

Armed Ferret
-
Posts
105 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Armed Ferret
-
-
18 hours ago, SentientNut said:
You may have to follow this guide to fix the database after the v4 upgrade. I personally did not have to do this, but I read the patch notes this morning and was prepared to just in case.
https://wiki.servarr.com/useful-tools#recovering-a-corrupt-db
Im having the same issue but Im not sure how to do this with an Unraid docker.
-
I run plex on ubuntu to take advantage of hardware transcoding. I am trying to automount my shares, but when I restart autofs.service I cannot see the shares anymore.
username@plex:~$ ls /mnt/nfs ls: cannot access '/mnt/nfs/tv': No such file or directory ls: cannot access '/mnt/nfs/music': No such file or directory ls: cannot access '/mnt/nfs/movies': No such file or directory movies music tvHowever, when I stop the autofs.service I can ls to those folders.
username@plex:~$ ls /mnt/nfs/movies username@plex:~$Anyone know how to get this working?
-
5 hours ago, noax said:
Thanks for you help,
I think I found the issue... I do not have cache drive, when I run your command there is an error that is returned, I am not sure how it happened and why it is gone...
Did you try rebooting unraid? Did that resolve the error?
-
On 9/2/2022 at 11:24 AM, noax said:
I get an error with sabnzbd...
Here is the traceback call error:
Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/nzbparser.py", line 319, in process_single_nzb nzo = nzbstuff.NzbObject( File "/usr/lib/sabnzbd/sabnzbd/nzbstuff.py", line 778, in __init__ admin_dir = os.path.join(self.download_path, JOB_ADMIN) File "/usr/lib/python3.10/posixpath.py", line 76, in join a = os.fspath(a) TypeError: expected str, bytes or os.PathLike object, not bool ERROR a few seconds ago Failed making (/data/incomplete/House.of.the.Dragon.S01E02.The.Rogue.Prince.1080p.HMAX.WEB-DL.DDP5.1.H.264-NTb) Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/filesystem.py", line 719, in create_all_dirs os.mkdir(path_part_combined) OSError: [Errno 5] Input/output error: '/data/incomplete/House.of.the.Dragon.S01E02.The.Rogue.Prince.1080p.HMAX.WEB-DL.DDP5.1.H.264-NTb' ERROR a few seconds ago Error while adding House.of.the.Dragon.S01E02.Episode.2.1080p.HMAX.WEB-DL.DDP5.1.Atmos.H.264-SMURF-Scrambled.nzb, removing Traceback (most recent call last): File "/usr/lib/sabnzbd/sabnzbd/nzbparser.py", line 319, in process_single_nzb nzo = nzbstuff.NzbObject( File "/usr/lib/sabnzbd/sabnzbd/nzbstuff.py", line 778, in __init__ admin_dir = os.path.join(self.download_path, JOB_ADMIN) File "/usr/lib/python3.10/posixpath.py", line 76, in join a = os.fspath(a) TypeError: expected str, bytes or os.PathLike object, not bool
This error also shows up in the logs...
Anyone know what would cause be?
Is your downloads share going to a cache drive?
Are you seeing any errors on that drive? You can check by running this command from your unraid terminal
- btrfs dev stats /mnt/cache
If any of them have a count then try rebooting unraid. Then check to see if you are still getting a count.
Another option you could do is turn off "Use Cache Pool" under Shares > Downloads.
I'm operating under the impression that your /data is mapped to your downloads folder in SAB.
I believe I had this issue as well. I was no longer able to get content from Sonarr and Radarr. Ans I also had those other .py errors as well.
I had a bunch of errors on my cache drive. So I rebooted to see if it was generating any new errors. After the reboot, my cache drive no longer connected.
I had to delete the Downloads share, recreate it (and the incomplete and complete folders within). The reason for this was that SAB showed 0GB Folder. And when I tried to connect to the complete and incomplete folders in SAB it would throw a connection error
Then I had to reinstall SAB because it wasn't connecting and I read somewhere that the Downloads Share needs to be created first before installing SAB.
That resolved my issue
So cliff notes:
- Run '- btrfs dev stats /mnt/cache' to check for errors
- Even if you don't have any, I would still try a reboot
- If cache still shows and no issues were found you can do the following
+ Delete your Downloads share from termlinal. Its probably under /mnt/user/
+ to delete a folder you will need to use the 'rm -r downloads' directory
+ Now remove SAB (Make sure you take a screenshot of the docker settings just in case)
+ Create the new share and the complete and incomplete folders
+ install sab
+ once installed, launch SAB and set it up. Make sure you switch the folders from the default location to /data/incomplete and /data/complete
+ You will need to update the API from SAB on Sonarr and RadarrNow test. Hopefully I am making this clear. Im doing this all from memory.
-
1 hour ago, JorgeB said:
UD mountpoint changed from /mnt/disks/Samsung_SSD_860_EVO_500GB_S59UNJ0N109855F to /mnt/disks/S59UNJ0N109855F, likely due to a UD update, change it back.
P.S. there's filesystem corruption on disk2 and btrfs is detecting data corruption on cache, so good idea to run memtest.

Its the same drive. How do I change it back?
-
I am getting "Docker Image Failed to Start" on the Docker tab
I see this error in the logs
Mar 8 09:54:42 Prometheus emhttpd: shcmd (166): /usr/local/sbin/mount_image '/mnt/disks/Samsung_SSD_860_EVO_500GB_S59UNJ0N109855F/system/docker/docker.img' /var/lib/docker 50
Mar 8 09:54:42 Prometheus root: Creating new image file: /mnt/disks/Samsung_SSD_860_EVO_500GB_S59UNJ0N109855F/system/docker/docker.img size: 50G
Mar 8 09:54:42 Prometheus root: ERROR: failed to zero device '/mnt/disks/Samsung_SSD_860_EVO_500GB_S59UNJ0N109855F/system/docker/docker.img': Input/output error
Mar 8 09:54:42 Prometheus root: btrfs-progs v5.10
Mar 8 09:54:42 Prometheus root: See http://btrfs.wiki.kernel.org for more information.
Mar 8 09:54:42 Prometheus root:
Mar 8 09:54:42 Prometheus root: failed to create file systemI looked in that location and I dont even see the docker.img.
I searched the entire file system for docker.img via terminal with 'find / name docker.img' and it says no file exists
When I look under the Apps tab and try to uninstall docker, docker seems grayed out.
I have attached my diagnostics logs.
-
2 hours ago, tetrapod said:
My first Unraid server have been online for a couple of weeks now and everything have been pretty smooth sailing so far even if I'm a total noob at using anything of the SW listed here under. Thank you Binhex for making it easy (Y)
...until now - everything starting with binhex broke 😞This is what I have running
binhex-delugevpn - bridge - [localhost] .68112,8118,58846,58946
binhex-jackett - bridge - [localhost] .69117
binhex-krusader - bridge - [localhost] .66080
binhex-lidarr - bridge - [localhost] .68686
binhex-plexpasshost - [localhost] .
binhex-radarr - bridge - [localhost] .67878
binhex-sabnzbd - bridge - [localhost] .68080,8090
binhex-sonarr - bridge - [localhost] .68989,9897
Cloudflare-DDNS - bridge - 172.17.0.7
duckdnshost [localhost]???
mariadb - bridge - [localhost] .63306
nextcloud - bridge - [localhost] .6444
ombi - bridge - [localhost] .63579
swag - bridge - [localhost] .6180,1443
tautulli - bridge - [localhost] .68181
I had SWAG setup to use my cloudflare subdomains running with DNS update so the only NAT I have configured is 443 (and the one for PLEX). Worked fine for a week...
So my problem started when, and I have a hard time understanding that it would be because, I changed the log level on sonarr, radarr and lidarr to 'debug' (had som problem with lidarr and was looking for clues), restarted the containers; and now I can't get into the webUI to any binhex dockers (except binhex-plexpasshost). I get a 401 from LAN, and from WAN I get the browser log on messege for the services, but my usr/passwd is not accepted. or I get a 502 from nginx.
Nextcloud, plex, tautulli and ombi are still working which all have the same basic setup as the binex dockers running through swag (where I set all x.subdomain.conf in appdata\swag\nginx\proxy-confs to LAN IP).
So, it's not only binhex-sonarr, but I had to start somewhere. It must be something basic that I overlooked and/or don't understand when so much breaks at the same time 😞
The dockers starts fine, there are no general Error what I can see. I can reach the logfiles and have shell access to the dockers.
Checking the logfiles for sonarr I see I'm running Version 3.0.6.1196 and requesting webUI from Unraid I get this line in the log:
[Info] Auth: Auth-Unauthorized ip [LANpc] url 'http://[localhost]:8989'I have to admit that routing inside Unraid still is a little mysterious for me and I don't quite understand what I'm doing :-$
If you click on the sonarr icon, click on it and go to edit settings, what is the ports for sonarr and what is the puid and pgid? 401 means you are not authorized, as Im sure you are aware. From the ports you provided there are 6's in front of some of your ports. IE SAB, Sonarr, radarr.
-
Hi, So when I search for an episode in Sonarr, for instance bar rescue I see s03E21 but when I click on the manual search button it only shows S04E01.
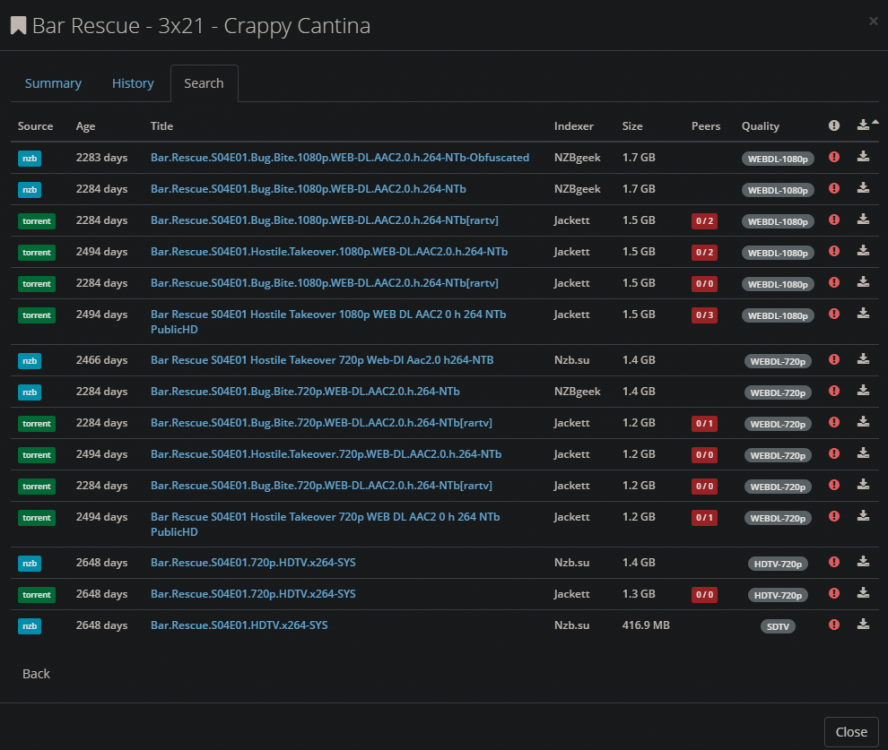
This happens for a few episodes. And when I hover over the red circle it just says that the file is larger than the maximum allowed. It does not say "Wrong Series". I read a post that says refreshing the series in drone fixed this but I think they were running docker on an actual PC and not in unraid.
https://forums.sonarr.tv/t/wrong-season-numbering/1008/8
Can anyone help with getting sonarr to show the correct episodes when I click manual search?
Thanks
-
11 hours ago, opentoe said:
I have been waiting for a while for these drives to drop to $159. It seems only the 10TB are pricey and have no more sales at Newegg or Best Buy. I won't buy a 12TB because then I'd have to ditch my 10TB parity. Wonder why they pretty much disappeared at that price while most all other drives are at least on sale once in a while.
My parity drive was a 12TB and the 14TB easystores were on sale for $189 each. I couldn't pass it up so I bought 2. Then I replaced my 12TB parity drive with the 14TB drive and then moved the 12TB to my array. In your case, sure you're only added 8TB to your array instead of 12TB but it will allow you a wider range of drives to add in the future. So I would say go for it if the higher tb drives have a good price point
-
13 hours ago, binhex said:18 hours ago, Armed Ferret said:
1. How do I access the Minecraft Console through Unraid terminal?
left click icon in deluge unraid web ui, select 'web ui' and enable cheats
This does not work when you sleepct multiplayer. You just join the server. I guess I left that part out.
13 hours ago, binhex said:18 hours ago, Armed Ferret said:2. Is there another way I can get the in-game cheat commands enabled if I cannot access the console?
no.
I actually found a command that works.
1. Launch the unraid terminal
2. Run the following command "docker exec -u nobody -it binhex-minecraftserver screen -r minecraft". replace 'binhex-minecraftserver' with whatever the name of your docker is.
Then the console launches.
Thanks for the help.
-
I moved my Single player world to my minecraft server. It launches fine and all of my buildings are there. Cheats are enabled on the Single Player world. But when I launch the server I am unable to do any commands like changing the game mode. It only gives me a list of the commands in my screenshot.
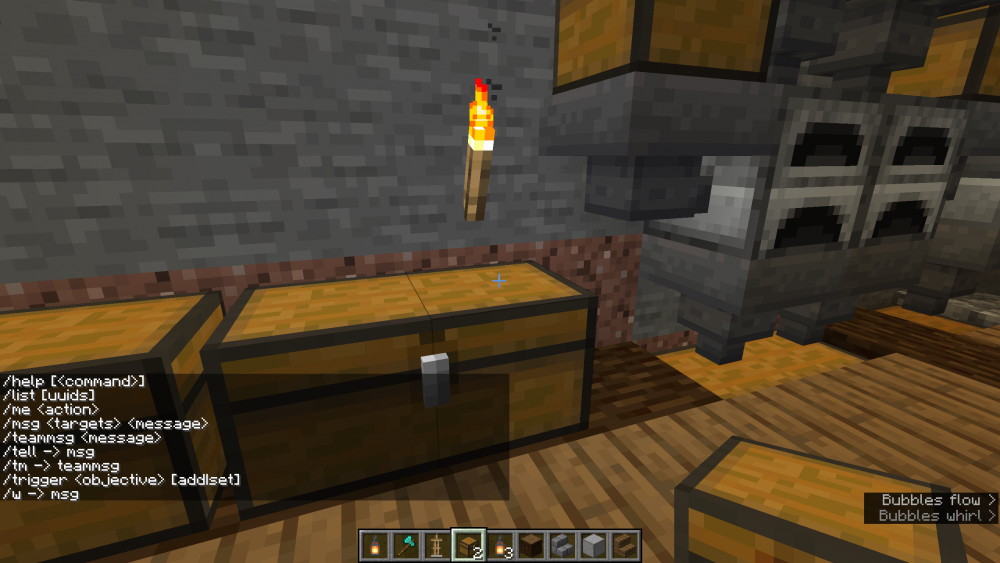
I tried launching the console by using the following command but I get an error.
docker exec -u nobody -it binhex-minecraftserver /usr/bin/minecraftd console
https://github.com/binhex/documentation/blob/master/docker/faq/minecraftserver.md
OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused "exec: \"/usr/bin/minecraftd\": stat /usr/bin/minecraftd: no such file or directory": unknownSo from the error its saying that it doesnt exist there.
Im sure it has to do with me having my appdata on my unassigned devices drive instead of the default location.
I looked in the binhex-mincraftserver folder but cant find the path to the minecraftd
Below is the path to the minecraft folder on my unassigned devices.
/unraid_unassigned_disks/Samsung_SSD_860_EVO_500GB_S59UNJ0N109855F/appdata/binhex-minecraftserver/
What I am looking to do is enable cheat commands on my Minecraft server and the only way I can find is through the console. I am open to other ideas as well.
So summary
1. How do I access the Minecraft Console through Unraid terminal?
2. Is there another way I can get the in-game cheat commands enabled if I cannot access the console?
Thanks
-
Hello, In SABNZBD I am getting "Cannot create backup file for /config/sabnzbd.ini.bak"
I went into the location of the backup file and renamed it to sabnzbd.ini.bak.old. I saw the system created a new sabnzdb.ini backup file but Sab is still throwing the error.
I have the cache saving to an unassigned device SSD instead of the array. I have no issues with SAB except for this error being thrown. Any help would be appreciated.
Thanks
-
10 minutes ago, mikefallen said:
Just bought one of these to shuck and was pleasantly surprised to get a Seagate IronWolf Pro NAS 10TB disk with the model # ST10000NE0008
Western digital offers better deals for 12tb drives. Here's a list of sites and the optimal price to buy them at.
https://forums.serverbuilds.net/t/official-wd-external-shuckables-price-tracking/4995
-
On 3/18/2016 at 4:58 PM, Bjonness406 said:
You cant get sonarr to tell deluge where to downlaod to.
When you are adding a tv show, it say "path" on the bottom, just specify there where you want to download it too.
Like /media
On 3/18/2016 at 4:30 PM, tazire said:I have this up and running now. I'm just curious as to how I get sonarr to tell deluge what folder to download the content to and finally what folder to place completed content in?
or is this even possible for that matter?
In Deluge if you enable Labels through Plugins then it will add the TV or Movie Label. Thats how it knows where to move the media to.
-
Nevermind. For some reason Unraid did not like my static IP. When I switched it to DHCP that fixed the issue.
-
Hello,
I am not getting this error.

There are two things I recently did that could have caused this.
1. A few days ago I tried moving my docker.img to an unassigned device drive. I never deleted the docker image from its default location and didnt run any commands to move it except Rsync to transfer the file and I changed the docker path under the docker setting. However, I did not notice a Fix Common Problems Error at the time.
2. I added a 10GBE nic. When I added the NIC it obviously changed my IP address. In my router from ATT (bgw210-700) I had a reservation for my IP address. I removed the reservation and anything associated with that device under NAT/GAMING but when I try to assign the new NIC the same IP address, the IP address is missing from the list. So to work around this I statically assigned it an IP address. I pointed the Gateway and DNS to my router. Still got the error so I switched DNS to google dns 8.8.8.8.
I am still getting this error. How do I fix this?
-
I switched it to 2.6 and uninstalled and reinstalled on 2.6 as well. I tried 2.7 and the if drivers as well. 2.6 is the only one that gives me the guest has not installed the display. The rest get stuck on the boot screen.
-
11 hours ago, Abzstrak said:
set your machine type to q35-2.6, its due to old qemu drivers in pfsense.
I switched it to q35-2.6 and I get the following when launching VNC.
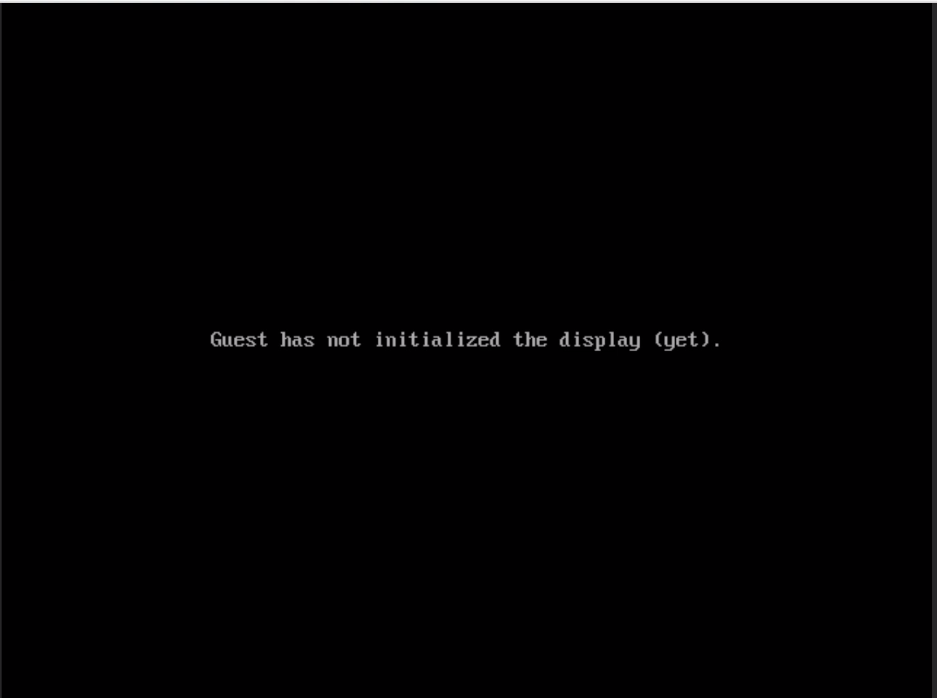
I tried 2.7 and it reverts back to the original issue. Stuck on the boot screen. I have attached log.
Also I am using a Ryzen 2700X for my CPU if that matters.
-
Hello. When I launch PFSense for the first time I get stuck on the black screen where it says booting... and nothing else happens
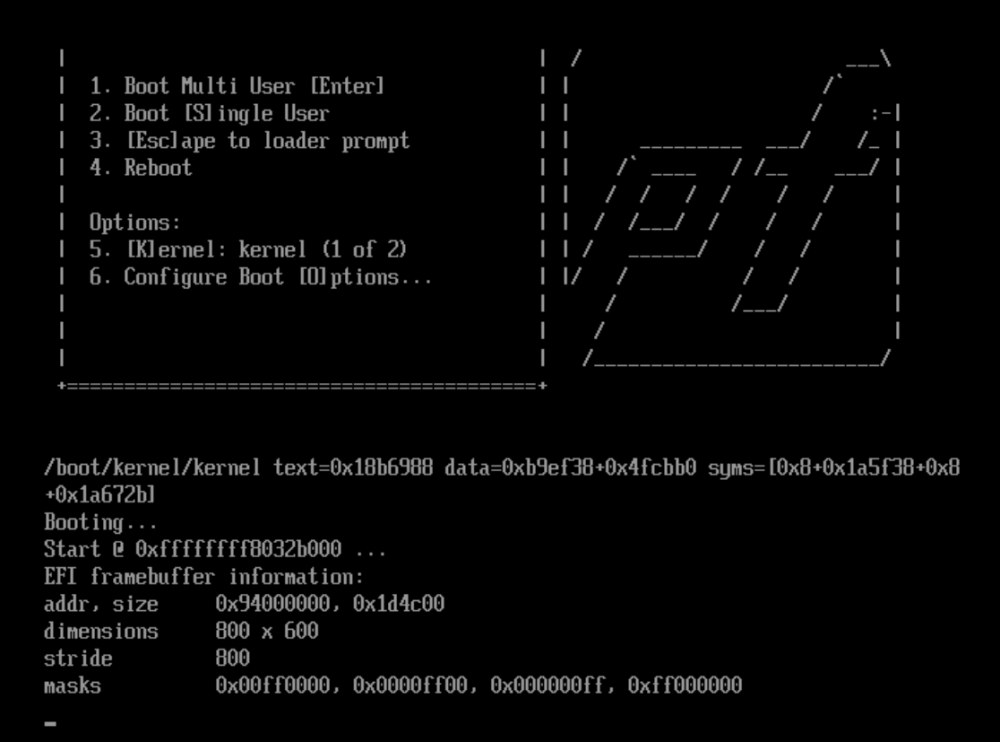
I see the following errors in the pfsense logs
2020-05-24 02:05:07.735+0000: Domain id=1 is tainted: high-privileges 2020-05-24 02:05:07.735+0000: Domain id=1 is tainted: host-cpu char device redirected to /dev/pts/0 (label charserial0) 2020-05-24T02:05:18.252838Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:08:00.0 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.254745Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:09:00.0 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.256320Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:08:00.1 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.257872Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:09:00.1 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile=I did some searches and someone mentioned it has to do with the CPU pinning but I pinned 2 threads on 1 core. I even tried switching the pinning to a different core. I had 1 and 7 pinned but now I have 5 and 11.
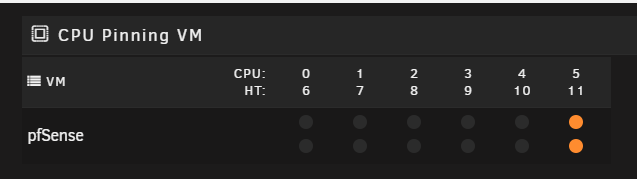
So Im a little lost here. I used the vfio plugin to get passthrough working. I also had to enable ACS override to get the IOMMU groups broken up.
Here is my pfsense VM config
Part 1
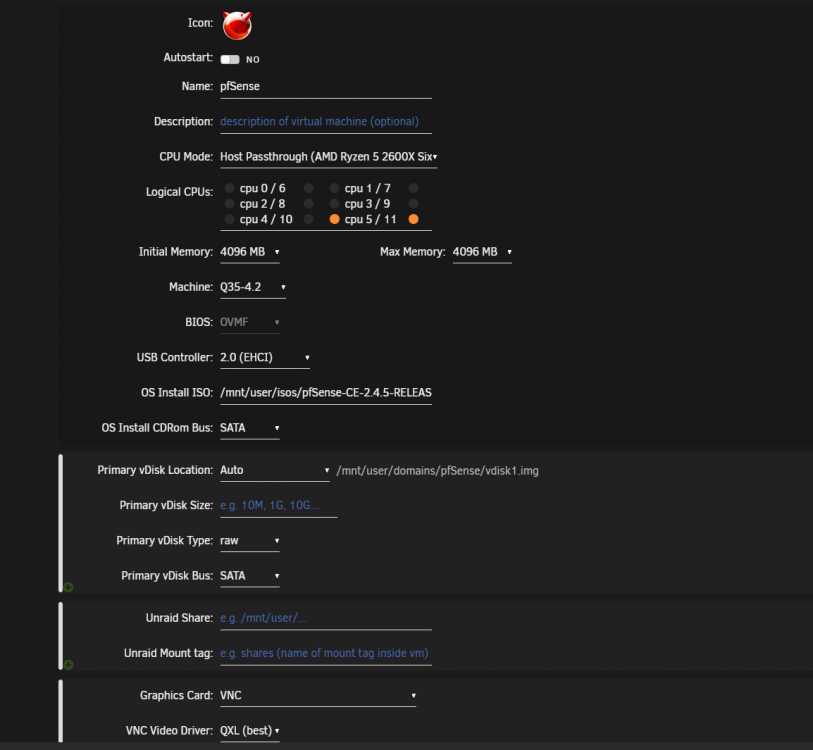
Part 2
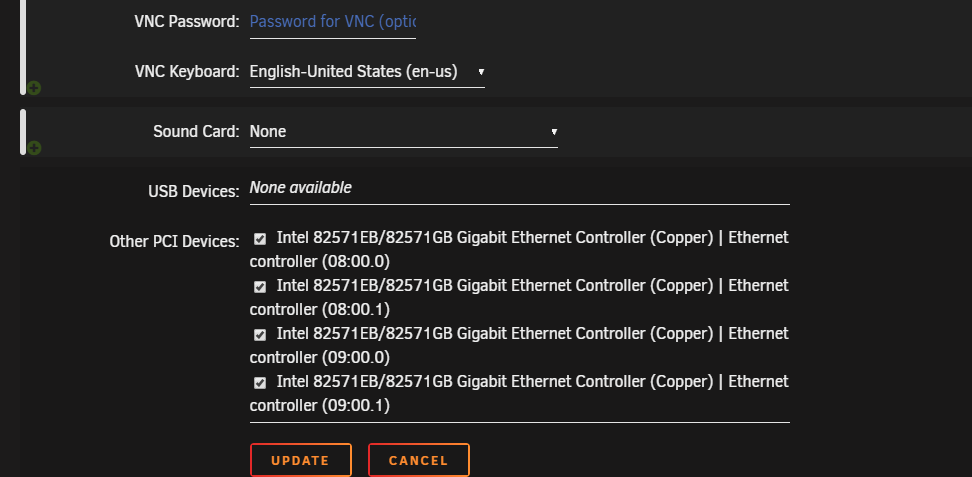
I asked on the pfSense thread but nobodw was responding.
I have attached my pfsense logs and my IOMMU group in txt files.
Any help would be appreciated.
-
I am curious why this is happening. I have log rotation enabled for my dockers. I checked the mappings of deluge and sabnzbd and all of the mappings in the docker settings match the completed and incomplete file locations. In krusader it shows 2GB after emptying the trash.
What else could it be?
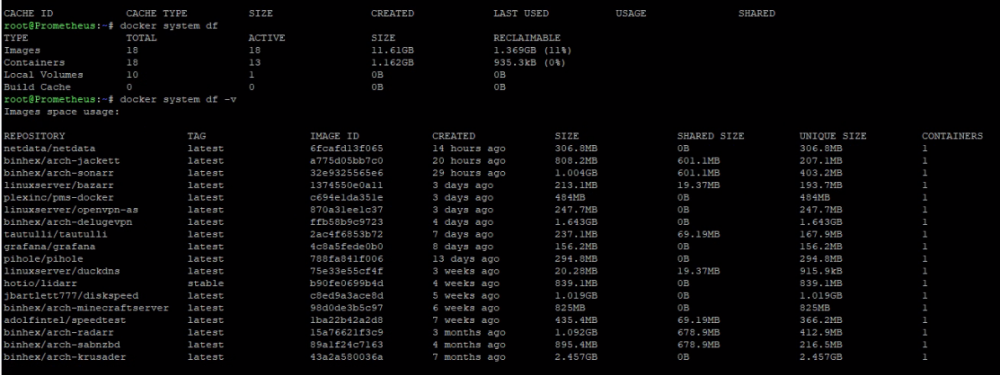
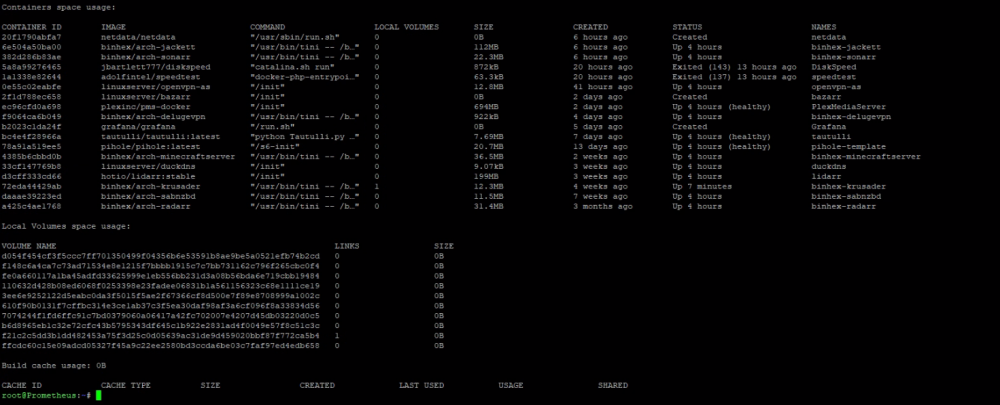
-
Hello. When I launch PFSense for the first time I get stuck on the black screen where it says booting... and nothing else happens.
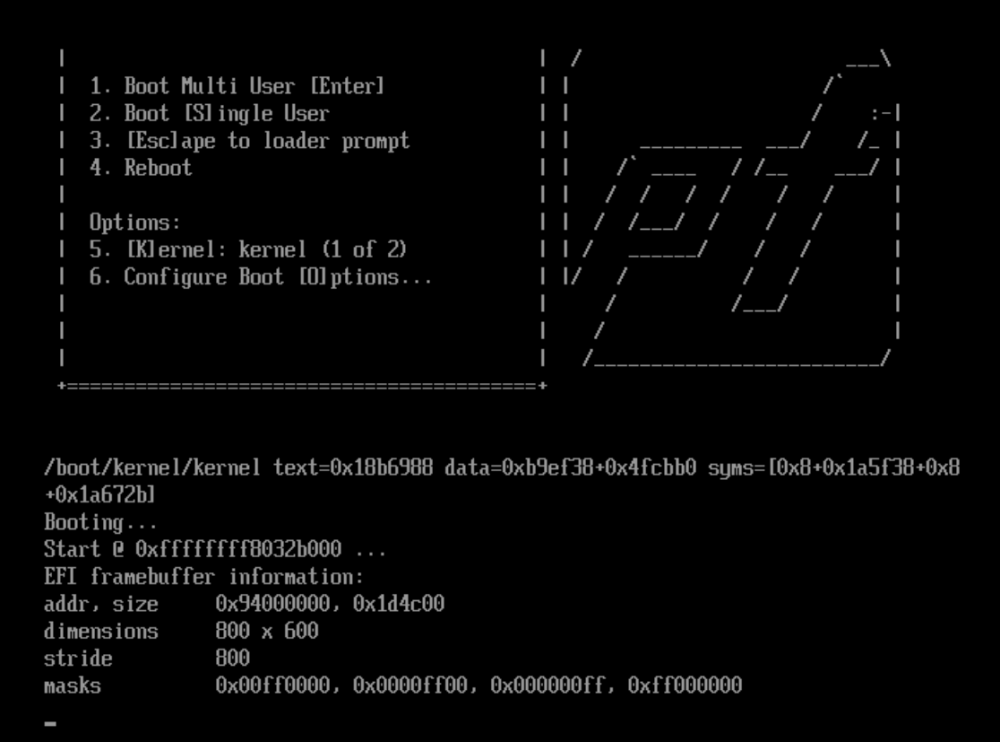
I have attached my logs from my PFsense Vm. I see the following errors
2020-05-24 02:05:07.735+0000: Domain id=1 is tainted: high-privileges 2020-05-24 02:05:07.735+0000: Domain id=1 is tainted: host-cpu char device redirected to /dev/pts/0 (label charserial0) 2020-05-24T02:05:18.252838Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:08:00.0 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.254745Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:09:00.0 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.256320Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:08:00.1 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile= 2020-05-24T02:05:18.257872Z qemu-system-x86_64: vfio-pci: Cannot read device rom at 0000:09:00.1 Device option ROM contents are probably invalid (check dmesg). Skip option ROM probe with rombar=0, or load from file with romfile=I did some searches and someone mentioned it has to do with the CPU pinning but I pinned 2 threads on 1 core. I even tried switching the pinning to a different core. I had 1 and 7 pinned but now I have 5 and 11.
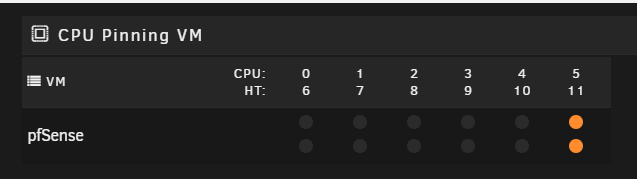
So Im a little lost here. I used the vfio plugin to get passthrough working. I also had to enable ACS override to get the IOMMU groups broken up.
Here is my pfsense VM config
Part 1
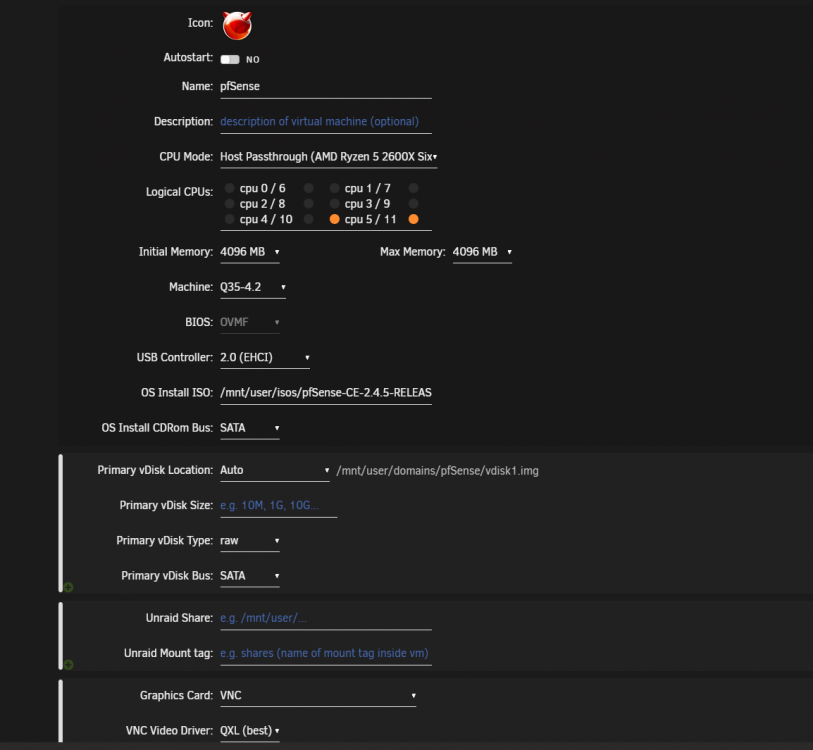
Part 2
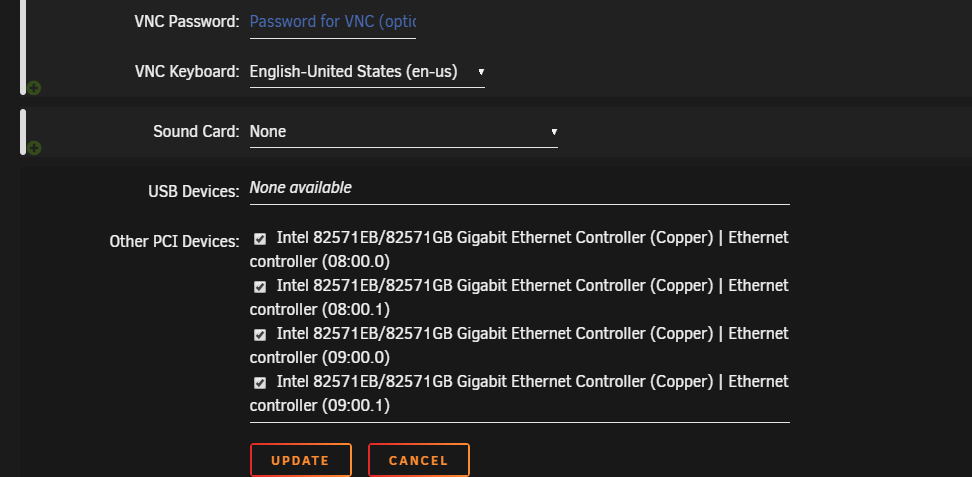
I have attached my pfsense logs and my IOMMU group in txt files.
Any help would be appreciated.
-
Does anyone have some optimal settings for deluge for speed?
These are my settings but the speeds are very slow :

-
The Server fans and PSUs are loud. There is a Quieter version. Model PWS-920P-SQ. You could verify what model the PSUs are but I bet its the 1R brand
This video covers making it quiet.
-
On 5/13/2020 at 4:47 AM, T0a said:
Does maybe this thread help:
Symptoms are the same
So it helps some. However, to me, its not as clear.
This is what is in my XML for the two ports that are currently being passed
<hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x08' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </hostdev>
When I look up the other two I want to pass here are their info:
08:00.0 0200: 8086:10bc (rev 06)
08:00.1 0200: 8086:10bc (rev 06)
09:00.0 0200: 8086:10bc (rev 06)
09:00.1 0200: 8086:10bc (rev 06)Now I get I should be changing the bus to 0x09 for the other two. But I am not sure what else I need to change? Im guessing I would need to set one to function 0x01. But on the second source like there is bus 0x03 and 0x04. Do I need to change those?

















Cache drive won't mount
in General Support
Posted
Hello,
My docker.img stopped suddenly. After looking through the logs, I noticed my cache drive was full. When I hit mover, nothing would happen (mover has worked in the past.). I saw this error in the diagnostic logs for my cache drive:
Feb 4 21:05:18 Prometheus root: mount: /mnt/cache: wrong fs type, bad option, bad superblock on /dev/nvme0n1p1, missing codepage or helper program, or other error. Feb 4 21:05:18 Prometheus root: dmesg(1) may have more information after failed mount system call. Feb 4 21:05:18 Prometheus emhttpd: shcmd (12122): exit status: 32 Feb 4 21:05:18 Prometheus kernel: XFS (nvme0n1p1): Invalid superblock magic numberAlso, the smart test wouldn't run on the cache drive.
I tried removing the cache from the array and adding it back to see if it would do a file system check and possibly fix it. It didn't. Any help would be appreciated.
Thanks
Unconfirmed 319673.crdownload