

Alabaster
-
Posts
21 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Alabaster
-
-
I'll add some screenshots to hopefully help visualize this. With ACS override set to Both, system devices shows the following. The USB controller and GPU/audio I want to pass through are in groups 15, 31, and 32...
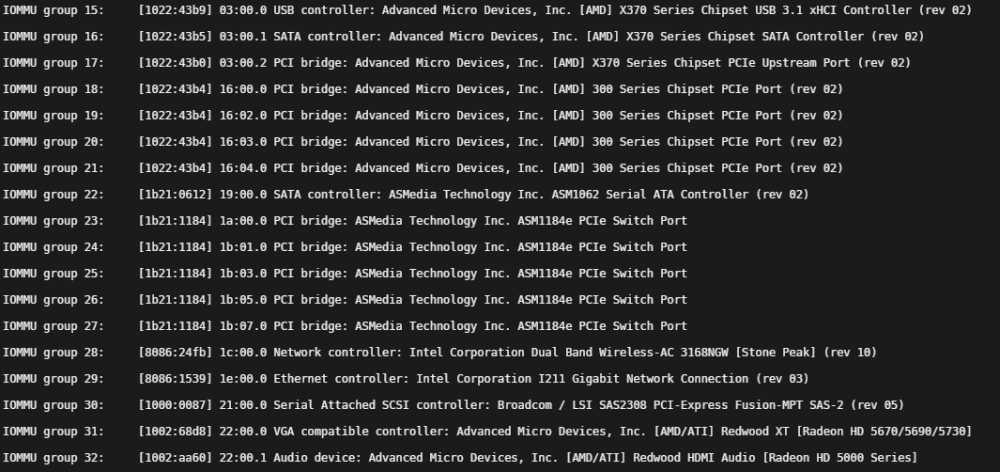
I have this line in the syslinux config. 1022:43b9 is for the USB controller from group 15 in the above screenshot.

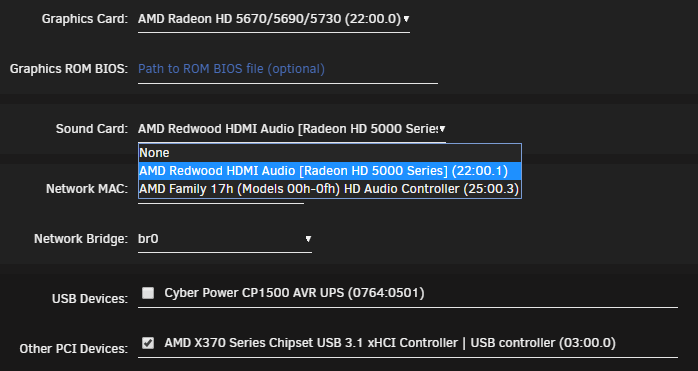
I add the GPU/audio and USB controller to the VM form as shown below and click Update.
The resulting XML is below and looks to be correct...
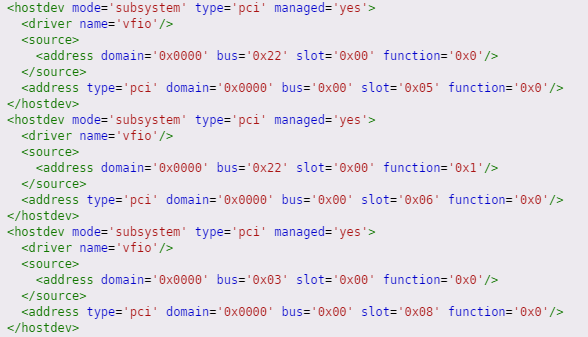
I then add multifunction='on' to the 6th line and update the slot and function on the 13th line for the audio. This is shown below...

I can start the VM, but nothing displays on the monitor. I then RDP'd into the VM and shut it down. If I remove the GPU/audio and USB controller from the VM form, verify the devices are also removed from the VM XML, disable ACS override, and remove the vfio-pci.ids section from the syslinux config the server fails to respond to a shutdown or reboot. I then have to hardboot it to get it responding again.
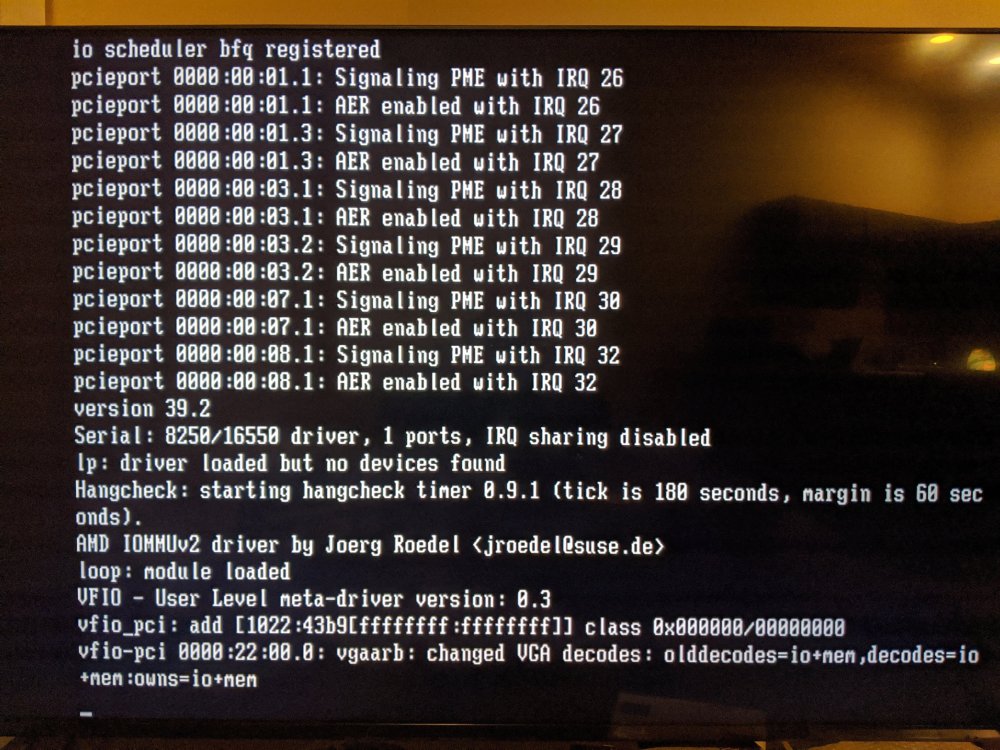
I also tried adding the GPU/audio IDs to the syslinux config as show below, but this prevented the server from booting and it got stuck at the screenshot from my original post.

-
12 hours ago, Carbongrip said:
what device is at vfio-pci.ids=1022:43b9
It's the onboard USB controller I mentioned in my post. The onboard bluetooth runs through this USB controller and I'm using it to connect an XBox One controller for gaming input. This USB controller has the same address through all the testing and I have no issues booting or passing through the USB controller with just that ID on the line.
12 hours ago, Carbongrip said:Try this, remove every address you added to vfio-pci.ids so it boots, then revisit iommu groups, find the address of each device you intend to passthrough while making sure there arn't new devices conflicting in a iommu group, and add it to vfio-pci.ids= .
I have tried this. After using ACS override the USB controller, GPU video, and GPU audio are each in their own IOMMU group. Adding the addresses for the GPU and associated audio to the vfio-pci.ids line causes the server not to boot as mentioned.
12 hours ago, Carbongrip said:Also open the VM configs, remove the pci cards from the virsh xml file and re add them. I think the <source><address></source> changes when the card moves slots so when the VM starts and goes looking for the card it's not their anymore.
I have tried this. After each attempt I would remove the GPU/audio from the VM template and verify the XML reflected the change. The addresses for the GPU/audio did change when physically moving slots. It went from 21:00.0 & 21:00.1 to 22:00.0 & 22:00.1 and the <source><address></source> section of the VM XML also reflected the new address when re-adding the GPU/audio to the VM.
-
I'm not sure I understand what you are asking. My apologies.
49 minutes ago, Carbongrip said:When your moving the cards to different slots are you making sure the vfio pci addresses arn't changing when they get a new slot?
Where can I verify the vfio PCI addresses? When I add the GPU and GPU audio to the VM template it has the same slot numbers (5 & 6) like it did when the card was physically installed in the other slot, if that's what you mean. I normally add multifunction='on' to the 6th line and then change the slot value and function in the 13th line to be 0x05 and 0x1, respectively, but I didn't change it for the screenshot below.
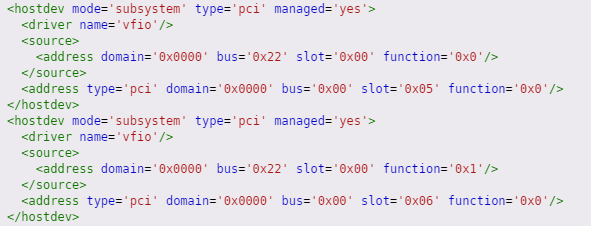 49 minutes ago, Carbongrip said:
49 minutes ago, Carbongrip said:You might need to update the syslinux file with new vfio addresses.
Are you saying to add the addresses(from system devices) to the vfio-pci.ids= line in the syslinux file? If so, I tried that but the server wouldn't boot and got stuck at the point in the original screenshot. I also tried using the 'VFIO-PCI CFG' plugin to bing the device, but that resulted in the server getting stuck at the same point in boot up.
-
I'm working on passing through a GPU and USB controller to a Windows 10 VM. Below are the components I'm working with.
Ryzen 5 2600
Radeon HD 5670
Asrock X370 Taichi mobo (top two x16 slots run at PCIe 3.0 x8/x8 when both are populated. The bottom x16 slot runs at PCIe 2.0 x4) (http://www.asrock.com/mb/amd/x370%20taichi/index.asp#Specification)To start off, I had 2 HBAs in the top two x16 slots (PCIe 3.0 x8/x8) and the GPU in the bottom x16 slot (PCIe 2.0 x4). With that configuration, the USB controller I needed to pass through was in the same IOMMU group as the GPU, but also with a SATA controller, ethernet controller, and a couple other things. So, I used ACS override (Both setting) along with vfio-pci.ids=1022:43b9 (for the USB controller) in the syslinux config and was then able to pass through the USB controller and GPU. This worked fine and I was able to get the VM to display on the monitor.
I was testing a game and was noticing poor performance. Sure, this could have been due to the GPU being old, but I wanted to test it in one of the top two slots that runs at PCIe 3.0 x8 instead of the current slot at PCIe 2.0 x4. So, I moved the HBAs to the bottom two x16 slots and put the GPU in the top x16 slot. I also updated the VM template since the GPU was in a new slot. Now I'm not getting the VM to display on the monitor. The monitor displays as unRAID boots up like it did with the previous config, but just shows a black screen when the VM is started. I can see the VM is starting up since I'm able to RDP into it.
I tried each setting for ACS override (Downstream, Multifunction, Both) and none improved the situation.
I removed ACS override and vfio-pci.ids=1022:43b9 from the syslinux config to see what stock looked like. The USB controller was still in the same old IOMMU group, but now the GPU is in a group by itself. That seems good.
After each unsuccessful attempt to get passthrough working I disabled ACS override, removed the vfio bit in the syslinux config, and removed the GPU and USB controller from the VM template. After doing so the server fails to come back online or display anything when it's restarted. I have to hard boot it to get it to respond again.
I tried the following changes in the uefi, but nothing helped.
Enabled 'SR-IOV' in North Bridge config
Enabled 'IOMMU' in AMD CBS\NBIO Common Options\NB Configuration (was set to 'Auto')
Set 'PCIe x16/2x8 Switch' to 2x8 (was 'x16')I also tried adding the addresses for the GPU and associated audio to vfio-pci.ids=, but this caused unRAID not to fully boot and it got stuck at the screen in the attached picture.
I do plan to upgrade the GPU and want to make sure it will work in this top slot so it can perform its best and also leave room around the HBAs for effective cooling. Any help on why GPU passthrough is working when the GPU is in the bottom slot, but not when in the top slot and in its own IOMMU group?
-
5 minutes ago, dmacias said:12 minutes ago, Alabaster said:Hey everyone,
I'm running Unraid 6.8.3 and just updated NUT to 2020.03.17. I no longer see the UPS status info on the top of the Dashboard page. It is still available from Settings>NUT Setting page though. Is the change on the Dashboard page expected?
Thanks!Thanks to gfjardim, he added it to the Server part of the dashboard under Power. He also added the footer display
OK, got that working now. I was not seeing UPS info in either of the areas you mentioned. I had to set the 'Display Page Footer' option in Settings>NUT Settings to Yes in order to see it in either location.
Thanks!
-
Hey everyone,
I'm running Unraid 6.8.3 and just updated NUT to 2020.03.17. I no longer see the UPS status info on the top of the Dashboard page. It is still available from Settings>NUT Setting page though. Is the change on the Dashboard page expected?
Thanks!
-
Looks like it's working fine for me now.
Initially the values for Model, S/N, size, etc wouldn't show when starting the preclear, but a reboot fixed that.
Thanks for the fix!
-
I'm trying to clear a few disks and running into a problem. The status shows 'starting...' for a few seconds and then goes right to 'Preclear Finished Successfully'. I get the following in the log...
Jan 16 23:43:27 preclear_disk_5VMCHPMH_22837: Command: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh --cycles 2 --no-prompt /dev/sdg
Jan 16 23:43:27 preclear_disk_5VMCHPMH_22837: Preclear Disk Version: 1.0.8
Jan 16 23:43:28 preclear_disk_5VMCHPMH_22837: S.M.A.R.T. info type: default
Jan 16 23:43:28 preclear_disk_5VMCHPMH_22837: S.M.A.R.T. attrs type: default
Jan 16 23:43:29 preclear_disk_5VMCHPMH_22837: Disk size: 500107862016
Jan 16 23:43:29 preclear_disk_5VMCHPMH_22837: Disk blocks: 976773168
Jan 16 23:43:29 preclear_disk_5VMCHPMH_22837: Blocks (512 byte): 976773168
Jan 16 23:43:29 preclear_disk_5VMCHPMH_22837: Block size: 512
Jan 16 23:43:29 preclear_disk_5VMCHPMH_22837: Start sector: 64
Jan 16 23:43:34 preclear_disk_5VMCHPMH_22837: Pre-Read: dd if=/dev/sdg of=/dev/null bs=2097152 skip=0 count=500107862016 conv=notrunc iflag=nocache,count_bytes,skip_bytes
Jan 16 23:43:35 preclear_disk_5VMCHPMH_22837: /usr/local/emhttp/plugins/preclear.disk/script/preclear_disk.sh: line 1059: 4194304 / (1579239814 - 1579239814) / 1000000 : division by 0 (error token is "(1579239814 - 1579239814) / 1000000 ")I tried reinstalling the plugin, but get the same result as noted above. Below is the plugin install log for review...
plugin: installing: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg
plugin: downloading https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg
plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/plugins/preclear.disk.plg ... done
plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/archive/preclear.disk-2020.01.16a.txz ... done
plugin: downloading: https://raw.githubusercontent.com/gfjardim/unRAID-plugins/master/archive/preclear.disk-2020.01.16a.md5 ... done
tmux version 3.0a is greater or equal than the installed version (3.0a), installing...+==============================================================================
| Skipping package tmux-3.0a-x86_64-1 (already installed)
+==============================================================================libevent version 2.1.11 is greater or equal than the installed version (2.1.11), installing...
+==============================================================================
| Skipping package libevent-2.1.11-x86_64-1 (already installed)
+==============================================================================utempter version 1.1.6 is greater or equal than the installed version (1.1.6), installing...
+==============================================================================
| Skipping package utempter-1.1.6-x86_64-3 (already installed)
+==============================================================================
+==============================================================================
| Installing new package /boot/config/plugins/preclear.disk/preclear.disk-2020.01.16a.txz
+==============================================================================Verifying package preclear.disk-2020.01.16a.txz.
Installing package preclear.disk-2020.01.16a.txz:
PACKAGE DESCRIPTION:
Package preclear.disk-2020.01.16a.txz installed.-----------------------------------------------------------
preclear.disk has been installed.
Copyright 2015-2020, gfjardim
Version: 2020.01.16a
-----------------------------------------------------------plugin: installed
I'm running Unraid 6.8.1 and also updated Unassigned Devices for good measure(currently at 2020.01.16a). I also installed Unassigned Devices Plus as I saw a message stating that was needed to enable destructive mode.
I would try a reboot, but I have a parity sync in progress after doing a new config and want to let that finish.
Seems the script is erroring out though. Anyone else running into this issue?
-
Been using unRAID for a few months now. Currently using it as a media server with Plex and also have a Win10 VM on it. I'll be looking to expand it for IP camera storage with ZoneMinder and for DVR(once I purchase the Plex Pass).
I did a lot of searching for an OS that would fit my use cases and unRAID hasn't let me down. Having such a helpful community is wonderful.
-
First, thanks to SpaceInvaderOne for all the amazing videos!
My server is mainly for media storage, but I also have one share that has tons of small files, I think it's like 1.7 million files. So, when trying to search the various media shares(movies, kids movies, new folder, downloads, etc) from the root share for a particular item, it takes an incredibly long time since it's also searching the one share with almost 2 million files. I would like to exclude that share to speed up searches. Is there a way to exclude a share from being listed in the root share?
Or a way to mount the share somewhere other than /mnt/user?
-
I believe this is pretty much in line with my request in the Feature Requests section. Not sure if it would help much, but maybe you can vote or support the feature request to get more visibility for something like this. Hope that helps!
-
I have the same UPS and haven't had issues with it being detected.
I did have an issue getting the server and UPS to shutdown properly so the server would power back on after an outage, but I was able to resolve that by tweaking settings in the NUT plugin. Sharing a post I made about that below in hopes that someone will get use out of it.
-
 1
1
-
-
UPDATE:
I returned one of the ADATA drives and purchased a HP EX920. Both drives will now show up now.
I was doing testing on my UPS setup to make sure the server will come back on after a power outage. I have a CyberPower CP1500AVRLCD UPS and am using the NUT plugin for communication. I noticed the UPS was turning off before the server would shut down. This was causing a hard shutdown and the ADATA drive would not show up after powering the server back on, not even in BIOS/UEFI. It also wouldn't show up on subsequent reboots either. I would have to swap the drives between the M.2 slots and boot it back up for both drives to show up again (not convenient!!). I was able to tweak the settings and config files in the NUT plugin to get my desired shutdown sequence in order to avoid this problem.
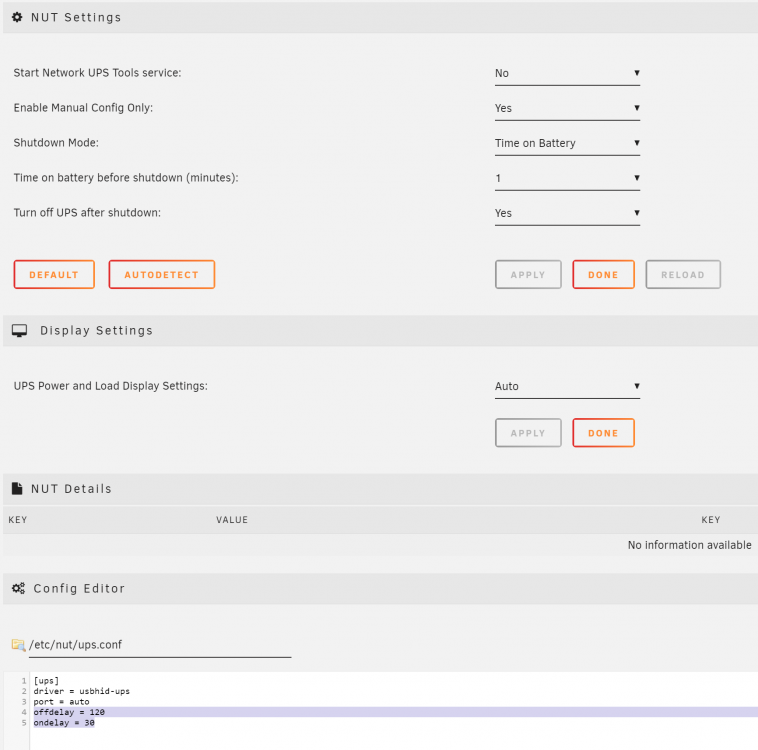
In case anyone was wondering, I effectively ran the Autodetect function in NUT, switched the 'Enable Manual Config Only' option to Yes, then added the two highlighted lines in the screenshot to the ups.conf file. Adding the 'offdelay' instructs my UPS to delay its shutdown for roughly X seconds. This allowed more time for the server to shutdown. The default is 20secs which is simply not enough. I tried adding the same to the ups.conf file when the 'Enable Manual Config Only' option was set to No, but the value would default when the service was started, thus I had to set it to Yes. Below are the settings I'm using for visual reference(I didn't have the service started in the screenshot as I was still testing, I also only had the shutdown time set at 1min for testing purposes as well). Of course, your mileage may vary. Hope that helps someone!
-
Custom case icons feature is now available in 6.7.2.
-
This is now available in 6.7.2
-
No, I haven't sorted this out.
According to the following link, it appears there will be a fix in the Linux 5.3 kernel. I'm not Linux savvy, so I'm not sure how that will play out for unRAID.
https://forum.proxmox.com/threads/only-one-of-two-nvme-detected-in-linux-duplicate-subnqn.54480/
I thought the NQN was something configurable by the manufacturer. So, I would blame on ADATA and not Realtek. I could be completely wrong about that though.
I contacted ADATA "customer service" (in quotes since it is a joke). Their response email looks completely automated as it starts with "Dear Customer" and doesn't even have the name I entered when filling out the online form to contact them. The email starts out acknowledging I have an issue and then goes right into stating they are here to assist with the return of the product. The email did provide a few generic troubleshooting steps, but had absolutely no mention of the issue I explicitly detailed for them (again, since this is an automated, impersonal email.) I'll try replying to the email to see if that actually gets anywhere.
I think I'll probably just return the drives and spent a bit more for another brand.
-
 1
1
-
-
I just purchased 2 M.2 drives hoping to use them as a cache pool. The UEFI menu will show both drives, but the unRAID web GUI will only list one of the drives. Below is a little about my setup.
Motherboard: ASRock X370 Taichi
CPU: Ryzen 5 2600
M.2 drives: 2x XPG SX6000 Lite M.2 2280 512GB PCI-Express 3.0 x4 3D NAND
HBAs: 2x LSI 9207-8i
GPU: ATI FireMV 2250
I tested each drive separately and each will be detected in the web GUI in either M.2 slot when installed one at a time. However, unRAID isn't showing both of them when they're both installed, although the UEFI sees both of them.
After swapping drives and slots, I removed the GPU thinking it may be some odd PCIe lane allocation issue, but the issue persisted. I also updated from 6.7.0 to 6.7.2. Attached are the diagnostics.
I looked through syslog.txt and it looks to be an issue with both drives using the same NVMe Qualified Name (NQN). I'm researching this path at the moment, but hope someone with more experience can weigh in with a possible solution. Any ideas?
-
1
-
-
I asked a Dev over on this topic about custom, user-created case icons. The feature is in development.
-
1
-
-
@Mex, Is it possible for users to create their own icons, drop them in some directory, and then use the webUI to set the icon? If so, where are the icons stored?
-
I have a fan moving air over my HBAs (2x LSI 9207-8I) to help cool the heatsinks. I would like to see the ability to have a notification sent when a fan quits working i.e. RPMs drop to zero.
I see the dashboard has an Airflow section, but the settings gear for that section just goes to a blank page. So, maybe something like this is in the works already, but I wasn't able to find anything on such a feature.
Furthermore, I would like to see the ability to rename the fans in the dashboard. Being able to rename them to "CPU", "HBA", "Back Case" or something similar would also help in conveying the importance of the notification based on the fan name.













GPU passthrough working with one PCI slot but not another
in VM Engine (KVM)
Posted
Update: The good news is that the server is not failing to boot after adding the GPU pci ids to the vfio-pci.ids line in the syslinux config. I just needed to wait longer for the server to boot and come back online.
The bad news is I'm still having the same issue...The video output for the VM is not displayed on the monitor. Also, after starting the VM, and also stopping it later, the server will not respond to a shutdown/reboot and I need to hardboot it to get it responding again.
Anyone have any other ideas?