

trott
-
Posts
140 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by trott
-
frankly speaking, I have test both with plex docker, both has no issue to finish scanning my 400 movies
-
actually even for the appdata on cache, there will be 2 setup 1. map directly to /mnt/cache/xxx 2. map to user share /mnt/user/xxx with setup "use cache disk" only by testing on this 2 setup, we might be able to isolate if the issue is fuse related or not
-
basically when you access a HDD in sleep mode, it take too long to wake it up, so the read/write request will return a time out error, similar as below https://github.com/zfsonlinux/zfs/issues/4713
-
I'm using 9207-8i now, I can say it will add about 45s to the boot process btw, if you want to spin down the HDD, then it might have issues; when I move the data to array, I might the HDD using UD. I notice the HDD will spin down automatically, but when you wake it up, syslog will have some read error, after google-fu, it seems it take too long to wake the HDD.
-
you can install bind in NerdPack
- 1 reply
-
- 1
-

-
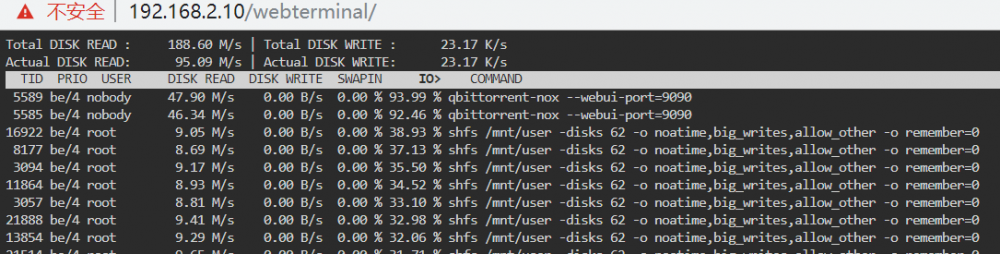
I just find out that the Total disk read is almost double of the actual disk read in iotop at any time, is it normal in unraid?
-
Again, are you guys are 100% sure this only impact the sqlite DB? I don't have cache now, so I download to array directly using qbittorent, recently I found MakeMAV failed to remux some movies, I have thought it might be movie issue, but I have a force recheck on those torrents today, it happaned they are not 100% complete I have no prove to say it is unraid issue, but it is not one torrent, but serveral, and I never have this issue before. I'm not happy on this beause I don't know if there is any other file are also corrpution during the moving to unaid, I have no way to check without the checksum Frankly speaking, I think unraid should pull back the 6.72 until they fixed this issue.
-
frankly speaking, I don't get it why pihole will cripple you speed, it just a dns server; try run dig google.com in CLI to see if there is any issue
-
no, you cannot with only one GPU, you need 2 GPU
-
personally I think the whole purpose of disk pool /array solution is you don't need to care about which disk your data actual on
-
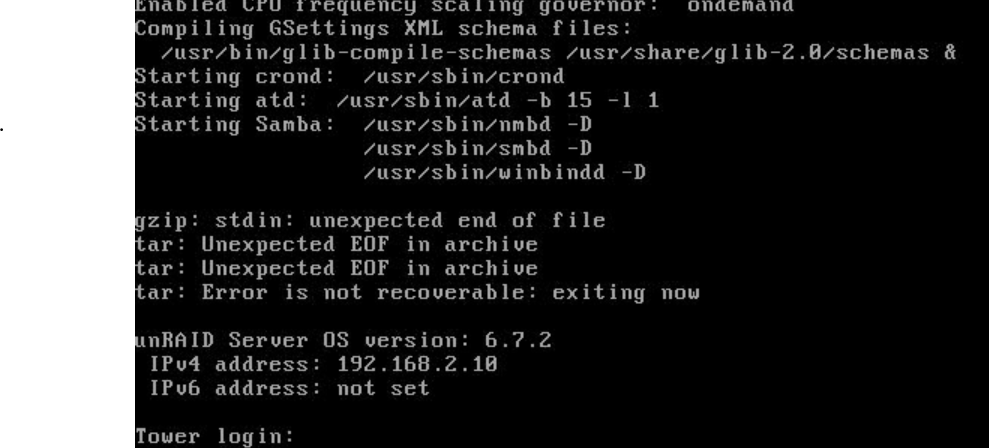
during the boot, I find below error on the screen, but cannot find it in log, not sure what's cause the issue tower-diagnostics-20190830-1809.zip
-
(v6.7.2) Looking for an automated file manager
trott replied to Crlaozwyn's topic in General Support
you might check Flexget -
maybe you should check the temperature of your HBA card, those card running very hot in normal case, not sure if it will cause some issue
-
SSD Trim Support for Unassigned Devices.
trott replied to pXius's topic in Storage Devices and Controllers
install user.script, schedule running fstrim -a -v should be enough -
I think it might be the same issue as below
-
try to add pcie_aspm=off to syslinux, this trick my AER error
-
one HDD in array cannot detected, what's the proper step to hanle this
trott replied to trott's topic in General Support
I connect the HDD to sata port, it seems it can be detected, but when I reassign this HDD to array, it start to rebuild -
I received a notification this morning that one of my disk has read error. so I login to the server and found out one HDD(disk3) in the array cannot be detected by unraid anymore; I reboot the server, even the HBA card( 9207-8i) cannot detect the HDD on the posting, I will connect this HDD to onboard SATA port to confirm it is the HDD issue or HBA card issue/cable issue. but if it is the HDD issue, I'd like to confirm the next step to ensure I don't mass up things. 1. Can I start the array and continue running docker with that HDD missing in array? 2. To replace the HDD, is preclear the HDD and assign the new HDD to disk3 is all I need to do?
-
Need Help Identifying Unknown Network Traffic and Process
trott replied to Rock G's topic in General Support
using NerdPack to install the iftop, it should tell you where you network traffic goes -
when you change the setting Tunable (enable NCQ) to yes in disk setup and click apply, and it will do nothing to enable NCQ, I have to manually change the queue_depth to 31 in CLI startArray=yes&spindownDelay=0&spinupGroups=no&defaultFormat=2&defaultFsType=xfs&shutdownTimeout=90&poll_attributes=600&queueDepth=0&nr_requests=128&md_num_stripes=4096&md_sync_window=2048&md_sync_thresh=2000&md_write_method=0&changeDisk=Apply&csrf_token=**************** Aug 22 17:09:51 Tower emhttpd: shcmd (9335): echo 128 > /sys/block/sdf/queue/nr_requests Aug 22 17:09:51 Tower emhttpd: shcmd (9336): echo 128 > /sys/block/sde/queue/nr_requests Aug 22 17:09:51 Tower emhttpd: shcmd (9337): echo 128 > /sys/block/sdb/queue/nr_requests Aug 22 17:09:51 Tower emhttpd: shcmd (9338): echo 128 > /sys/block/sdd/queue/nr_requests Aug 22 17:09:52 Tower emhttpd: shcmd (9339): echo 128 > /sys/block/sdc/queue/nr_requests Aug 22 17:09:52 Tower kernel: mdcmd (95): set md_num_stripes 4096 Aug 22 17:09:52 Tower kernel: mdcmd (96): set md_sync_window 2048 Aug 22 17:09:52 Tower kernel: mdcmd (97): set md_sync_thresh 2000 Aug 22 17:09:52 Tower kernel: mdcmd (98): set md_write_method 0 Aug 22 17:09:52 Tower kernel: mdcmd (99): set spinup_group 0 0 Aug 22 17:09:52 Tower kernel: mdcmd (100): set spinup_group 1 0 Aug 22 17:09:52 Tower kernel: mdcmd (101): set spinup_group 2 0 Aug 22 17:09:52 Tower kernel: mdcmd (102): set spinup_group 3 0 Aug 22 17:09:52 Tower kernel: mdcmd (103): set spinup_group 4 0
-
[6.7.x] Very slow array concurrent performance
trott commented on JorgeB's report in Stable Releases
I want to report that enable NCQ help me a lot on this issue, my MAKEMKV got 35M/s compare with 2.3M/s before in the same situation. but unraid seems has the bug to enable NCQ, even if you setup Tunable (enable NCQ) to yes in disk setting, the queue_depth is still 1, I have to manually setup queue_depth in CLI for each disk like below echo 31 > /sys/block/sdf/device/queue_depth -
[6.7.x] Very slow array concurrent performance
trott commented on JorgeB's report in Stable Releases
I will downgrade to 6.6.x to test, I only got 2.3M/s when using MakeMKV to renux a file, total disk read/write is only 1xM/s, iotop shows below, I don't think it is normal -
Hi guys, just want to confirm if this unknow bug will also impact the normal file we written to array?
-
I'm new to unraid, I have tried it about 15 days, running emby, sonarr without issue. but I do not use array or cache, I put appdata on the SSD mounted with UD
-
syslog flooding with AER: Corrected error received: 0000:01:00.0
trott replied to trott's topic in General Support
it is my onboard NIC card, it cannot be moved; but after a bit search, I add pcie_aspm=off to syslinux, it seems did the trick, no such error for 20 hours after reboot



