

Datapotomus
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Datapotomus
-
Routing issue with persistence problems after upgrade
Datapotomus replied to Datapotomus's topic in General Support
Ok, so I sort of figured it out. If I turn off bridging on eth1, and eth2 then leave it on, on eth0, then bridge them all together it seems to work correctly. # Generated settings: IFNAME[0]="br0" BRNAME[0]="br0" BRSTP[0]="yes" BRFD[0]="0" BRNICS[0]="eth0 eth1 eth2" PROTOCOL[0]="ipv4" USE_DHCP[0]="no" IPADDR[0]="192.168.1.253" NETMASK[0]="255.255.255.0" GATEWAY[0]="192.168.1.1" DNS_SERVER1="192.168.1.254" DNS_SERVER2="192.168.1.1" DNS_SERVER3="1.1.1.1" USE_DHCP6[0]="yes" DHCP6_KEEPRESOLV="no" SYSNICS="1" If someone has a better way to do this than bridging ports that aren't even plugged in I'm all ears. However, it does look like doing this does seem to persist after reboot. -
Routing issue with persistence problems after upgrade
Datapotomus replied to Datapotomus's topic in General Support
# Generated settings: IFNAME[0]="br0" BRNAME[0]="br0" BRSTP[0]="no" BRFD[0]="0" BRNICS[0]="eth0" PROTOCOL[0]="ipv4" USE_DHCP[0]="no" IPADDR[0]="192.168.1.253" NETMASK[0]="255.255.255.0" GATEWAY[0]="192.168.1.1" DNS_SERVER1="1.1.1.1" DNS_SERVER2="192.168.1.1" DNS_SERVER3="8.8.8.8" USE_DHCP6[0]="yes" DHCP6_KEEPRESOLV="no" IFNAME[1]="br1" BRNAME[1]="br1" BRNICS[1]="eth1" BRSTP[1]="no" BRFD[1]="0" PROTOCOL[1]="ipv4" USE_DHCP[1]="no" IPADDR[1]="192.168.1.252" NETMASK[1]="255.255.255.0" GATEWAY[1]="192.168.1.1" IFNAME[2]="br2" BRNAME[2]="br2" BRNICS[2]="eth2" BRSTP[2]="no" BRFD[2]="0" PROTOCOL[2]="ipv4" USE_DHCP[2]="no" IPADDR[2]="192.168.1.251" NETMASK[2]="255.255.255.0" GATEWAY[2]="192.168.1.1" SYSNICS="3" Here you go. Like I said, the most baffling thing about it. Is that it worked just fine with the previous version of unraid when I downgraded. As well as naturally working before the upgrade. -
Hey All, I've been running into an issue after upgrading to 6.7.2 . Where br2 becomes the default route. The issue with this is that I don't have anything plugged into br2. I am currently only using br0, because it is my 10G link. br1, and br2 are only 1G links. So, I really don't want to use them. I was able to fix this by modifying the route table manually. However, if I modify it manually after a reboot it reverts right back. The weird thing is also if I downgrade back to 6.6.7 I don't have this issue. So, my primary question is what is the best option for making the br0 route persistent across reboots?
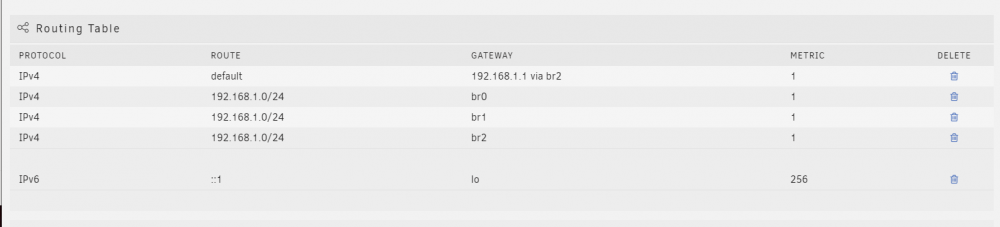
-
I figured the issue out a little later. Posting the solution now. I needed to make a copy of the serverconfig.xml, and named it serverconfig_new.xml. Then I changed it in the docker configuration page GAME_PARAMS to -configfile=serverconfig_new.xml -logfile 7DaysToDie_Data/output_log.txt $@. After that 7DTD worked just fine. Thanks for the work on the container.
-
7DTD docker log.txtHey all I'm running into an issue with the 7DTD container. I got it started with no issue.I shut down the container. I make the changes to the serverconfig.xml then start it back up. As soon as I start it back up my changes seemed to get revered back to the default. I did make sure that the files saved, by exiting, and opening it back up, and it does save, but the second I start the container back up it wipes the file. Has anyone else run into this, and figured out a way to not have it wipe?
-
Just wondering if anyone is currently running strongSwan on their unraid boxes, and if so. How they set it up. Ikev2 is considerably faster for my VPN solution, and I would like to switch to it, but just wondering if anyone else did it before I start reinventing the wheel.
-
Ok somehow the .img file got lost after the upgrade... Don't know why, but once I specificed a file instead of a directory it appears to be working correctly.
-
Hey guys, Running into an issue after upgrading to Unraid 6.4.1 I attempted to start the VM manager, and it refuses to start. I took a look at the log, and this is what came up. Feb 22 13:16:07 NAS emhttpd: Starting services... Feb 22 13:16:13 NAS ool www[6538]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:16:13 NAS emhttpd: req (21): cmdStatus=apply&csrf_token=**************** Feb 22 13:16:13 NAS emhttpd: Starting services... Feb 22 13:16:14 NAS emhttpd: shcmd (603): /usr/local/sbin/mount_image '/mnt/cache/system/libvirt/' /etc/libvirt 5 Feb 22 13:16:14 NAS root: /mnt/cache/system/libvirt/ is not a file Feb 22 13:16:14 NAS emhttpd: shcmd (603): exit status: 1 Feb 22 13:16:41 NAS ool www[6537]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:16:41 NAS emhttpd: req (23): cmdStatus=apply&csrf_token=**************** Feb 22 13:16:41 NAS emhttpd: Starting services... Feb 22 13:17:21 NAS ool www[7069]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:17:21 NAS emhttpd: req (24): cmdStatus=apply&csrf_token=**************** Feb 22 13:17:21 NAS emhttpd: Starting services... Feb 22 13:17:26 NAS ool www[6538]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:17:26 NAS emhttpd: req (25): cmdStatus=apply&csrf_token=**************** Feb 22 13:17:26 NAS emhttpd: Starting services... Feb 22 13:17:26 NAS emhttpd: shcmd (674): /usr/local/sbin/mount_image '/mnt/cache/system/' /etc/libvirt 1 Feb 22 13:17:26 NAS root: /mnt/cache/system/ is not a file Feb 22 13:17:26 NAS emhttpd: shcmd (674): exit status: 1 Feb 22 13:19:50 NAS login[7586]: ROOT LOGIN on '/dev/pts/1' Feb 22 13:20:56 NAS ool www[7411]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:20:56 NAS emhttpd: req (27): cmdStatus=apply&csrf_token=**************** Feb 22 13:20:56 NAS emhttpd: Starting services... Feb 22 13:20:56 NAS emhttpd: shcmd (703): /usr/local/sbin/mount_image '/var/lib/libvirt/images' /etc/libvirt 1 Feb 22 13:20:56 NAS root: /var/lib/libvirt/images is not a file Feb 22 13:20:56 NAS emhttpd: shcmd (703): exit status: 1 Feb 22 13:21:03 NAS ool www[7411]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:21:03 NAS emhttpd: req (28): cmdStatus=apply&csrf_token=**************** Feb 22 13:21:03 NAS emhttpd: Starting services... Feb 22 13:21:03 NAS emhttpd: shcmd (732): /usr/local/sbin/mount_image '/var/lib/libvirt/images' /etc/libvirt 1 Feb 22 13:21:03 NAS root: /var/lib/libvirt/images is not a file Feb 22 13:21:03 NAS emhttpd: shcmd (732): exit status: 1 I attempted to change the directory to point directly to my cache drive, and delete the file so that way it could rebuild it, and neither methods seem to work. Same thing when attempting to change the directory to allow it to build. Feb 22 13:17:26 NAS emhttpd: req (25): cmdStatus=apply&csrf_token=**************** Feb 22 13:17:26 NAS emhttpd: Starting services... Feb 22 13:17:26 NAS emhttpd: shcmd (674): /usr/local/sbin/mount_image '/mnt/cache/system/' /etc/libvirt 1 Feb 22 13:17:26 NAS root: /mnt/cache/system/ is not a file Feb 22 13:17:26 NAS emhttpd: shcmd (674): exit status: 1 Feb 22 13:19:50 NAS login[7586]: ROOT LOGIN on '/dev/pts/1' Feb 22 13:20:56 NAS ool www[7411]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:20:56 NAS emhttpd: req (27): cmdStatus=apply&csrf_token=**************** Feb 22 13:20:56 NAS emhttpd: Starting services... Feb 22 13:20:56 NAS emhttpd: shcmd (703): /usr/local/sbin/mount_image '/var/lib/libvirt/images' /etc/libvirt 1 Feb 22 13:20:56 NAS root: /var/lib/libvirt/images is not a file Feb 22 13:20:56 NAS emhttpd: shcmd (703): exit status: 1 Feb 22 13:21:03 NAS ool www[7411]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:21:03 NAS emhttpd: req (28): cmdStatus=apply&csrf_token=**************** Feb 22 13:21:03 NAS emhttpd: Starting services... Feb 22 13:21:03 NAS emhttpd: shcmd (732): /usr/local/sbin/mount_image '/var/lib/libvirt/images' /etc/libvirt 1 Feb 22 13:21:03 NAS root: /var/lib/libvirt/images is not a file Feb 22 13:21:03 NAS emhttpd: shcmd (732): exit status: 1 Feb 22 13:26:58 NAS ool www[7932]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:26:58 NAS emhttpd: req (31): cmdStatus=apply&csrf_token=**************** Feb 22 13:26:58 NAS emhttpd: Starting services... Feb 22 13:26:58 NAS emhttpd: shcmd (765): /usr/local/sbin/mount_image '/mnt/user/perm/VMs/libvrt/' /etc/libvirt 1 Feb 22 13:26:58 NAS root: /mnt/user/perm/VMs/libvrt/ is not a file Feb 22 13:26:58 NAS emhttpd: shcmd (765): exit status: 1 Feb 22 13:27:03 NAS ool www[7932]: /usr/local/emhttp/plugins/dynamix/scripts/emhttpd_update Feb 22 13:27:03 NAS emhttpd: req (32): cmdStatus=apply&csrf_token=**************** Feb 22 13:27:03 NAS emhttpd: Starting services... Feb 22 13:27:03 NAS emhttpd: shcmd (798): /usr/local/sbin/mount_image '/mnt/user/perm/VMs/libvrt/' /etc/libvirt 1 Feb 22 13:27:03 NAS root: /mnt/user/perm/VMs/libvrt/ is not a file Feb 22 13:27:03 NAS emhttpd: shcmd (798): exit status: 1 Is there some way I can create maybe via the command line to get it to work correctly?
-
I checked out nvidia docker github here: https://github.com/NVIDIA/nvidia-docker Just wondering if anyone else has attempted running docker with a GPU. I was planning on possibly spinning up some mining docker containers, and thought it would be better than running pass-through in a VM with a GPU. Just also wondering if anyone has attempted to install invidia drivers locally as well.
-
How to set Additional Flags in the Web UI during start?
Datapotomus replied to Datapotomus's topic in Docker Engine
Thanks. That worked. -
How to set Additional Flags in the Web UI during start?
Datapotomus replied to Datapotomus's topic in Docker Engine
Sorry if I wasn't clear enough. What I am trying to say is how do you set additional options via the webui that you would need to run after the container. Like they have in the example. How would I pass the bolded parameters to the container from the webUI. ethereum/client-go --fast --cache=512 -
Can someone tell me how to set additional flags in the web UI for docker containers that go after the run. An example I am trying to run is this: docker run -d --name ethereum-node -v /Users/alice/ethereum:/root \ -p 8545:8545 -p 30303:30303 \ ethereum/client-go --fast --cache=512 However, when I add them to the extra parameters option in the web UI it looks like it tries to run them before the container. I receive this error when attempting to put them in the extra parameters field. root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name="ethereum-node" --net="host" -e TZ="America/New_York" -e HOST_OS="unRAID" -e "TCP_PORT_8545"="8545" -e "TCP_PORT_30303"="30303" -v "/mnt/user/perm/docker_apps/ethereum-node/":"/root":rw "--cache=512" ethereum/client-go unknown flag: --cache See 'docker run --help'. The command failed. So it looks like the extra parameter feild seems to set it before hand not after like I need it.
-
I'm attempting to run a docker container for monero CPU mining. The container wasn't specifically built for Unraid. I seem to be having issues keeping the container running. I ran it on my desktop locally first, and am having no issues. Would someone tell me what I might be doing wrong to not keep the container from executing and to continue to hash? Here is is the output on windows. C:\Users\Admin>docker run tpruvot/cpuminer-multi -a cryptonight -o stratum+tcp://xmr-us-east1.nanopool.org:14444 -u 47PQKDzaHeScKU4en6pzBLbZfFoKo9A3MiGRWqoHwWCza33MyEXjpJ73LAWuNaoTNb6uiLGv6hYci2wBk4qW7FVgPtqugiF -p x -t 4 ** cpuminer-multi 1.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-04-07 23:38:54] Using JSON-RPC 2.0 [2017-04-07 23:38:54] CPU Supports AES-NI: YES [2017-04-07 23:38:54] Starting Stratum on stratum+tcp://xmr-us-east1.nanopool.org:14444 [2017-04-07 23:38:54] 4 miner threads started, using 'cryptonight' algorithm. [2017-04-07 23:38:54] Stratum difficulty set to 90001.6 [2017-04-07 23:39:06] CPU #0: 5.91 H/s [2017-04-07 23:39:06] CPU #2: 5.87 H/s [2017-04-07 23:39:08] CPU #3: 5.15 H/s [2017-04-07 23:39:08] CPU #1: 5.14 H/s However, when I attempt to run the same container on unraid it pulls the cointainer, but it appears that it just stops running after executing. It doesn't start hashing. Like the screen above. root@NAS:~# docker run tpruvot/cpuminer-multi -a cryptonight -o stratum+tcp://xmr-us-east1.nanopool.org:14444 -u 47PQKDzaHeScKU4en6pzBLbZfFoKo9A3MiGRWqoHwWCza33MyEXjpJ73LAWuNaoTNb6uiLGv6hYci2wBk4qW7FVgPtqugiF -p x -t 4 ** cpuminer-multi 1.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-04-07 23:45:52] Using JSON-RPC 2.0 [2017-04-07 23:45:52] CPU Supports AES-NI: YES [2017-04-07 23:45:52] Starting Stratum on stratum+tcp://xmr-us-east1.nanopool.org:14444 root@NAS:~# I also attempted to start it with the web UI with the same results. Here is all the output the log had from the webUI. ** cpuminer-multi 1.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-04-07 23:45:52] Using JSON-RPC 2.0[0m [2017-04-07 23:45:52] CPU Supports AES-NI: YES[0m [2017-04-07 23:45:52] Starting Stratum on stratum+tcp://xmr-us-east1.nanopool.org:14444[0m I also attempted in detached mode with the same result. root@NAS:~# docker run -d tpruvot/cpuminer-multi -a cryptonight -o stratum+tcp://xmr-us-east1.nanopool.org:14444 -u 47PQKDzaHeScKU4en6pzBLbZfFoKo9A3MiGRWqoHwWCza33MyEXjpJ73LAWuNaoTNb6uiLGv6hYci2wBk4qW7FVgPtqugiF -p x -t 4 c91e9fe890ba962a5ffb08974f786e3711e391ba0bf9621dfe3fed48ed3c6466 root@NAS:~# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 94503566d514 linuxserver/plexpy "/init" 3 weeks ago Up 3 weeks 0.0.0.0:8181->8181/tcp plexpy c406e028023f linuxserver/plex "/init" 3 weeks ago Up 6 hours plex 570e87cfd30e gfjardim/crashplan "/sbin/my_init" 3 months ago Up 3 weeks CrashPlan root@NAS:~# docker logs --follow -f c91e9fe890ba962a5ffb08974f786e3711e391ba0bf9621dfe3fed48ed3c6466 ** cpuminer-multi 1.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-04-07 23:51:00] Using JSON-RPC 2.0 [2017-04-07 23:51:00] CPU Supports AES-NI: YES [2017-04-07 23:51:00] Starting Stratum on stratum+tcp://xmr-us-east1.nanopool.org:14444 root@NAS:~#
-
rveillerot/mediaelch has a docker repo that looks to be similar to what filebot does, but I haven't ever used it.
-
Building Packages for Sysstat and Datadog
Datapotomus replied to Datapotomus's topic in General Support
Thanks. Can I use the defaults they have documented or are the specific things that need to be changed? -
I guess I would add to the question with are there like a settings.xml or another configuration file you could set up https with? I agree with the VPN comment, because I wouldn't open up my NAS externally. I would still like my NAS to be configured for https. I could see small offices that might also like this functionality.
-
Hey All, I would like to test out using datadog locally as an install. However, one of their prereqs is to use the sysstat package. I was looking around for a recent systat package for slackware, but I haven't found one. I was looking into building one myself, but I don't have much experience in building slackware packages. I found the following link http://www.slackwiki.com/Building_A_Package , and thought that I would try it, but I don't know if there is anything specific I have to do for unraid to build packages, or if I could just accept the defaults like it is currently in the doc. I also don't know if in fact that datadog agent would work. I just thought I would try it out, and see if I could get it to work for Unraid.
-
[CONTAINER] CrashPlan & CrashPlan-Desktop
Datapotomus replied to gfjardim's topic in Docker Containers
Limetech is currently working on a container that should be better supported than this one. The main thing I don't like about using a VM, is the additional overhead in resources that using another OS requires. -
Are there any plans on you guys putting making crashplan available through the limetech templates? I saw that there is a repo, but it doesn't look like it has been published to the hub yet.
-
[CONTAINER] CrashPlan & CrashPlan-Desktop
Datapotomus replied to gfjardim's topic in Docker Containers
I have submitted a ticket to code 42 requesting that they change the link to a more generic "latest" link. That way if you do attempt to create a new container you should be able to just download the latest version, and not have to do a download then an upgrade. This would still require a change on the source repository. However, the link would only have to be changed one more time in the source repository. -
[CONTAINER] CrashPlan & CrashPlan-Desktop
Datapotomus replied to gfjardim's topic in Docker Containers
I'm running into an issue after the update as well. I attempted to even clear out my crashplan docker configuration directory, and start with a new container and image. It just now sits on "upgrading" when opening the GUI in windows. -
Wondering about the same thing. Seems to be happening again.
-
Yeah, I would run the balance as soon as you rebuild the pool before you put anything on it.
-
I'm really thinking it's coming down to issues with drive 2.
-
I have the same thing with the partition formats. I don't think that is an issue. Ok, so going back to one of my questions. Did you attempt to do a balance (click the balance button on the cache page)? If you do a balance it should reread the metadata, and set things so they dedupe already written extra copies of the data. The balance rereads all data, and metadata, and writes it back out.

