

SuperDan
-
Posts
20 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by SuperDan
-
-
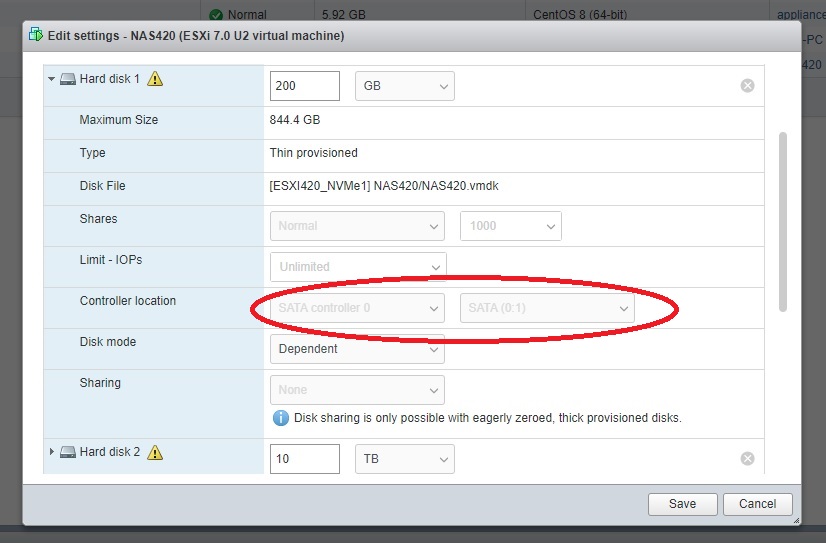
I am doing the same thing and used this guide.
The only way I got Unraid to see the vmdk disks were to set them as SATA.
-
32 minutes ago, guy.davis said:
Welcome! I think that is an open PR for the Plotman project, but you could give it a test to see what happens. Might error out about being unable to move the file.
Thanks for the reply!
I ended up setting the tmp2 directory to the plots directory. After the job completed I checked the logs and confirmed it just renamed the file after it was done. So, same effect I guess as pointing temp to plots.
-
 1
1
-
-
Quick question.
If I set my plots directory and plotting directory to the same physical location when its done plotting will it just rename the temp plot to the completed plot file or will it try to copy it?
-
6 minutes ago, doron said:
Thanks - great stuff!
Other reports also begin to confirm that this is probably controller dependent.
Do you happen to have the PCI IDs of these two?
For the running one, you can obtain it via "lspci -vnnmm".
For the one you removed - well, if it is connected to another machine...
Sorry, I did not record the ID for the one I removed.
Unfortunately these are the Mini Mono cards that require a proprietary PCI storage slot on Dell servers and I do not have another server I can plug the old one into.
output of lspci -vnnmm
Slot: 03:00.0
Class: Serial Attached SCSI controller [0107]
Vendor: Broadcom / LSI [1000]
Device: SAS2308 PCI-Express Fusion-MPT SAS-2 [0087]
SVendor: Dell [1028]
SDevice: SAS2308 PCI-Express Fusion-MPT SAS-2 [1f38]
Rev: 05
NUMANode: 0
IOMMUGroup: 18-
 1
1
-
-
8 minutes ago, SimonF said:
Thanks for the update please feedback if any errors happen in the future. Are all the drives you are using HITACHI
Testing with SEAGATE as parity drive performs as expected with Manual spin down via command.
Will do.
Yes, all of the SAS drives are HITACHI.
-
Just a follow up.
I replaced the DELL H310 LSI MegaRAID SAS 2008 controller with a DELL H710 LSI 9207-8i P20 flashed with LSI IT mode firmware version P20 (20.00.07.00).
After 18 hours of running and doing some other tests the drives spin up/down as they should and no errors or red x drives.
So, at least in my case replacing the controller fixed it.
-
30 minutes ago, doron said:
Hmm. Certainly a possibility, yes.
Currently it's second on my list of potential causes, only because the OEM manual of the Seagate described the drive's behavior in the Standby_Z state (this is what we're using to spin the drive down), and it explicitly stated that the drive will require an init op to spin up again. This is in contrast with the HGST/WD SAS drives, which (explicitly) specify that in the same state the drive is ready to spin back up on next I/O.
The manual for your Hitachi is silent about this - does not say either - but the 04-11 sense makes me think it does it like the Seagate.
You'd think that standards would be standards, and the drive behavior following a standard SAS/SCSI operation would be standard... go figure.
It could still be the controller, the above is just my current thinking.
Hmm, this has given me the motivation I needed to replace the DELL controller with one that is flashed with the LSI firmware. Been meaning to do it for a while now.
I just ordered it and when I install it Ill report back if anything changed.
-
1
-
-
Something I just noticed, the other user having this problem is using an HP controller
HP H220 LSI 9205-8i 9207
And I am using a DELL H310 LSI MegaRAID SAS 2008
Maybe proprietary firmware on the HBA may have something to do with it?
Just throwing it out there.
-
1 hour ago, doron said:
Thanks very much for this.
Aha. That's the infamous/dreaded 02-04-11, same as we've seen on the Seagate. Will have to exclude this series as well 😞
A different drive? Was something else happening at the same time?
Maybe a differnet drive(s) since my cache drives are SATA SSD's.
May as well add these drive as well since the are HITACHI HUC106060CSS600 drives rebranded to Netapp drives but still suffer the above problem,
NETAPP X422_TAL13600A10
NETAPP X422_HCOBD600A10
-
1
-
-
1 hour ago, doron said:
Thanks. So basically you're saying the result in your case is not consistent? Some (most?) of the time they do spin back up but at times they get the read errors?
Could you paste syslog lines from the time of such error that red-x-ed a drive?
Actually I found more log entries for one of the drives that went red x:
Oct 7 09:31:30 unNAS SAS Assist v0.6[36184]: spinning down slot 17, device /dev/sdz (/dev/sg26)
Oct 7 09:32:46 unNAS kernel: sd 2:0:23:0: [sdz] tag#24 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s
Oct 7 09:32:46 unNAS kernel: sd 2:0:23:0: [sdz] tag#24 Sense Key : 0x2 [current] [descriptor]
Oct 7 09:32:46 unNAS kernel: sd 2:0:23:0: [sdz] tag#24 ASC=0x4 ASCQ=0x11
Oct 7 09:32:46 unNAS kernel: sd 2:0:23:0: [sdz] tag#24 CDB: opcode=0x28 28 00 00 00 00 40 00 00 08 00
Oct 7 09:32:46 unNAS kernel: blk_update_request: I/O error, dev sdz, sector 64 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:32:46 unNAS kernel: md: disk17 read error, sector=0
Oct 7 09:32:46 unNAS kernel: sd 2:0:8:0: Power-on or device reset occurred
Oct 7 09:32:51 unNAS kernel: sd 2:0:23:0: [sdz] tag#8 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s
Oct 7 09:32:51 unNAS kernel: sd 2:0:23:0: [sdz] tag#8 Sense Key : 0x2 [current] [descriptor]
Oct 7 09:32:51 unNAS kernel: sd 2:0:23:0: [sdz] tag#8 ASC=0x4 ASCQ=0x11
Oct 7 09:32:51 unNAS kernel: sd 2:0:23:0: [sdz] tag#8 CDB: opcode=0x2a 2a 00 00 00 00 40 00 00 08 00
Oct 7 09:32:51 unNAS kernel: blk_update_request: I/O error, dev sdz, sector 64 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:32:51 unNAS kernel: md: disk17 write error, sector=0 -
1 hour ago, doron said:
Thanks. So basically you're saying the result in your case is not consistent? Some (most?) of the time they do spin back up but at times they get the read errors?
That is correct.
I had to re enable the plug to get the log entries.
This time 2 drives red x'd on me.
The only entry I saw related to those drives are:
Oct 7 09:32:46 unNAS kernel: blk_update_request: I/O error, dev sdz, sector 64 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:32:46 unNAS kernel: md: disk17 read error, sector=0
Oct 7 09:32:51 unNAS kernel: blk_update_request: I/O error, dev sdz, sector 64 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:32:51 unNAS kernel: md: disk17 write error, sector=0Oct 7 09:41:37 unNAS kernel: blk_update_request: I/O error, dev sdu, sector 586549720 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:41:37 unNAS kernel: md: disk15 read error, sector=586549656
Oct 7 09:41:37 unNAS kernel: blk_update_request: I/O error, dev sdu, sector 586549720 op 0x1:(WRITE) flags 0x800 phys_seg 1 prio class 0
Oct 7 09:41:37 unNAS kernel: md: disk15 write error, sector=586549656
Oct 7 09:41:37 unNAS kernel: blk_update_request: I/O error, dev sdu, sector 64 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 0
Oct 7 09:41:37 unNAS kernel: md: disk15 write error, sector=0 -
HITACHI HUC106060CSS600 A430 Failure
Read errors when spun down and trying to wake back up.
They do spin backup up but have had random (3 times) drives with red x.
Array is 20 drives of the above type.
-
Maybe there is some kind of hardware requirement that needs to be met before it will work?
I tried this one my Dell 720XD that has a stock Perc h310 controller (not re flashed with another vendors firmware) and it worked.
# sg_start -rS /dev/sdh
# smartctl -i /dev/sdh
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.7.8-Unraid] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org=== START OF INFORMATION SECTION ===
Vendor: HITACHI
Product: HUC106060CSS600
Revision: A430
Compliance: SPC-4
User Capacity: 600,127,266,816 bytes [600 GB]
Logical block size: 512 bytes
Rotation Rate: 10020 rpm
Form Factor: 2.5 inches
Logical Unit id: 0x5000cca0214c3e74
Serial number: PPWAXW5B
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Thu Jul 30 13:25:40 2020 PDT
device is NOT READY (e.g. spun down, busy)# dd of=/dev/null if=/dev/sdh
# smartctl -i /dev/sdh
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.7.8-Unraid] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org=== START OF INFORMATION SECTION ===
Vendor: HITACHI
Product: HUC106060CSS600
Revision: A430
Compliance: SPC-4
User Capacity: 600,127,266,816 bytes [600 GB]
Logical block size: 512 bytes
Rotation Rate: 10020 rpm
Form Factor: 2.5 inches
Logical Unit id: 0x5000cca0214c3e74
Serial number: PPWAXW5B
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Thu Jul 30 13:27:36 2020 PDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled -
On 2/11/2020 at 9:08 AM, bland328 said:
I somehow missed that, so I did not. Thanks for the tip!
I'll give it a try when I have a few free minutes and report back.I tried it and got an immediate failure of:
Backupfolder not setI don't have time at the moment to look into that deeply, but I did find food for thought at https://forums.urbackup.org/t/urbackup-mount-helper-test-backupfolder-not-set/5271.
Yeah it does that because it requires a folder and file to be created named:
/etc/urbackup/backupfolder
Inside the file backupfolder you put the path to where urbackup stores it's backup ie: /mnt/user/Urbackup
-
On 1/18/2020 at 5:05 PM, bland328 said:
I installed btrfs-progs within the binhex-urbackup container (# pacman -Fy && pacman -S btrfs-progs) as an experiment, but my next incremental backup still didn't create the BTRFS subvolume I was hoping for.
On the UrBackup Developer Blog, it says that "[e]very file backup is put into a separate sub-volume" if "the backup storage path points to a btrfs file system and btrfs supports cross-sub-volume reflinks."
So, admitting I'm more than a touch out of my depth here, perhaps: 1) Unraid btrfs doesn't support cross-sub-volume reflinks for some reason, or 2) I shouldn't expect it to work from within a Docker container accessing a filesystem that's outside the container, or 3) ...something else.
Im curious if you tried running the test script "urbackup_snapshot_helper test" from the container console to verify that Urbackup can use the BTRFS snapshot feature?
-
I noticed the original docker image supports BTRFS in privileged mode. https://hub.docker.com/r/uroni/urbackup-server
But this image seems to be missing BTRFS tools. Was this on purpose because of some issue or could it be added?
Thanks much!
-
Looks like there is another update?
-
+1 For this!
It would cool if there was an "least used space" option like MergerFS with the lus policy.
That way data would be evenly distributed across all drives regardless of the drive sizes.



[Support] Bacula-Server
in Docker Containers
Posted
I have been testing this Bacula container for a few days now as a replacement for my current backup solution and so far I think I like it.
One thing I rely on heavily is ZFS deduplication for my backups and I was looking for how to get that working properly in Bacula.
I found some documentation that basically says that a bacula-aligned plugin needs to be installed for dedup to work with Bacula volumes.
Deduplication Optimized Volume
I don't know anything about building docker containers but is that something that could be added to this docker image?
But regardless, thanks for the great job on getting this docker put together.
-dan