




szymon
Members
-
Joined
-
Last visited
Everything posted by szymon
-
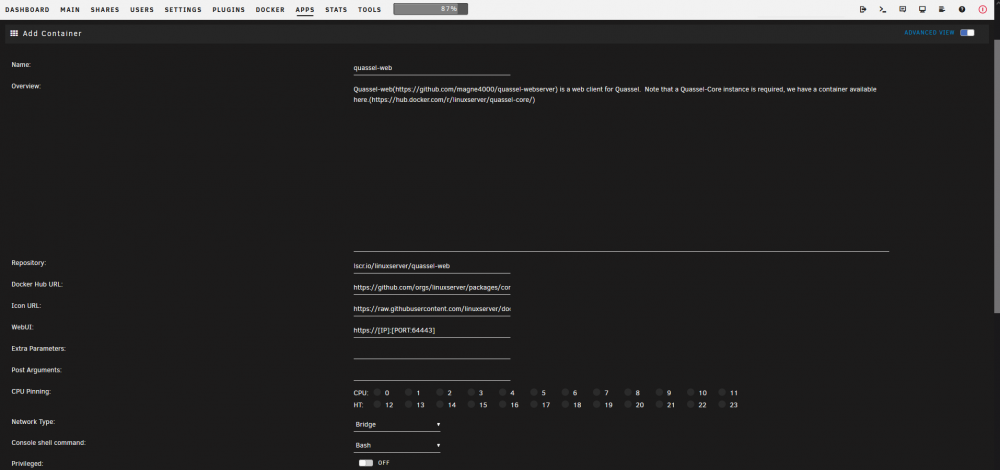
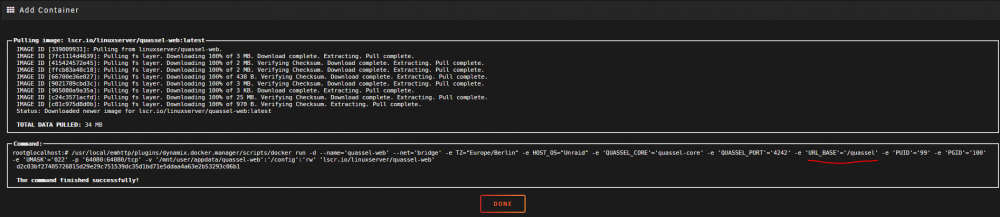
I am trying to install the Quassel Web applications published by Linux Server but the template seems to be incorrect. The WebUI URL has incorrect port. Should be 64080, not 64443, and http instead of https. Moreover, even when I remove the "URL_BASE" entry and leave it blank, it is still being overwritten with "/quassel" when I click the "Apply" button. Anyone else have the same issue?

-
Anyone has any experience with this tower case? Phanteks Enthoo Pro 2 Closed: http://www.phanteks.com/Enthoo-Pro2-Closed.html Tempered glass: http://www.phanteks.com/Enthoo-Pro2-TemperedGlass.html Supposedly it can fit up to 12 x 3.5 inch drives and has many cooling options.
-
I can confirm that the UPS reporting is now also gone for me. Any chances of bringing it back?


