

caplam
-
Posts
334 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by caplam
-
-
So my server is back online with 2 single ssd pools formatted with xfs.
I now use docker-xfs.img for docker image.
Based the first hours activity, i can say that i have no more excessive writes.
I will stay away from btrfs for the future.
I found one strange thing on my vm explaining the excessive writes on vm-pool.
For an unknown reason in vm setting memory assignement has changed from 2GB to 1GB. Normally it would be ok but yesterday at midnight it started to write at 20MB/s rate. The vm was swapping. Normally cache on this vm is mounted on tmpfs.
So i shut of the vm and assign 4GB of memory: no more writes.
I've never seen that before.
So i checked other vm and the other vm which was writing a lot had it's memory down to 1GB (normally 2GB).
Btrfs problem apart, i would say that was a bug in vm settings has with correct memory settings i have no more excessive writes.
-
13 hours ago, limetech said:
How did you do the transfer? It's possible the "NoCOW" bit is not set for disk images, that is, the docker.img and all your VM vdisk images. If this is the case, all writes to these image files will result in btrfs copy-on-write operations. Since btrfs uses 1GiB block-group size, if say a docker container writes a single 4K block that will result in btrfs actually writing a 1GiB block (copy block group which contains the 4K block, update the 4K block, write the entire 1GiB block group to a new location). This is why we turn on NoCOW bit when images are created via webGUI. But if you simply used 'cp' command or similar, the target file will probably not have NoCOW bit set unless the directory you're copying to has NoCOW set. You can use the 'lsattr' command to see if NoCOW bit is set for a file, for example:
# here is C bit (nocow) set on directory root@test-1:/mnt/images/domains# lsattr ---------------C---- ./win10-1 ---------------C---- ./ubuntu # here is C bit set on file root@test-1:/mnt/images/domains# lsattr win10-1/ ---------------C---- win10-1/vdisk1.img
Note also you can create different pools, for example, to separate VM vdisk images from the Docker image.
The downside with having NoCOW set is that btrfs turns off checksumming for the file (but contrary to misinformation out there, you can still create reflink copies of NoCOW files and snapshots of subvolumes with NoCOW files).
i transferred it with cp command (docker and vm service stopped).
I checked and the no cow bit is not set for directory and img files. Share have enable COW set to auto.
But what you explain is for the initial transfer. How does it act once the transfer is completed and services restarted ?
I dropped the usage of docker.img. I'm now using directory option with dedicated share.
I must admit i don't fully understand COW things and let the option on auto in shares settings.
Until now i hadn't had to think about it. When i was using proxmox my vdisk were qcow2 and i could take snaphots.
For now i decided to use 2 single ssd pools. Right now i unassigned one ssd and restart array (balance is running).
I think the right path is then to convert to single pool. After that i will create the second pool and assign the second ssd, format it to xfs and transfer all data to it. The do the same thing for the first ssd (formatting xfs) and retransfer back the data need.
I'll wait to see the future of zfs and unraid (interesting for me as i have plenty of ram ecc); but for sure i won't use anymore unraid with btrfs.
-
if limetech is offering zfs, do you know if this will be a complete zfs array to replace the entire array and cache pool or the ability to make cache pool a zfs pool ?
If this the first we'll lose the ability to have different size disks.
For now i'm converting my cache pool to single disk and then i'll make 2 single ssd pools formatted with xfs. I'll use one as cache for array and docker, the other one for domains share.
edit: i remember having my synology nas formatted with btrfs and not having such issues.
-
i fired up my grafana docker and i can see that the average write rate on one of the ssd is around 6,5MB/s.
so it will write more than 500 GB a day.
edit this mean my ssds will last 13 month 🤬
-
and if we use qcow2 for vdisks on ext4. That was the cas when i was using proxmox and i never had such a problem.
At this time i had a small 256Gb ssd which i used during 4 years and it was still ok when i stopped my cluster.
-
wow this study is astonishing. I will read that but it's question of 30 times write amplification.
I don't even understand why btrfs is still being used. Performance are ridiculous.
I hope unraid will offer an alternative.
-
i read that. Does this mean there will be no solution to that?
In your post and followings it's discussed about loopback and overhead. But here i don't see excessive writes on loop3 device so i guess the writes are on vdisks.
4 Gb for one hour on a vm that does almost nothing i find that huge considering inside the vm iotop show 200MB activity on disk. This vm is an ipbx with almost no traffic. It's my home line with no calls today.
The other guest is a home automation system (jeedom) based on php and mysql. Inside the vm the activity is 10 times less than what we see outside.
I find that the amplification is massive. And it doesn't concern all the vm. I have others with no problem.
I have these 2 vm since a long time (rebuild them from time to time ) and before unraid they were running on proxmox on a lvm pool (formatted in ext4 if i remeber correctly).
If i can't have vm running on a pool i'll probably consider another system.
Perhaps the choice of raw for vdisk is not the best on a btrfs pool. I must admit i don't really understand all the implications.
I don't get the point of using only btrfs for the pool and moreover we don't even have a gui for managing snapshots.
-
i've checked my containers against the "healthy" mention. No one have that.
I haven't read anything about the format of docker image. I thought btrfs was mandatory. I assume it has nothing to do with the pool format which is also btrfs.
You can store image directly on file system ? Does this mean you don't have a loop2 device anymore ?
I didn't see such options.
edit i missed that option (docker image) as it was explained in beta 25 release post. I only installed beta starting with 30.
I think i will give a try to the directory option.
I have one question though. In the release post squid writes that if choosing directory option it's better to make a dedicated share but in his example (and default path when choosing this option) the directory is /mnt/cache/system/docker/docker which is in the system share.
I guess if i create a docker share the path is /mnt/cache/docker and it's ok?
-
Hello,
I upgraded to beta 30 from 6.8.3 when it became available.
In 6.8.3 i had the ssd write problem which killed 2 brand new ssd in 9 months.
I replaced the pool with a single xfs formatted ssd.
Yesterday i decided to setup a new pool with 2 brand new ssd (western blue 500Gb).
I transfered all data from the cache (appdata, domains and system share, no other data) to the new pool (around 310Gb). It was 15 hours ago.
Now here's a screenshot of smart data.
with iotop -ao i can see that each container startup write almost instantanously 4G on loop2 i have around 35 containers running. All are stopped each night for backup of appdata.
TID PRIO USER DISK READ DISK WRITE> SWAPIN IO COMMAND 25403 be/0 root 4.71 M 1263.98 M 0.00 % 1.00 % [loop2] 25946 be/4 root 0.00 B 111.59 M 0.00 % 0.09 % qemu-system-x86_64 -name guest=Her~rol=deny -msg timestamp=on [worker] 17588 be/4 root 0.00 B 90.50 M 0.00 % 0.07 % qemu-system-x86_64 -name guest=Her~rol=deny -msg timestamp=on [worker] 2795 be/4 root 0.00 B 87.25 M 0.00 % 0.00 % [kworker/u65:7-btrfs-endio-write]above is the result of iotop -ao after 10 min (containers are already started).
Of course the new pool is formatted in btrfs with 1Mib aligned partition.
I thought the write problem was solved in beta 25. Do i miss something obvious?
edit: i decided to dig a bit more. I looked the ssd which was used as single xfs formatted cache drive.
I set it up around the end of may until yesterday. I had 2 identicals ssd i used one for cache and keep the other.
They wera around 41728932997 lba written (19TB with 512 byte sector)
Today the ssd i used as single cache drive is at 107379774578 lba written (50TB)
So i guess during 5 months unraid has written 31TB. It's around 200GB/day.

-
Back on track.
To make this short.
I change my cache from btrfs to xfs. In one hour loop2 has written 1400MB. So it seems good.
The downside is all my vms and dockers are on cache without redundancy.
I didn't have to redownload dockers. I simply move cache content to an unassigned ssd, made the change on cache and move back cache content.
You can't count on mover as it's so slow. It moved only plex appdata folder (13GB) in 3 hours.
Now i'll wait to a fix, i prefer to have a cache pool than a single drive.
And i have to find 2 new ssd.
-
i tried to copy /var/lib/docker but failed (out of space). There must be some volumes that are mounted in /var/lib/docker/btrfs because when looking at the size of btrfs directory it's 315GB (docker.img is 60GB with 50GB used)
-
55 minutes ago, S1dney said:
You should only remove the docker image once your 100% sure that there's no data in there you still need, cause recreating or deleting it is a permanent loss of data.
I'm not really familiar with portainer, I can only speak for docker-compose, as I use that alongside the DockerMan GUI. Docker-compose created containers are only visible within the unRAID GUI once started, so this might be a similar thing?
Containers that were created outside of the unRAID docker GUI (DockerMan) also don't get a template to easily recreate. But if you're using docker compose or something, recreating should be easy right.
i've dropped the use of docker compose.
The 3 docker i recreated were recreated with dockerman Gui and still only 2 appear in the gui even when they were started.
docker template in unraid is very convenient. In my case there is a big downside: i have a poor connection so redownloading 60+ gig of images will take me around 2 days if shut down netflix for the kids. 🥵
I wish i could extract images from docker.img.
-
i think problems with my vm were related to qcow2 image format. I converted it to raw img and now kb written to disk are coherent between inside the vm and unraid.
Cache writes seem to stabilize around 800kb/s for that vm.
edit : could be related to btrfs driver. I downgraded to 6.7.2 and for the vm the problem is still there.
I think now i have to upgrade to 6.8.3 and apply the workaround of @S1dney
Do i have to delete docker.img or move it elsewhere ? Mine is 80GB so it takes lot of space.
edit2 : i applied the workaround in 6.7.2. I have to redownload all docker images (with a 5Mb/s connection it's a pain in the ass). I've redownloaded 3 docker but only 2 appear in the docker gui while portainer see them all.
-
i’ve just found a problème with a vm.
it’s a jeedom vm (home automation): debian with apache,php ans mysql.
it has a single vdisk and it’s on cache.
i ran iotop in unraid and in the vm.
results were extremely differents
during 10-15min i saw hundreds of MB written to disk by qemu process in unraid.
During the same time i saw few MB writen to disk by mysql in the vm.
result on cache disk was around 15 MB/s.
it’s approximately half of the troughput i had during months.
speaking of the table i posted above, figures come from diagnostics files.
When interval time is short (1 or 2 days), accuracy is not very good as i have not taken in consideration the time of the day the diagnostic file has been downloaded.
-
i'm downgrading to 6.7.2, hope i'm not doing a mistake
-
I think i made a mistake as my previous post was deleted.
Anyway i was writing i'm concerned too. I'm trying to find a workaround as unraid starts to throw alerts on both my ssds. The 187 Reported uncorrect attibute is growing.
I'm really pissed off with this situation as i was planning to replace my procurve switch with a unifi one but now i have to buy ssd as if it was ink cartridges for my printer. 👹
Docker service is stopped, i have only 2 vm running and i still have 6MB/S writes on ssd.
As unraid (or me probably ) is not doing things right all the time i take diagnostics from time to time. So i searched in history the starting point of the problem.
Attached is a spreadsheet with smartdata of one of the ssd.
Seeing this it seems pretty obvious things started going crazy with the 6.8.0.
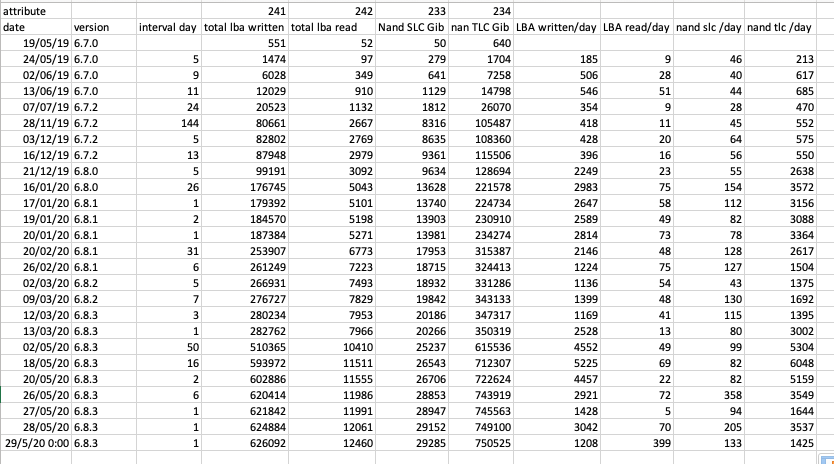
-
 1
1
-
 1
1
-




Unraid OS version 6.9.0-beta30 available
-
-
-
-
-
in Prereleases
Posted
i started a bug report here:
https://forums.unraid.net/bug-reports/prereleases/690-beta30-excessive-writes-on-ssd-pool-r1092/
in conclusion i would say that it concerns vm settings that has changed for unknown reason (perhaps a bug) and not a write problem at least for this case (xfs formatted pool with vdisks); from my understanding btrfs is still problematic.