number and Username if desired. Currently folding for UnRAID team! <team v='227802'/> <!-- Your team number (Team UnRAID is # 227802)--> <user v='chbmb'/> <!-- Enter your user name here --> <passkey v=''/> <!-- 32 hexadecimal characters if provided (Get one here: http://fah-web.stanford.edu/cgi-bin/getpasskey.py)--> <!-- Web Server --> #Following allows access from local network <web-allow v='192.168.0.0/24'/> <!-- CPU Use --> <power v='medium'/> <!-- Folding Slots --> <slot id='0' type='CPU'/> <slot id='1' type='GPU'/> </config>
Thank you so much for this - got mine working - now just waiting for an assignment







Server hung on reboot to install 6.12.8
in General Support
Posted
Had to hard power cycle and boot up again
ran till this morning at 745 am and went unresponsive and lost all the apps
hard rebooting again
going to revert the update