

Mizerka
-
Posts
79 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Mizerka
-
-
time to bump a dead thread;
just swapped over from sm x9 to h11 motherboard, and came across this issue, interestingly enough if left alone it will eventually boot to cli but im no unix expert. so went back to bios disabled eufi and stuck it in legacy, disabled all boots aside from usb hdd and usb pen xxMYUSBxxxx, ended up bricking my kvm since i disabled superio serials and onboard vga, few minutes passed and finally saw unraid output as its mounting disks from HBA. and works fine now, surely I'll never need kvm or bios for a while... at least nvme onboard works fine.
-
cool, and actually spoke too soon, server practically hangs and logs are spamming;
2022-09-21 23:24:54,316 DEBG 'plexmediaserver' stdout output:
busy DB.Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.
Sqlite3: Sleeping for 200ms to retry busy DB.enabling verbose on server itself gives off these errors;
Held transaction for too long (/data/jenkins/server/3534229725/Library/MetadataItemClustering.cpp:114): 15.620000 seconds
CLEAR FILTERS AND JUMP TO CONTEXT
and it's spamming those every 10s or so.
gonna disable scheduled jobs and restart for now and see if that does anything, maybe do the cleanup jobs from server itself
edit;well I let it run for a bit but seems to have hung again, this time with no logs, it's eating up about 0.5cpu and 120mb ram so it's doing something but... not sure, might just leave it overnight. nevermind finished mid sentence, so far... looks okay, will enable scans again and clean up bundles, just doing library scan of a massive one I have, so far it looks okay.
-
had same issue on :latest as well, killed the container, forced update again and it started up fine, it was throwing this before.
Critical: libusb_init failed
-
Hey, thanks for your work;
for a about a week now (not bothered to look at it closely), delugevpn docker in unraid would fail to start, stating dns resolution errors, it'd loop through all external ip identifiers and dns resolutions until it times out eventually and starts webgui without external connection, despite it connecting to vpn (tested) and not stating any errors during it, looking at debug logs, nothing useful again other than dns resolutions failing, I tried swapping to CF, google and internal pihole with same results. It can ping external just fine from consoleThis started happening since 6.9 rc2 updateany ideas? let me know if you need logs/more info.
ignore me, removed .ovpn and .conf files and it just started to work. -
You still need to enable bifurcation on the right slot, you'll want to use 4x4x4x4 in most cases if you split 8x8 you can end up not seeing both depending on how card splits lanes internally. and your nvme won't get saturated over x4 pcie3 anyway.
For booting you'll need to use a custom bios. But if it's vmware just stick it on USB and it'll be fine.
-
 1
1
-
-
2 hours ago, aidenpryde said:
Just came across this thread as I'm looking to do some NVMe caching at some point here and don't want to use up multiple PCI-E slots.
Are you saying that you mod the BIOS first, then you upgrade to the official 3.4 BIOS?
Or does the official unmodded 3.4 BIOS allow PCI-E bifurcation?
I have a X9DR3-F which is different than yours I think, not that I think it matters in this case.
bios firmware is modded to allow for nvme boot, if you're only planning to use nvme for cache pool (like what I have), then you can use the official bios. I never bothered with nvme boot and also it's not needed for unraid since we boot from usb anyway.
after all this supermicro ended up adding the official bios to their download pages so you can get it legit from them if you don't trust my links etc.
-
1
-
-
just had a look, yeah 3.4 is on their site now, which is the same one I've been given. And yeah I found that it fixes the bifurcation issues in previous versions. even though there's no mention of it in any patch notes.
-
18 hours ago, justjosh said:
Where did you get this from? Have you tested it with the Asus Hyper M2 or some other card?
I have already sold off my Hyper M2 but if someone can confirm this works in particular with the M2 I don't mind getting a new one.
from Supermicro support, since then I've actually got a newer 3.4 stable, same link, subfolder "3.4 official", had some say they don't trust me or whatever, included email conversation from the tech in email.
Also yeah I ran 3.3 beta which worked flawlessly with m2 hyper x4, flashed to 3.4 as well without issues, 2 weeks uptime without issues so far, with each m.2 drive saturating 1.2gbps reads (sn750 1tb)
also not sure if it affects nvme, but these and samsung 250gb's I have tested don't break parity like some flash ssd's were reported to.
I will add the 3.4 nvme boot modded version as well, I don't need it but I know some do want the option.
-
On 12/11/2019 at 9:27 PM, justjosh said:
Hi all,
I currently possess a X9DRi-F board and a Hyper M.2 card but after extensive testing and research, it seems that it is impossible to make bifurcation work with this combination even though the BIOS clearly has such an option.
As a result, I have decided I would need to source for another motherboard. Everything else I have runs on the X9 infrastructure so it would be great if the suggestions were for X9.
I also need 3x x16 slots and 1x x8, preferably with the x16s spaced out as I am planning to install double slot width cards.
Alternatively, if anyone managed to make the Hyper M.2 card show 4 drives with the X9DRi-F, I would also love to hear about it.
Thanks!
confirmed working bios for x9dr3(i)-f, beta dated Feb'20, also including nvme modded for bootable nvme.
-
let's revive an old thread;
Can we have a global setting for this? and manual change through disk view be a manual override of the global? or at least have a multiple disk setting. having to click through 20+ is a pain.
-
17 hours ago, Dyon said:
Hello, by default every 300 seconds the container sends out a ping to one.one.one.one by default. If this domain is unreachable the container will shutdown, and normally automatically restart. This normally happens if the connection with the VPN is not working anymore.
Could you verify the following:
Click the jackettvpn Docker, select Edit, in the top right change to slider to Advanced View and check if Extra Parameters has the following:
`--restart unless-stopped`
This makes it so that the container automatically restarts if it goes offline when the domain is unreachable.
makes sense,
can confirm, --restart unless-stopped wasn't there, I've added now and will see how it behaves.
thanks
-
Hey, thanks for your work;
lately jacketvpn has been turning itself off quite often with error
2020-08-08 17:04:58.977161 [ERROR] Network is down, exiting this Docker
Is this just down to tun closing so jacket is forcing to shutdown?
-
okay, so I think I'm good now, ended up booting back into full array with md14 mounted, moved all data off of it without issues, then went back into maintenance and could now run -v, once complete I've started array again and seems good fine for last 20mins or so, crisis averted for now. if it didn't -v I'd probably -L and just reformat it if it corrupts the filesystem.
-
47 minutes ago, trurl said:
What did it actually say?
The -n (nomodify) flag means check but don't repair anything.
After looking around forums a bit more came across similar post,
mod advised to run against /dev/mapper/md# if drives are encrypted (all of mine are btw), then to -L it.
which spits out this output, same as webui
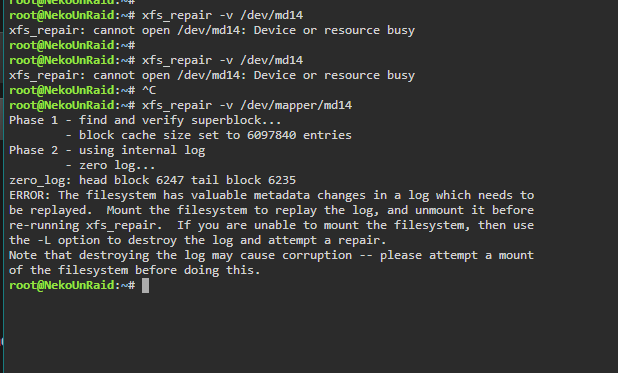
Clearly it wants me to run with -L but that sounds destructive? It's a 12tb mostly filled, I'd really hate to lose it, at this point I'd almost be better to remove it and let parity emulate it probably and move data around before reformatting and adding back to array?
-
also attached diagnostics if you want to have a look but doubt there's anything interesting in config side of this
-
1 minute ago, trurl said:
What did it actually say?
The -n (nomodify) flag means check but don't repair anything.
running webgui with a -v flag gives this output;
Phase 1 - find and verify superblock... - block cache size set to 6097840 entries Phase 2 - using internal log - zero log... zero_log: head block 6247 tail block 6235 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. -
1 minute ago, trurl said:
What version of Unraid are you running?
Version 6.8.3 2020-03-05 Stable afaik
-
8 minutes ago, trurl said:
Also, see this section on that same wiki page:
https://wiki.unraid.net/Check_Disk_Filesystems#Drive_names_and_symbols
okay, ye makes sense, so run it against md# instead, I've gone back to maintenance and I'm getting the errors in edit, md14 is saying drive busy and webui refuses to run beyond -n/-nv
I've tried to run repair, but it never got past saying magic number failed and trying to find secondary superblock
which outputs this if it helps
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... Metadata CRC error detected at 0x43c89d, xfs_bnobt block 0x3a381e28/0x1000 Metadata CRC error detected at 0x43c89d, xfs_bnobt block 0x74703c48/0x1000 btree block 1/1 is suspect, error -74 btree block 2/1 is suspect, error -74 bad magic # 0xdaa0086c in btbno block 1/1 bad magic # 0x2fdfba35 in btbno block 2/1 Metadata CRC error detected at 0x43c89d, xfs_cntbt block 0x3a381e30/0x1000 btree block 1/2 is suspect, error -74 bad magic # 0x419e48e9 in btcnt block 1/2 agf_freeblks 122094523, counted 0 in ag 1 agf_longest 122094523, counted 0 in ag 1 Metadata CRC error detected at 0x43c89d, xfs_cntbt block 0x74703c50/0x1000 btree block 2/2 is suspect, error -74 bad magic # 0xa8692ca5 in btcnt block 2/2 agf_freeblks 121856058, counted 0 in ag 2 agf_longest 121856058, counted 0 in ag 2 Metadata CRC error detected at 0x46ad5d, xfs_inobt block 0x3a381e38/0x1000 btree block 1/3 is suspect, error -74 Metadata CRC error detected at 0x46ad5d, xfs_inobt block 0x74703c58/0x1000 bad magic # 0x639e272e in inobt block 1/3 btree block 2/3 is suspect, error -74 bad magic # 0x796a2ce3 in inobt block 2/3 Metadata CRC error detected at 0x46ad5d, xfs_inobt block 0xaea85a78/0x1000 btree block 3/3 is suspect, error -74 bad magic # 0x15f1f03 in inobt block 3/3 sb_ifree 59, counted 44 sb_fdblocks 2926555418, counted 2681574888 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - agno = 20 - agno = 21 - agno = 22 - agno = 23 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 4 - agno = 3 - agno = 14 - agno = 22 - agno = 8 - agno = 9 - agno = 5 - agno = 6 - agno = 10 - agno = 12 - agno = 15 - agno = 16 - agno = 13 - agno = 17 - agno = 18 - agno = 2 - agno = 21 - agno = 7 - agno = 19 - agno = 20 - agno = 23 - agno = 11 No modify flag set, skipping phase 5 Inode allocation btrees are too corrupted, skipping phases 6 and 7 Maximum metadata LSN (904557511:-555599277) is ahead of log (1:6247). Would format log to cycle 904557514. No modify flag set, skipping filesystem flush and exiting. -
5 minutes ago, trurl said:
You can't repair the sdX device, and you shouldn't repair the sdX1 partition of a disk in the array, or you will invalidate parity. You must run it on the md# device.
If you do it from the webUI then it will do it correctly.
I see, the doc specifies either can be used, I'll try now with md# instead, to confirm if I want to run it from webui I should just change -nv to -v?
trying to run from webui now only displays this;
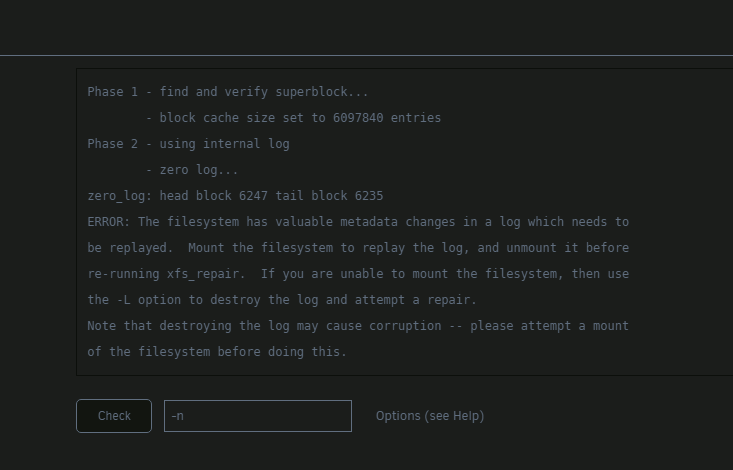
not allowing any actions
using md# also returns device is busy
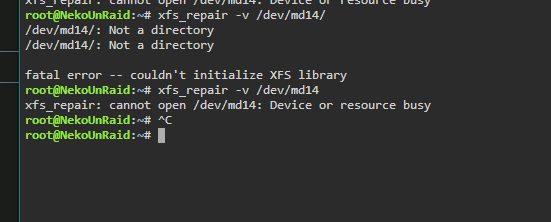
-
xfs_repair in webgui, after 2nd run of -nv said, "just start the array up bro, it'll be good", as doubtful as I was, I tried it and so far... it seems okay. but scrubbing btrfs cache as well just in case.
edit;
ye okay, spoke too soon.
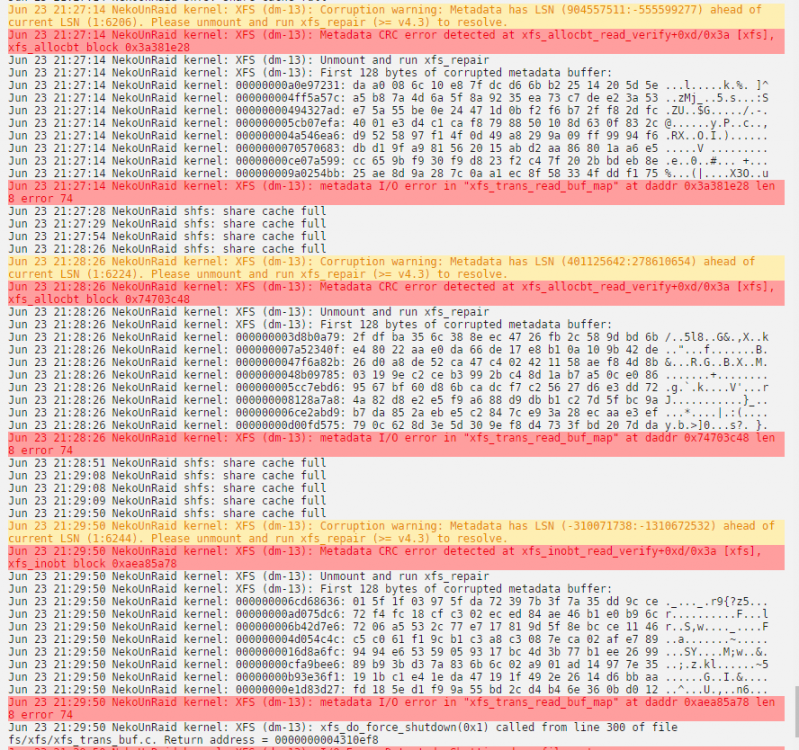
thoughts on best action? I'll try to unmount again and repair but doubt it'll work
-
So had some heat issues today, some disks hit 60c before I realised.
Anyway, I sorted but found some strange behaviour, but primary io write errors from smb, so loaded up logs and found a lot of issues. took array down and up again, no go. rebooted in maintainence and found disk14 reported xfs_check issues, but then after leaving it for a while and checking logs it's filled with below.
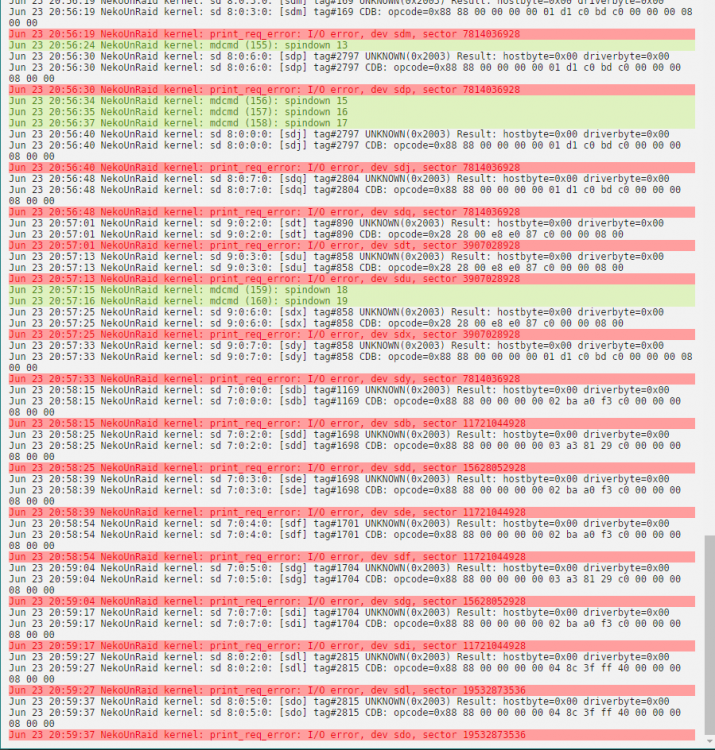
So.... how bad is it? looking at docs I should run xfs_check -V /dev/sdX ,which I tried with disk14 which was only one that actually reported issue in webgui using xfs check.
But that's been running for past 15mins trying to find 2ndary superblocks in filesystem
So, help please

-
28 minutes ago, ich777 said:
It will nothing happen because you have to input something and because it's a container it wouldn't work.
You can also create it on OSX and it will work.
Create a world on your windows machine named 'world' and with your preferred options, then i recommend deleting the whole container including the created directory in appdata.
Then redownload the container from the CA App wait for it to fully startup, then stop it and delte the two files in your Worlds folder and replace it with the 'world.wld' file generated from your windows machine.
Okay, ye so that worked, didn't know actual world name during generation mattered. got 3 instances running side by side now without issues. If you get some time it'd be nice to sort that downloading delay though, world is 2mb, but takes it good 10mins before it proceeds to extract it
-
1
-
-
Just now, ich777 said:
Yes because it's broken in the game itself when you specify it in the serverconfig.txt (and that's why i had to do it that way, otherwise I had to pull the container of the CA APP).
You must match the world to that name that is in the serverconfig.txt or you rename it in the serverconfig.txt.
Hmm, so they match otherwise as you said it'd complain about it missing, but still fails to starts, fwiw I'm generating local worlds on windows client. If I just copy it over it goes back to the same error as before, when run straight parameters from container instead of using -config x.txt I get that weird n world, d <number> delete world in log, left it for 30mins and nothing happened.
-
2 minutes ago, ich777 said:
I think there must be something wrong with the download of the world.
Have you generated the world with the same name as in the serverconfig.txt? It has to be the same!
That's likely because you've created the world with another name as in the serverconfig.txt and can't find it.
I have to look into it another day...
World generation still isn't working in any way, it only downloads it once if path is missing.
World I tried with was different name originally (just renamed file to match serverconfig.txt), I'll give that a try.







[Support] Crocs - Tube Archivist
in Docker Containers
Posted
since this is 1st google result, I just came across this, redist created appdata folders with weird settings, could probably force it with vars but ended up just going into terminal and changing user and group to nobody and letting them wrx. redist and es started up fine afterwards.