
sonic6
-
Posts
610 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by sonic6
-
-
On 4/13/2023 at 6:02 PM, mgutt said:
Mit dem Befehl während dem Upload:
find /mnt/user/appdata/nextcloud/data/*/uploads -type f -exec ls -lah {} \;
Ich kann jedem nur empfehlen auf zumindest 64 MiB zu erhöhen. Deutlich weniger Chunking und damit mehr Performance.
Also falls es jemand mit dem LSIO Container Testen will:
find /mnt/user/nextcloud/*/uploads -type f -exec ls -lah {} \;Mir ist aufgefallen, dass das Chunking hier bei 10MB aus dem Webbrowser lag, jedoch über die Windows Anwendung folgendes zeigt:
root@Unraid-1:~# find /mnt/user/nextcloud/*/uploads -type f -exec ls -lah {} \; -rw-r--r-- 1 nobody users 9.6M Apr 16 09:58 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000000 -rw-r--r-- 1 nobody users 570M Apr 16 09:58 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000001 -rw-r--r-- 1 nobody users 953M Apr 16 09:59 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000002 -rw-r--r-- 1 nobody users 954M Apr 16 10:00 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000003 -rw-r--r-- 1 nobody users 954M Apr 16 10:00 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000004 -rw-r--r-- 1 nobody users 954M Apr 16 10:01 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000005 -rw-r--r-- 1 nobody users 954M Apr 16 10:02 /mnt/user/nextcloud/sonic6/uploads/995972344/0000000000000006Hier scheint die Größe der Chunks bei ca 1GB zu liegen.
Wenn man das noch anpassen könnte und sich das auch aufs WebDAV auswirken würde, wäre der CF-Tunnel wieder eine Option für die NC.
-
16 hours ago, mgutt said:
Kommando steht in meinem vorherigen Beitrag 😁
funktioniert nicht mit dem LSIO Container. Weder mit Web noch App uploads.
root@Unraid-1:~# find /mnt/user/appdata/nextcloud/data/*/uploads -type f -exec ls -lah {} \; find: ‘/mnt/user/appdata/nextcloud/data/*/uploads’: No such file or directory -
On 4/12/2023 at 9:17 PM, mgutt said:
Das erklärt auch, warum so viele Probleme haben, wenn ihre Nextcloud über den Cloudflare Proxy betrieben wird (der trennt meine ich bei 128MB).
sollten ca 200MB sein
19 hours ago, mgutt said:21 hours ago, i-B4se said:Wo kann ich das mit dem Chunking sehen?
Mit dem Befehl während dem Upload:
find /mnt/user/appdata/nextcloud/data/*/uploads -type f -exec ls -lah {} \;
Ich kann jedem nur empfehlen auf zumindest 64 MiB zu erhöhen. Deutlich weniger Chunking und damit mehr Performance.
ich hatte, abgesehen vom CF Tunnel auch noch nie Probleme damit. Kann es vielleicht sein, dass das Chunking beim LSIO Container im Web default aus ist?
-
14 hours ago, mgutt said:
EDIT: OK etwas gefunden. Nur verstehe ich nicht. Was macht denn das Kommando? Fügt das eine neue Einstellung in der config.php hinzu oder wo schreibt der die Einstellung hin?!
sudo -u www-data php occ config:app:set files max_chunk_size --value 20971520
Kann es sein, dass sich das nur auf die App/Anwendung bezieht?
Die Chunks sollen ja normalerweise "nur" 10MB groß sein. Zusammen mit dem CF-Tunnel gibt es mit NC über den Browser aber immer Probleme, da der CF-Tunnel nur 200MB Pakete zulässt.
Die NC Apps über Android/Windows machten hier nie Probleme, Up-/Download hingegen über den Browser brachen nach 200MB aber immer ab.
-
On 1/16/2023 at 12:47 AM, mgutt said:
Problem: Alle meine User haben ein unendliches Kontingent. Vom Gefühl her würde ich sagen, dass man lieber einen festen Wert eintragen sollte, damit der Papierkorb nicht immer weiter wächst.
Zusätzlich dachte ich daran, das hier zu machen:
'trashbin_retention_obligation' => 'auto,30',
Das sollte denke ich bedeuten: Lösche, wenn der Papierkorb mehr als 50% des Kontingents belegt und grundsätzlich alles was länger als 30 Tage im Papierkorb ist.
Bin vor ein paar Jahren auf genau die gleiche "Problematik" gestoßen.
Bin das Problem letztendlich genauso angegangen wie du. Ich habe ein Default Contingent von 20GB gewählt.
300GB ist für mein System zu viel, da mein Cache nur 500GB sind und ich als Hauptnutzer bisher "nur" 10GB in der NC nutze.
Der Papierkorb ist bei mir dann nochmal so ne Art "Fallback", falls ich mal was lösche, habe den also bei mir auf "120, auto" stehen.
-
7 hours ago, jbartlett said:
DiskSpeed version 2 will not benchmark multiple-drive pools, it's purpose is benchmarking single drives.
Interessting. I upgraded my btrfs-raid1 cache pool yesterday from two SATA mx500 SSDs to this PCIe 220S NVMe SSDs. The mx500 SATA drives (part of pool) where benchmarkable.
-
Nabend zusammen,
ich habe heute mal meinen Server um zwei SATA SSDs erleichtert und zwei NVMe SSDs (Transcend PCIe SSD 220S 1TB) erweitert.
So weit so gut, ist mir nun jedoch aufgefallen, dass ich nun komplett in C2 stecken bleiben, was meinen Idle Verbauch (mit diversen Containern Docker/LXC) von 29W auf 35W hochtreibt.
Dass ich nie über C3 hinaus kam, liegt an meinem HBA, was mich nicht weiter störte/stört.
Nun vermute ich aber die neuen NVMe SSDs daran schuld sind, dass mein System nicht mehr über C2 hinaus geht:
root@Unraid-1:~# lspci -vv | awk '/ASPM/{print $0}' RS= | grep --color -P '(^[a-z0-9:.]+|ASPM )' 00:01.0 PCI bridge: Intel Corporation 6th-10th Gen Core Processor PCIe Controller (x16) (rev 05) (prog-if 00 [Normal decode]) LnkCap: Port #2, Speed 8GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <256ns, L1 <8us LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 00:1b.0 PCI bridge: Intel Corporation Comet Lake PCI Express Root Port #21 (rev f0) (prog-if 00 [Normal decode]) LnkCap: Port #21, Speed 8GT/s, Width x4, ASPM L0s L1, Exit Latency L0s <1us, L1 <16us LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 00:1d.0 PCI bridge: Intel Corporation Comet Lake PCI Express Root Port #9 (rev f0) (prog-if 00 [Normal decode]) LnkCap: Port #9, Speed 8GT/s, Width x4, ASPM L0s L1, Exit Latency L0s <1us, L1 <16us LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ pcilib: sysfs_read_vpd: read failed: No such device 01:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03) LnkCap: Port #0, Speed 5GT/s, Width x8, ASPM L0s, Exit Latency L0s <64ns LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 02:00.0 Non-Volatile memory controller: Transcend Information, Inc. Device 2262 (rev 03) (prog-if 02 [NVM Express]) LnkCap: Port #0, Speed 8GT/s, Width x4, ASPM not supported LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 03:00.0 Non-Volatile memory controller: Transcend Information, Inc. Device 2262 (rev 03) (prog-if 02 [NVM Express]) LnkCap: Port #0, Speed 8GT/s, Width x4, ASPM not supported LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ root@Unraid-1:~#Konnte bisher keine Infos zu den NVMe ( Transcend PCIe SSD 220S 1TB ) und ASPM finden.
Hier mal mein System (in meiner Signatur sogar mit Links zu den Datasheets):
CPU: Intel Core i5-10400 --- RAM: 2x16GB Crucial CT2K16G4DFRA266 ---
M/B: ASRock > H470M-ITX/ac
HBA: IBM ServeRaid M1015 SATA / SAS HBA Controller (IT Mode) for SATA / Onboard for NVMe
Cache1 btrfs-RAID1: 2x1TB Transcend PCIe SSD 220S ###
Cache2-xfs: 1x500GB Crucial CT500MX500SSD1
Parity: 1x10TB WD100EFAX --- Data: 1x10TB WD100EFAX ###
Pool1: 1x4TB WD40EFRX ---
Media-UD: 1x18TB Toshiba MG09ACA18TE
Vielleicht hat jemand nen heißen Tipp?
-
container works fine for me on 6.11.5
-
 1
1
-
-
Hi,
I got two unbenchmarkable NVMEs:
NVMEs: 2x transcend PCIe SSD 220S (https://de.transcend-info.com/products/No-991) in a btrfs raid1-pool
Board: ASRock H470M-ITX/ac (https://www.asrock.com/MB/Intel/H470M-ITXac/)
Unraid: Version 6.11.5
Diagnostic send per Mail. -
2 hours ago, mgutt said:
Conclusion: It could be useful to create sometimes a backup with the "checksum" option. I already thought about adding this by default every 30 backups. Not sure how others think about that.
maybe as an option? i would use that.
-
8 hours ago, Patty92 said:
Problem ist der standardmäßige Zwang einer Internetverbindung. Kann aber umgangen werden (Post 31. Juli)
@mgutt kannst du den Post vielleicht in deinem Guide im 1. Post einpflegen? Wenn denn tatsächlich mal jemand komplett ließt, kann er das Problem selbst beheben

-
Da ich mit Skripten etc nicht viel Erfahrung habe, bin ich für Kritik und Anmerkungen offen.
Um das Script aktuell zu halten und zu erweitern, teilt mir bitte mit, wenn ihr es mit euer USV getestet habt und/oder abweichende Meldungen für Bestandene oder Fehlgeschlagene Tests bekommt.
Getestet wurde das Script mit folgenden USVen:
- CyberPower CP900EPFCLCD
Changelog/Anpassungen
06.03.2023 - V1.1 (danke an @Anym001 und @ich777 fürs Notification IF), getestete USVen, Anpassung der Beschreibung
-
Hier ein kleiner Anfänger Guide/Inspiration für einen automatischen Batterie Test einer USV, welche per NUT Plugin betrieben wird.
Das Script lässt einen lautlosen Batterie schnelltest der USV laufen und gibt das Ergebnis per Standard Unraid Nachricht aus.
Vorab sollte man einmal testen, ob test.battery.start.quick verfügbar ist. Das ganze per folgendem Befehl im Terminal:
upscmd -l UnraidUPSUnraidUPS steht hier für den UPS Name aus dem NUT Plugin:
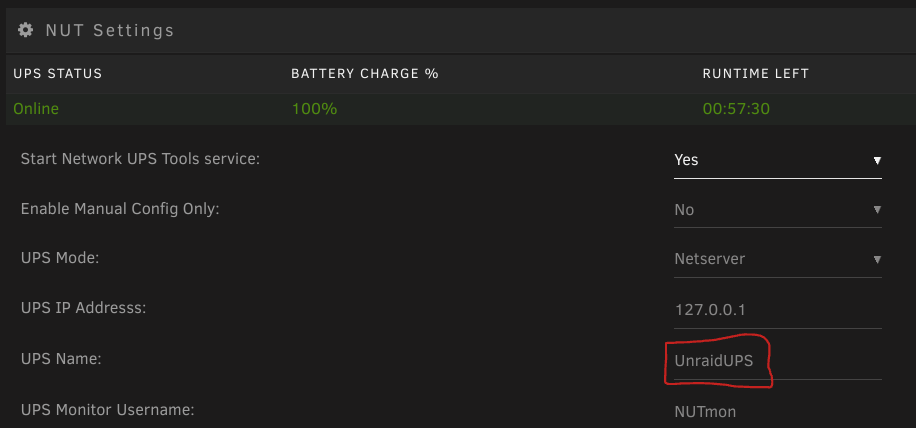
Sollte test.battery.start.quick in der Liste auftauschen, kann man recht einfach folgendes Script per User Script Plugin ausführen lassen:
#!/bin/bash ###NUT UPS QUICK BATTERY TEST### ###V1.1 ###https://forums.unraid.net/topic/135969-anleitung-simples-usv-batterie-schnelltest-user-script-mit-nut/ ################################ #vars### u="admin" #username p="adminpass" #password upshost="UnraidUPS" #UPSname@IP:Port - IP and PORT are optional ######## #battery test upscmd -u $u -p $p $upshost test.battery.start.quick upscmd -u $u -p $p $upshost beeper.mute sleep 2s #wait for result result=$(upsc $upshost ups.test.result) while [[ $result == "In progress"* ]] do sleep 0.5s result=$(upsc $upshost ups.test.result) done #unraid notifitcation result_success="$(echo ${result} | grep -E '\b(passed|success|OK|successful)\b')" result_warn="$(echo ${result} | grep -E '\b(warning|WARN)\b')" if [ -n "${result_warn}" ]; then /usr/local/emhttp/webGui/scripts/notify -s "UPS test passed with warnings." -d "$result" -i warning elif [ -n "${result_success}" ]; then /usr/local/emhttp/webGui/scripts/notify -s "UPS test passed." -d "$result" -i normal else /usr/local/emhttp/webGui/scripts/notify -s "UPS test failed!" -d "$result" -i alert fiu, p und upshost sind in dem Script die default Werte des NUT Plugins, können/sollten jedoch angepasst werden, wenn diese verändert wurden.
-
 3
3
-
-
On 2/13/2023 at 10:52 PM, AlfredHaas said:
Ich verwende die VM Variante von Home Assistent (HAOS) unter unraid den ohne Supervisor beraubt man sich um einige wichtige Applikationen und Tools wie z.B erwähntes zigbee2mqtt.
Wenn man HA als Container laufen lässt, ist der Supervisor überflüssig. Man beraubt sich hier gar nix, weil der Host (Unraid in diesem Fall) die Aufgabe übernimmt. Der Supervisor stellt lediglich nen Container Dienst zur Verfügung. HA im Container kann in Verbindung mit dem Host nicht mehr oder weniger als HAOS.
-
1
-
-
-
13 hours ago, ich777 said:
I don't have a Fritzbox but maybe @sonic6 or @alturismo know what to do?
This is my source for DSL Link Status:
gateway_connection_status{connection="Physical Link"} -
5 hours ago, Bengon said:
Muss definitiv das Update sein.
HA ist hier auf der aktuellsten Version und macht keine Probleme mit dem sonoff zigbee 3.0 usb dongle plus.
-
13 minutes ago, mgutt said:
Tatsächlich sind die gedruckten Anleitungen der Shelly 3EM alle falsch:
Die Anleitung ist nicht Falsch, der Aufdruck auf den Messwandler ist falsch. Die Bezeichnung vom Generator "K" zum Verbaucher "L" ist schon richtig. Ich musste es auch schmerzlich erfahren, als ich in meiner Mini-Verteilung alle verbaut hatte und mir danach nochmals die Finger brechen durfte...
-
Kann das vielleicht mit deinen Stromspar Commands aus dem Go-file / powertop zusammenhängen?
-
17 hours ago, mgutt said:
Jetzt ist allerdings die Frage, ob der auch noch über L2 und L3 was zieht, weil der aktuell gemessene Verbrauch mit ungefähr 0,35W ist schon sehr gut:
Das Feedback würde mich interessieren. Denke schon, dass die Spannungsmessung etwas ziehen wird, aber die Hauptversorgung sollte vom L1 kommen.
-
8 hours ago, mgutt said:
Verstehe ich das richtig, dass man Entitäten nur ein- oder ausschließen kann? Ich hätte jetzt erwartet, dass man zB den Verbrauch 90 Tage speichert, aber Spannung und Temperatur nur 7 Tage. Stattdessen muss ich jetzt wohl Spannung und Temperatur komplett ausschließen?!
Hatte das ganze Thema nur überflogen und keine unterschiedlichen Log-Perioden finden können. Hatte ähnliche vor, aber aufgrund von Faulheit und vorhandenem Speicherplatz habe ich einfach alles weiter loggen lassen bei 100 Tagen.
8 hours ago, mgutt said:Kann ich davon ausgehen, dass HA deaktivierte Entitäten nicht mehr loggt?
Ich habe zumindestest keine Historie mehr zu deaktivierten Entitäten.
8 hours ago, mgutt said:Richtig beknackt ist ja, dass der sogar zB den Bass-Regler meiner Sonos Boxen loggt
Ja, gilt theoretisch für fast alles was man parametrieren kann... Zustände werden halt geloggt. Ähnliches gilt ja auch für die Identify-Buttons von diversen Zigbee Geräten.
6 hours ago, mgutt said:So ich denke ich habe nun alles deaktiviert. Dauert echt ewig bei vielen Aktoren 🤪
Jo,... die Fritzbox/AVM Integration kann einen da richtig Nerven kosten.
-
6 hours ago, mgutt said:
Der Shelly hat ja jetzt 3 Sensoren. Kann ich die Summe aus den 3 Sensoren zu einem Sensor zusammenfassen? Das das aufgeteilt wird, finde ich doof:
Hierfür gibt es eine gute HACS Integration: https://github.com/bramstroker/homeassistant-powercalc
-
1
-
-
mal als kurze Rückmeldung:
hatte mal auf 100Tage gestellt und meine DB ist jetzt bei 6,5GB ... vielleicht sollte ich hier ein wenig filtern.
-





Nextcloud Sicherheits- & Einrichtungswarnungen beheben
in Anleitungen/Guides
Posted · Edited by sonic6
Genau, den Output vom Browserupload habe ich mir gespart. Der gepostete Output war von der Nextcloud Windows App.
*edit*
Es könnte hieran liegen:
Quelle: https://docs.nextcloud.com/desktop/3.2/advancedusage.html?highlight=chunk
Habe gerade aber keine Möglichkeit das zu prüfen.