

Mizerka
-
Posts
79 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Mizerka
-
-
Guess who's back, back again
Array's dead, dead again.
I've isolated one of the cores after forced reboot, so now at least webgui is usable (I guess isolation to everything but unraid os? okay), despite every other core sitting at 100%. Dockers are mostly dead due to lack of cpu time, but sometimes respond back with a webpage or output. shares are working almost normally as well.
nothing useful in logs again.
After removing plugins one by one, array returned to normal after killing ipmi or temparature sensor plugins. so that's interesting that it'd brick unraid out of nowhere... oh well, we'll see tomorrow.
-
4 minutes ago, kocka said:
it`s for testing and it shod still work. if anybody has any other ideas pls post
sure, well I give up then, good luck.
only other thing in terms of config is you have disk shares force enabled, you're better of using user shares or leaving it on auto default. and mounting disk outside of array if that's what you need.
-
Quote
# Generated settings:
IFNAME[0]="br0"
BONDNAME[0]="bond0"
BONDING_MIIMON[0]="100"
BRNAME[0]="br0"
BRSTP[0]="no"
BRFD[0]="0"
BONDING_MODE[0]="1"
BONDNICS[0]="eth0"
BRNICS[0]="bond0"
PROTOCOL[0]="ipv4"
USE_DHCP[0]="yes"
DHCP_KEEPRESOLV="yes"
DNS_SERVER1="192.168.88.1"
DNS_SERVER2="193.231.252.1"
DNS_SERVER3="213.154.124.1"
USE_DHCP6[0]="yes"
DHCP6_KEEPRESOLV="no"
VLANS[0]="1"
SYSNICS="1"those dns servers are a bit weird, first is likely your router, but other 2 are public and weird, I'd change to local router only probably, this is given out by your dhcp, i.e. router, again, strange. one of them points to some random location in Romania.
and yeah ipv6 enabled so it picked up fe80::
QuoteDec 18 09:46:04 FTP ntpd[1663]: Listen normally on 3 br0 [fe80::1c20:77ff:fe46:fd3c%10]:123
should disable dhcp for something like unraid, it'll just cause you issues one day.
Comparing my config to yours, there's nothing wrong unraid side and it doesn't report issues either.
Make sure you have filesharing and discovery completely enabled
e;
Quoteyes i can whit my phone and windows 7 laptop
It will be windows 100%, unraid will use at least smb2 by default, so that's fine
-
Quote
MikroTik RB951G-2HnD
that looks retro
anyways, tried applying those changes?
since you can ping it and it echo's back then that's good enough, from here on, it'll be a layer 4 issue onwards, i'd still wager it's a microsoft service issue, got any other machines on network that can access this share btw?
also looking at logs briefly, you have nameserver set to 193.231.252.1, typo or is that some strange public resolver you use? doesn't actually respond on 53 by the looks.
-
4 minutes ago, Frank1940 said:
I went through your syslog and I am lifting out a section of it:
Dec 18 15:39:15 FTP root: Starting Samba: /usr/sbin/smbd -D Dec 18 15:39:15 FTP root: /usr/sbin/nmbd -D Dec 18 15:39:15 FTP root: /usr/sbin/wsdd Dec 18 15:39:15 FTP root: /usr/sbin/winbindd -D Dec 18 15:39:15 FTP emhttpd: shcmd (20608): smbcontrol smbd close-share 'FTP'
The first four lines are the normal starting of the SMB process. They occur whenever SMB restarts. The problem appears to be in this fifth line.
Dec 18 15:39:15 FTP emhttpd: shcmd (20608): smbcontrol smbd close-share 'FTP'
Googling smbcontrol smbd close-share is a command that apparently orders smbd to close the client connections to the named share (FTP in this case). Problem is that I don't have the foggiest idea what is generating this message.
I'm pretty sure that's the default behaviour when making changes to a share that's already deployed. it kills off connections and relies on client to reestablish it.
looking at my logs;
it's specifically ran when changing smb security settings;
below changing public to secure
Dec 18 23:00:18 NekoUnRaid root: Starting Samba: /usr/sbin/nmbd -D Dec 18 23:00:18 NekoUnRaid root: /usr/sbin/smbd -D Dec 18 23:00:18 NekoUnRaid root: /usr/sbin/winbindd -D Dec 18 23:00:18 NekoUnRaid emhttpd: shcmd (509): smbcontrol smbd close-share 'ssd' -
hmm those look fine, and you don't need dhcpv6 for ipv6 devices to work, apipa v4 169.254 is a pain to use, but ipv6 fixes that and can manage itself on networks without dns quite painlessly, win10 prefers it by default.
anyway, doubt it'll be it, but you can try disabling ipv6 on your client interface to force it on v4, but network discovery worked fine over v6 by the looks.
win+r
NCPA.CPL
default eth int, and untick ipv6.
also you don't have any firewalls/av in place that might prevent it? try disabling win firewall (temporarily if you actually use it)
e;
also make sure you have enabled discovery and filesharing on network/s (just add to all for now), found in network and sharing center.
-
can you ping it?
cmd
ping x.x.x.x
try hostname as well;
ping hostname.local
-
access it by ip and to root and not any shares, i.e.
\\192.168.0.200\
if you get prompted for creds, use your unraid user/root. if share is public, try and access it.
-
tried changing the unraid management port to something else?
cd /boot/config/
nano go
add -p to default below;
/usr/local/sbin/emhttp -p 8008 &
change 8008 to whatever unique on your host
-
 1
1
-
-
Hey,
bit of a strange one, been on and off upgrading and working on unraid (in middle of encrypting entire array), over last week it crashed twice on me, I say crashed, but it's actually sitting at 80-100% cpu usage across all cores which it never does (24 cores, only running few dockers) and even more interestingly it's running 100% ram.
Yesterday, I tried a few things like killing docker, force restarting, shutting downa array etc, but nothing worked, webui was somewhat usable and could console on to it as well.
output of top:
top - 19:23:29 up 22:10, 1 user, load average: 154.26, 151.66, 147.51
Tasks: 1062 total, 3 running, 1059 sleeping, 0 stopped, 0 zombie
%Cpu(s): 19.1 us, 4.9 sy, 0.1 ni, 7.8 id, 67.4 wa, 0.0 hi, 0.8 si, 0.0 st
MiB Mem : 96714.1 total, 520.3 free, 94856.5 used, 1337.3 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 223.3 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1809 472 20 0 153908 20228 0 D 501.0 0.0 301:48.74 grafana-server
1835 root 39 19 0 0 0 S 16.5 0.0 17:38.78 kipmi0
25784 root 0 -20 0 0 0 D 10.2 0.0 42:59.54 loop2
914 root 20 0 0 0 0 S 6.6 0.0 17:07.15 kswapd0
11948 root 20 0 3424 2308 1680 R 5.0 0.0 0:00.15 lsof
5922 root 20 0 5413656 61964 0 S 4.6 0.1 253:53.78 influxd
6737 root 20 0 175536 18744 0 S 3.0 0.0 283:15.09 telegraf
915 root 20 0 0 0 0 S 2.0 0.0 8:00.16 kswapd1
12001 root 20 0 0 0 0 I 2.0 0.0 1:44.95 kworker/u50:0-btrfs-endio
17414 root 20 0 0 0 0 I 1.7 0.0 0:10.87 kworker/u49:0-btrfs-endio
18371 root 20 0 0 0 0 I 1.7 0.0 0:36.69 kworker/u49:3-btrfs-endio
25464 root 20 0 0 0 0 I 1.7 0.0 0:06.19 kworker/u49:5-btrfs-endio
9124 nobody 20 0 150628 11848 6372 S 1.3 0.0 4:15.60 nginx
9652 root 20 0 0 0 0 I 1.3 0.0 0:33.14 kworker/u50:7-btrfs-endio
16159 root 20 0 0 0 0 I 1.3 0.0 0:27.58 kworker/u50:6-btrfs-endio
23079 root 20 0 0 0 0 R 1.3 0.0 0:39.64 kworker/u49:4+btrfs-endio
10860 root 20 0 0 0 0 I 1.0 0.0 0:03.74 kworker/u49:11-btrfs-endio
10955 root 20 0 0 0 0 I 1.0 0.0 0:02.17 kworker/u49:13-btrfs-endio
11390 root 20 0 9776 4396 2552 R 1.0 0.0 0:00.10 top
2533 root 20 0 0 0 0 I 0.7 0.0 0:20.58 kworker/u49:7-btrfs-endio
2621 nobody 20 0 7217200 113880 0 S 0.7 0.1 6:06.13 jackett
7894 root 22 2 113580 24708 19188 S 0.7 0.0 8:01.97 php
9093 root 20 0 283668 3948 3016 S 0.7 0.0 8:15.71 emhttpd
25333 root 20 0 1927136 120228 976 S 0.7 0.1 171:10.80 shfs
31883 nobody 20 0 4400376 491120 4 S 0.7 0.5 15:38.17 Plex Media Serv
147 root 20 0 0 0 0 I 0.3 0.0 0:29.49 kworker/14:1-events
936 root 20 0 113748 13228 7672 S 0.3 0.0 0:00.22 php-fpm
1662 root 20 0 36104 988 0 D 0.3 0.0 0:07.78 openvpn
1737 root 0 -20 0 0 0 I 0.3 0.0 0:02.95 kworker/12:1H-kblockd
2530 root 20 0 8677212 232344 0 S 0.3 0.2 1:09.19 java
2794 nobody 20 0 197352 51372 0 D 0.3 0.1 0:44.64 python
6629 root 20 0 0 0 0 I 0.3 0.0 0:27.33 kworker/8:2-events
7607 root 20 0 3656 232 196 D 0.3 0.0 0:00.01 bash
14099 root 20 0 33648 14988 52 D 0.3 0.0 0:13.68 supervisord
18350 root 20 0 0 0 0 I 0.3 0.0 0:42.51 kworker/u50:3-btrfs-endio
21018 nobody 20 0 3453756 581936 4 S 0.3 0.6 51:39.60 mono
21121 nobody 20 0 2477100 532884 4 S 0.3 0.5 8:34.30 mono
22859 root 20 0 0 0 0 I 0.3 0.0 0:12.78 kworker/u50:5-btrfs-endio-meta
25853 root 20 0 2649020 45064 19816 S 0.3 0.0 81:46.26 containerd
31808 root 20 0 76984 664 412 D 0.3 0.0 0:01.23 php7.0
32288 nobody 20 0 429092 1852 0 S 0.3 0.0 0:21.01 Plex Tuner Serv
32302 root 20 0 0 0 0 I 0.3 0.0 0:30.08 kworker/19:1-xfs-buf/md9
1 root 20 0 2460 1700 1596 S 0.0 0.0 0:13.40 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.07 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd
9 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
10 root 20 0 0 0 0 S 0.0 0.0 0:27.84 ksoftirqd/0
11 root 20 0 0 0 0 I 0.0 0.0 2:03.96 rcu_sched
12 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_bhClearly grafana is having some fun there managing 500% cpu (goes up to like 900% sometimes)
But even after trying to kill it, it doesn't work, by that I mean it refuses to die, even when force killing entire docker.
The only thing I can think of recently is that I've started to run some youtube-dl scripts as part of recent yt changes, to archive some channels, but that's hardly doing anything destructive imo, it does write some temp files then remuxes parts into single mkv's etc but that's about it, all done locally by another client as well.
Attached diagnostics, unraid running atm, but I'll probably kill it before end of the night.
Any help is appreciated.
-
happy bday
")
many more to come I hope.
-
1 hour ago, Squid said:
What I meant is that you can go from page 1 to 2, and it'll remember what you had checked off and install
My bad, didn't assume to try it, given it feels compelled to refresh apps on every new view. thanks.
1 hour ago, jonathanm said:He's not talking about the fresh install being that big, it's the ongoing activity where the paths defined INSIDE the container app don't match the paths defined by your docker config. If you have /media mapped to /mnt/user/Media, and you tell your docker app to download to /Media, it's going to fill up the docker image and not end up on the array.
Ye and I understand that, but again, this hasn't been an issue for ages, I will go over all mounts but all of them are being used correctly from what I could see, since I'd see data dissapearing into .img instead of my libraries and have messed up cases in the past that'd cause this.
-
1 hour ago, BRiT said:
The reason I said to do it one at a time is you obviously have something wrongly mapped on at least one of the dockers. There's no reason to need more space on the actual docker.img. Everything that requires large amounts of space should be mapped through outside the docker container. If you dont review and correct the wrong mapping(s) you will continue to have your original issue.
Thanks, and ye I get that, after adding fresh templates, no data or anything, it filled 10gb, all dockers should have their own appdata paths for config etc and anything pulling data is using main storage pool as well. I will go over all of them regardless, the only one I can think of would be influxdb which is storing sensors for grafana etc, I believe it should keep its db within appdata as well thought.
31 minutes ago, Squid said:Future reference: It's not page limited
What I meant is that I've a number of dockers in use and tested tripple that before as well. so I've 4 pages of old apps, unless im blind or missed some config somewhere I can't display more than 15 items per page under previous apps view. so could do 5-6 at a time (alphabetical) and also again seems to run them in sequence, which is probably intended method of install, but using multiple tabs I could add 5-6 at a time, sure they'd time each other out and cap wan link etc. using apps did "feel" faster though either way, thanks.
18 minutes ago, trurl said:In fact, you should recreate docker image with 20G. Making it larger will just take longer to fill. It won't fix the problem. I've never seen anyone needing more than 20G.
The usual cause of filling docker image is an application writing to a path that isn't mapped. Your mappings might be correct, but if the application isn't using those mapped paths, it is going to write into the image.
Typical mistakes are using different upper/lower case when specifying paths, or not using an absolute path (must start with / ).
I'd agree, and haven't had issues for a long time, like above, after fresh container reinstall from templates, it filled 10gb. I will go over all of them but can't imagine any of them being big enough to need 10gb and even then that'd take like an hour to dl which I'd notice on reinstall.
what it looks like, ignore disks, need to move some data around to reduce spinups, but ye docker 9.3g fresh installs with no configs
root@..:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 48G 762M 47G 2% / tmpfs 32M 488K 32M 2% /run devtmpfs 48G 0 48G 0% /dev tmpfs 48G 0 48G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 64M 65M 50% /var/log /dev/sda1 29G 447M 29G 2% /boot /dev/loop0 8.7M 8.7M 0 100% /lib/modules /dev/loop1 5.9M 5.9M 0 100% /lib/firmware /dev/md1 3.7T 341G 3.4T 10% /mnt/disk1 /dev/md2 3.7T 841G 2.9T 23% /mnt/disk2 /dev/md3 3.7T 1.6T 2.2T 43% /mnt/disk3 /dev/md4 3.7T 232G 3.5T 7% /mnt/disk4 /dev/md5 7.3T 2.7T 4.7T 37% /mnt/disk5 /dev/md6 7.3T 3.6T 3.7T 50% /mnt/disk6 /dev/md7 7.3T 3.5T 3.9T 47% /mnt/disk7 /dev/md8 7.3T 2.4T 5.0T 33% /mnt/disk8 /dev/md9 9.1T 11G 9.1T 1% /mnt/disk9 /dev/md10 932G 290G 642G 32% /mnt/disk10 /dev/md11 932G 983M 931G 1% /mnt/disk11 /dev/md12 932G 983M 931G 1% /mnt/disk12 /dev/md13 932G 983M 931G 1% /mnt/disk13 /dev/md14 932G 983M 931G 1% /mnt/disk14 /dev/md15 932G 983M 931G 1% /mnt/disk15 /dev/md16 932G 983M 931G 1% /mnt/disk16 /dev/sdz1 466G 103G 363G 23% /mnt/cache shfs 60T 16T 44T 26% /mnt/user0 shfs 60T 16T 45T 26% /mnt/user /dev/loop3 1.0G 17M 905M 2% /etc/libvirt /dev/loop2 50G 9.3G 41G 19% /var/lib/docker shm 64M 0 64M 0% /var/lib/docker/containers/97408ac7186b33a59b3af02cdef729f733f03899aea369a78caee2130a7c9fb4/mounts/shm -
9 hours ago, Squid said:
Much easier to simply go to the Apps tab, check off everything you want (more than 5 possible), and then hit install Multiple.
next morning, so restarted docker and its all gone again... fml.
So deleted docker.img this time properly and will try adding through apps and see how it goes.
edit;
so adding through apps is more convenient (despite being paged limited) but not faster, running a single docker add at a time compared to 5 tabs etc.
edit2;
okay, so manually deleting .img seems to have to worked, after reinstall and docker restart, everything still there. 10gig used after just install of what I acutally use (16, typical plex/sonarr/deluge setup etc). Restoring appdata now and will see what happens.
plex needs to chill with their file structure;
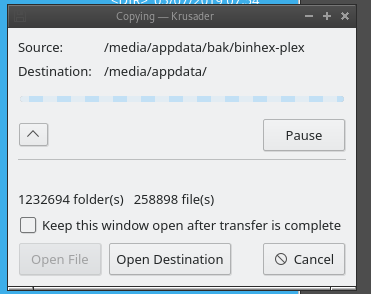
1.25m folders and 350k files and still going...
-
thanks, looks like unraid did that for me, only 500mb used when expanding size, so ended up moving existing data into subdir rather than extract from backup, after going through all templates (seems like unraid only handles 5 adds at once) setting and mappings were preserved which is nice, and now I've stopped docker and I'm moving data back into dir's.
I'm still assuming that it was the 20gig that filled up, if I didn't force delete the .img will unraid be happy on next boot, don't feel like going through restore again.
-
Title says it all really.
so... I suspect it was deluge or plex, not sure, but from the looks of it although .img was full (now expanded to 50gb and 500mb x3 logs). All appdata is there and accessible within cache mirror.
Anyone know how I can remap the docker containers? profiles still there but don't want to overwrite data on new container creation.
I have full nightly backups but just extracting 25gig tar would take a night probably.
any help appreciated.
-
flooded the library a bit to see what happens, and look like it was on the 2tb pass, filled disk1 until 2tb, and now going for disk 2. With that in mind, I suppose ideally you would keep smaller disks as lower count if you care for "higher use" of high water allocation, as in my case, you won't even touch 4tb drives until you have 18tb's writted to share. I'll expand with 10tb's and re arrange to see what happens, I would expect it to continue filling disk 2 until 2tb free and then look at disks again to choose best target.
-
massive dirs with thumbs? try over cifs and see if you can replicate
-
39 minutes ago, itimpi said:
Unfortunately not - that is the way High Water Allocation works. It works through drives in slot number order at each switch point.
If you are really concerned then I think the only solution would be to have the 4TB disks on lower slot numbers than the 8TB ones so they started being used first when the 4TB point was reached. Since you only have single parity this could be done without recalculating parity if you really wanted to do this. However is it worth it?
I see, well thanks for clarifying. Is there a recommended drive allocation when using high water? Also from what you're saying, the high mark threshold/pass is set when it has reached a breakpoint on a single disk? so in theory if I were to put empty drives ahead of 8tb (filled one) when 8tb reaches 2tb high mark, it'd run through disks in order and determine new mark?
And as you said, its not a huge deal, I'll be upgrading the wd1tb's to 10tb tonight so might move the drives around. So I'll break parity and move it down to data and create a new 10tb parity and 2nd will just go into data. Planning on grabbing a 2nd shelf at some point, but until then will probably rock single parity, given sas shares are sitting empty whilst I prep vmware move.
-
split set to any at the moment, not bothered about it, might end up setting 3 subdirs in future, but data no big enough to worry about it yet.

I've moved 900gb to other disk but didn't seem to do much and continue filling up first disk rather than reset to 4tb free mark and fill disk 2 etc.
I can't confirm but I believe its on the 2tb free pass atm so filling disk 1 until 2tb free mark and then moving down the drives but was hoping to move data around to force it down quicker instead of filling 75% of first disk before even touching empty 4tb drives
-
Hey,
So a quick one hopefully, so recently added more disks to my library share, which are lower volume than original and current disks, i.e had 3x8tb and now added 4x4tb.
Share is in high water allocation, I was wondering if running unbalance scatter job to rebalance data across the 7 drives would reset the high water "pass" count and instead of continuing on its current (2tb free atm) pass and retry from the start (i.e. 4tb free) given reduced disk space? I hope that makes sense?
-
Big thanks to you and your team, overall solid product and happy to continue using it.
Q1:
Do you plan to develop the hypervisor functionality further? such as including common gpu hardware drivers like nvidia, amd or intel for VM passthrough, which is currently achieved through community projects.
Q2:
SSD's are currently experimental and not fully supported, do you plan on bringing them along with nvme drives as future data mediums change (also ties into q1 in terms of drivers)?
Q3:
If you were to start the whole project again where would you focus your time or ditch some features/projects altogether?
-
 1
1
-
-
just reviving because 1st result in google;
binhex sonarr template maps /data to its appdata and it's what binhex deluge/vpn uses as its media path. so you'll need to map a path that both can access/use/rw and match in both mapping and target path, i.e. /completed/ to /mnt/user0/data/completed.
For proper automation, jackett grabs indexes, sonarr grabs all files, picks best match and throws it over to deluge with label of whatever set to move to dl to /downloads/ which sonarr has mapped as well and is able to pick up that file, then hardlink/copy and rename in right path that your media player can pick up in correct and renamed format. Then you just set label to seed to whatever, forever if you care, or just seed low value like .1 and delete on target which will remove badly named seed and it'll keep hardlink alive and well in right place.
Works well, with few rss feeds to auto feed new titles in etc which sonarr will add and pick up future releases, can just leave it to do its thing.
-
So started weekend project to migrate from freenas to unraid, all looking good so far, apart from expected 1.6days for data transfer and 40days for parity build lmao
Anyway, moving from vm hosted yassr2 deluge.
So turns out you can just move your old configs and eggs from (windows) %appdata%\deluge and drop them into your config path, default being /mnt/user/appdata/deluge..
although my plugins path is super broken pointing to c:\..\appdata\ it still picks up plugins dir fine and installs them correctly and enables according to .conf
And since im such a nice guy, here's my mega links if you want something to go off of with no previous setup, my current is just looking at some nyaa rss, so adapt as you need, very easy to read and make changes.
after enabling in web (will reset to off and report in deluged-web.log it has no ui)
[INFO ] 10:58:58 pluginmanager:108 'YaRSS2' plugin contains no WebUI code, ignoring WebUI enable call.
[INFO ] 10:58:59 pluginmanager:145 Plugin has no web uibut output from deluged.log
[INFO ] 10:44:07 rpcserver:206 Deluge Client connection made from: 127.0.0.1:34092
[INFO ] 10:44:41 logger:37 YaRSS2.__init__:34: Appending to sys.path: '/config/plugins/YaRSS2-1.4.1-py2.7.egg/yarss2/include'
[INFO ] 10:44:41 logger:37 YaRSS2.rssfeed_scheduler:42: Scheduled RSS Feed '1080p HorribleSubs Nyaa' with interval 5
[INFO ] 10:44:41 logger:37 YaRSS2.rssfeed_scheduler:42: Scheduled RSS Feed '1080p BlueLobster Nyaa' with interval 5
[INFO ] 10:44:41 logger:37 YaRSS2.core:40: Enabled YaRSS2 1.4.1
[INFO ] 10:44:41 pluginmanagerbase:158 Plugin YaRSS2 enabled....
INFO ] 11:03:59 logger:37 YaRSS2.rssfeed_handling:267: Update handler executed on RSS Feed '1080p BlueLobster Nyaa (nyaa.si)' (Update interval 5 min)
[INFO ] 11:03:59 logger:37 YaRSS2.rssfeed_handling:310: Fetching subscription '1080p BlueLobster Nyaa'.
[INFO ] 11:03:59 logger:37 YaRSS2.rssfeed_handling:80: Fetching RSS Feed: '1080p BlueLobster Nyaa' with Cookie: '{}' and User-agent: 'Deluge v1.3.15 YaRSS2 v1.4.1 Linux/4.19.41-Unraid'.
[INFO ] 11:04:00 logger:37 YaRSS2.rssfeed_handling:332: 70 items in feed, 70 matches the filter.
[INFO ] 11:04:00 logger:37 YaRSS2.rssfeed_handling:344: Not adding because of old timestamp: '[BlueLobster] Meow Meow Japanese History (01-96) [1080p] (Batch) (Neko Neko Nihonshi)'..
and proceed to use yarss2.conf file as configured.
added 2nd sub, just needs a "1" :{..} and another for feed, tested and works fine, make sure they're unique and match against right feeds



strange 100% cpu and ram
in General Support
Posted
oh, you're right, i missed that;
nobody 13716 8.7 92.7 92190640 91863428 ? Sl 06:34 66:18 | | \_ /usr/bin/python -u /app/bazarr/bazarr/main.py --no-update --config /config
okay, killing it for now then, I guess it's some memory leak, never seen it use that much/
Thanks