

mgutt
-
Posts
11265 -
Joined
-
Last visited
-
Days Won
123
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by mgutt
-
-
Changed Status to Solved
-
This bug will be solved with Unraid 6.12. I tested it with the rc Version and the Mover now moves symlinks, too.
-
To collect more feedback for the Go file code, I started a new thread here:
Note: This is a new version. The very first release caused in rare cases multiple mounts on the same path, which caused a stalling server.
-
This bug is still present. In the last weeks there were 2 german users, which wanted to empty their SSD through the Mover, but it fails, because the Mover can't move symlinks.
Example:https://forums.unraid.net/topic/134766-cache-uncorrectable-errors/#comment-1226519
-
On 11/12/2022 at 4:05 PM, bonienl said:
I have created a nchan monitoring script which will terminate the running nchan processes when no more subscribers are present.
Thank you! Works flawlessly:
root@Tower:~# pgrep -af http 3337 /usr/local/sbin/emhttpd 4334 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/notify_poller 4336 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/session_check 4338 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/device_list 4340 /bin/bash /usr/local/emhttp/webGui/nchan/disk_load 4342 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/parity_list 4487 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/wg_poller 4489 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_1 4491 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_2 4493 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_3 # browser closed, some seconds later... root@Tower:~# pgrep -af http 3337 /usr/local/sbin/emhttpd root@Tower:~#
-
 1
1
-
-
13 hours ago, Enks said:
but I'll try the described start/stop mechanism
Will not work as I already explained. If you open the dashboard and close the window, it never fires the stop mechanism.
-
6 hours ago, bonienl said:
saves me 1W
Maybe valid for your system, but mine consumes 3 or 4W more or in other words 30 to 40% more than with Unraid 6.9. For me it's a huge deal breaker. I will not udpate as long this isn't fixed.
-
Ok, I can reproduce the spikes and "solve" the issue as follows:
- Reboot server
- connect through SSH and execute the following (= returns only a single process)
root@Tower:~# pgrep -af emhttp 1835 /usr/local/sbin/emhttpd
- open the WebGUI
- open the Main page
- open the Dashboard
- close the Browser
- now the following 10 Bash and PHP scripts stay open and the power consumption raises by several watts and is fluctuating
root@Tower:~# pgrep -af emhttp 1835 /usr/local/sbin/emhttpd 10100 /bin/bash /usr/local/emhttp/webGui/nchan/disk_load 10240 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/notify_poller 10242 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/session_check 10360 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/device_list 10514 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/ups_status 10364 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/parity_list 10506 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/wg_poller 10508 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_1 10510 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_2 10512 /usr/bin/php -q /usr/local/emhttp/webGui/nchan/update_3
- now I kill all scripts and remove the pid file:
pkill -cf /usr/local/emhttp/webGui/nchan rm /var/run/nchan.pid
- power consumption is low and stable (does not show any spikes)
- until... opening the WebGUI again, which restarts all the above scripts
Note: The script /usr/local/emhttp/webGui/nchan/ups_status is the only one which is automatically stopped, but only if you load an additional WebGUI page after visiting the Dashboard. If you directly close the browser, it will run forever, too.
@bonienl ich777 said I should notify you 😉
-
 3
3
-
-
On 6/19/2022 at 1:06 PM, mgutt said:
This should be fixable by editing /usr/local/sbin/in_use and adding this:
[[ -L "$file" ]] && exit 1 # ignore symlinks
I'm testing this for a while now. Sadly it only avoids the error message, but the symlink is still not moved. If I enable the mover logs, it returns this, now:
Aug 5 23:00:11 thoth move: move: skip /mnt/cache/Backups/Shares/appdata/20220731_044024/plex/Library/Application Support/Plex Media Server/Metadata/Artists/8/d45a63406b0ffd7d7558edc16e5e1b232cbccf1.bundle/Contents/_combined/posters/tv.plex.agents.music_b2d667cd09e7ce58d93780d1eb32630ed9cf61e0 [10301,88e801e1] /Backups/Shares/appdata/20220630_044049/plex/Library/Application Support/Plex Media Server/Metadata/Artists/8/d45a63406b0ffd7d7558edc16e5e1b232cbccf1.bundle/Contents/_combined/posters/tv.plex.agents.music_b2d667cd09e7ce58d93780d1eb32630ed9cf61e0 [-1]
There must be an additional problem in /usr/local/sbin/move. Sadly it's a binary file, so I can't help any further (limetech needs to solve this).
-
-
This should be fixable by editing /usr/local/sbin/in_use and adding this:
[[ -L "$file" ]] && exit 1 # ignore symlinks
before this:
fuser -s "$FILE" && exit
At the moment I'm testing this in the go-file:
# ------------------------------------------------- # Workaround for mover bug (tested with Unraid 6.9.2, 6.11.2, 6.11.3) # https://forums.unraid.net/bug-reports/prereleases/690-rc2-mover-file-does-not-exist-r1232/ # ------------------------------------------------- if md5sum --status -c <<<"01a522332c995ea026c6817b8a688eee /usr/local/sbin/mover" || md5sum --status -c <<<"0a0d06f60de4a22b44f634e9824245b6 /usr/local/sbin/mover"; then sed -i '/shareUseCache="yes"/a\ \ \ \ \ \ \ \ find "${SHAREPATH%/}" -type l -depth | \/usr\/local\/sbin\/move -d $LOGLEVEL' /usr/local/sbin/mover fi It fixes-
1
-
-
9 hours ago, ncoolidg said:
Is there any development on fixing this issue with small files?
There are different solutions to enhance performance (impact descending):
- enable SMB Multichannel + RSS (this enables multi-threading, which allows transferring multiple files simultaneously instead of only one by one, which is the default in Windows, but not with Linux)
- use Disk Shares instead of User Shares (which avoids Unraid's "FUSE (sshfs) overhead", which can be massive)
- enable case-sensitivity (this allows co-existence of "photo.jpg" and "Photo.jpg" in the same directory, but makes SMB much faster handling a huge amount of files)
- upload to an SSD Cache Pool instead of the Array (>1Gbit/s vs ~0.5Gbit/s)
- install more RAM and raise the Write-Cache with Tips & Tweaks Plugin to 50 - 80%
- use a faster CPU
- do not use encryption
- do not use a CoW filesystem like BTRFS or ZFS (write amplification = slower than usual filesystems)
-
Opening the link to view the content of a disk became better, but finally the bug is still present (this shows the most worst example, most of the time I was successful):
It seems, you reduced the interval of rebuilding the dashboard content. Why do you rebuild the full content at all? Wouldn't it be better to update only those data which has really changed, like for example the temperature of a disk or the disk usage? By that the link itself wouldn't rebuild all the time. Or you update it only after the AJAX call received new data. By that it would reduce the chance to "click at the wrong moment" much more.
-
This bug seems to be present for a long time:
On 4/9/2022 at 3:29 PM, bonienl said:When using Unraid 6.10-rc3 or later, you can use the Dynamix File Manager to move files around.
For me its a daily situation (backups) when symlinks are created. So a manually move is not practical.
-
Interface rules missing until network-rules.cfg has been created manually:
-
SSH / Terminal is dead
Apr 11 20:49:59 Tower webGUI: Successful login user root from 192.168.178.25 Apr 11 20:50:11 Tower kernel: Bluetooth: Core ver 2.22 Apr 11 20:50:11 Tower kernel: NET: Registered PF_BLUETOOTH protocol family Apr 11 20:50:11 Tower kernel: Bluetooth: HCI device and connection manager initialized Apr 11 20:50:11 Tower kernel: Bluetooth: HCI socket layer initialized Apr 11 20:50:11 Tower kernel: Bluetooth: L2CAP socket layer initialized Apr 11 20:50:11 Tower kernel: Bluetooth: SCO socket layer initialized Apr 11 20:51:04 Tower nginx: 2022/04/11 20:51:04 [crit] 3589#3589: *7931687 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower", referrer: "http://tower/Settings/ManagementAccess" Apr 11 20:51:07 Tower nginx: 2022/04/11 20:51:07 [crit] 3589#3589: *7931687 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower" Apr 11 20:51:44 Tower nginx: 2022/04/11 20:51:44 [crit] 3589#3589: *7932666 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower", referrer: "http://tower/Tools/Syslog" Apr 11 20:51:46 Tower nginx: 2022/04/11 20:51:46 [crit] 3589#3589: *7932666 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower" Apr 11 20:52:49 Tower nginx: 2022/04/11 20:52:49 [crit] 3589#3589: *7933928 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower", referrer: "http://tower/Dashboard" Apr 11 20:53:07 Tower nginx: 2022/04/11 20:53:07 [crit] 3589#3589: *7933928 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower", referrer: "http://tower/Dashboard" Apr 11 20:54:12 Tower emhttpd: shcmd (80479): /usr/local/emhttp/webGui/scripts/update_access Apr 11 20:54:12 Tower sshd[3466]: Received signal 15; terminating. Apr 11 20:54:13 Tower emhttpd: shcmd (80480): /etc/rc.d/rc.nginx reload Apr 11 20:54:13 Tower root: Checking configuration for correct syntax and Apr 11 20:54:13 Tower root: then trying to open files referenced in configuration... Apr 11 20:54:13 Tower root: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok Apr 11 20:54:13 Tower root: nginx: configuration file /etc/nginx/nginx.conf test is successful Apr 11 20:54:13 Tower root: Reloading Nginx configuration... Apr 11 20:54:16 Tower nginx: 2022/04/11 20:54:16 [alert] 3589#3589: *7935181 open socket #4 left in connection 5 Apr 11 20:54:16 Tower nginx: 2022/04/11 20:54:16 [alert] 3589#3589: *7935187 open socket #16 left in connection 8 Apr 11 20:54:16 Tower nginx: 2022/04/11 20:54:16 [alert] 3589#3589: aborting Apr 11 20:54:28 Tower emhttpd: shcmd (80483): /usr/local/emhttp/webGui/scripts/update_access Apr 11 20:55:15 Tower nginx: 2022/04/11 20:55:15 [crit] 30158#30158: *7935815 connect() to unix:/var/run/ttyd.sock failed (2: No such file or directory) while connecting to upstream, client: 192.168.178.25, server: , request: "GET /webterminal/ttyd/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "tower", referrer: "http://tower/Settings/ManagementAccess"
I'm not using this server for other things except testing.
-
Some users mentioned the touch problems to open share/disk content. This is not related to mobile devices I think, it's a general problem. Opening the content of a disk on the first click is a 50:50 chance as the html source code seems to be rebuilded every ~0.2 seconds which avoids clicking the icon:
PS why was the icon changed to an external link icon?! Please use the directory icon again. It makes much more sense.
-
1
-
-
I'm facing the same problem:
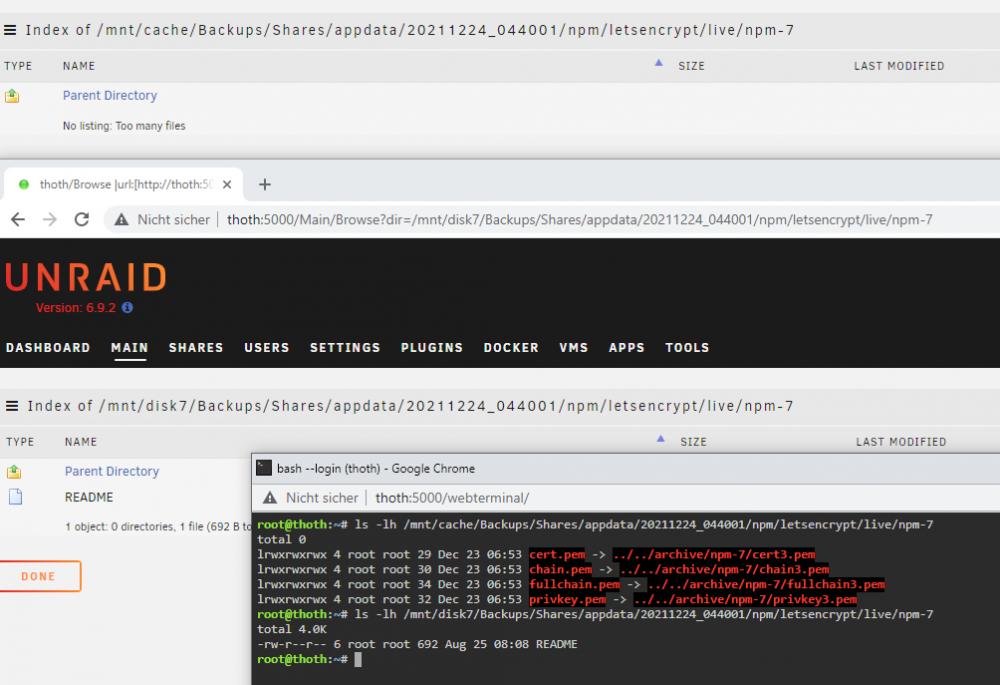
After enabling the logs it says these files do not exist:
Dec 27 13:29:21 thoth root: Specified filename /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/cert.pem does not exist. Dec 27 13:29:21 thoth move: move: file /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/cert.pem [10301,c50fbc1c] Dec 27 13:29:21 thoth move: move_object: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/cert.pem No such file or directory Dec 27 13:29:21 thoth root: Specified filename /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/chain.pem does not exist. Dec 27 13:29:21 thoth move: move: file /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/chain.pem [10301,c50fbc1d] Dec 27 13:29:21 thoth move: move_object: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/chain.pem No such file or directory Dec 27 13:29:21 thoth root: Specified filename /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/fullchain.pem does not exist. Dec 27 13:29:21 thoth move: move: file /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/fullchain.pem [10301,c50fbc1e] Dec 27 13:29:21 thoth move: move_object: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/fullchain.pem No such file or directory Dec 27 13:29:21 thoth root: Specified filename /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/privkey.pem does not exist. Dec 27 13:29:21 thoth move: move: file /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/privkey.pem [10301,c50fbc1f] Dec 27 13:29:21 thoth move: move_object: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/privkey.pem No such file or directory
But I have a different dir which contains links, which were moved:
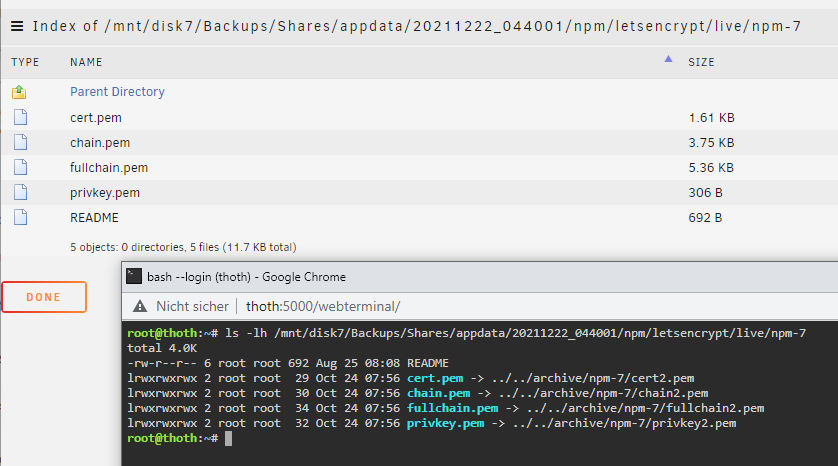
The red color means that the symlinks target does not exist. This means the mover already moved the target file. Maybe the mover has a bug which fails because of that?
There are other commands in Linux which fail with the same error:
getfattr --dump /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/* getfattr: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/cert.pem: No such file or directory getfattr: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/chain.pem: No such file or directory getfattr: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/fullchain.pem: No such file or directory getfattr: /mnt/cache/Backups/Shares/appdata/20211224_044001/npm/letsencrypt/live/npm-7/privkey.pem: No such file or directory
getfattr needs an additional flag to check the symlink itself:
-h, --no-dereference Do not dereference symlinks. Instead of the file a symlink refers to, the symlink itself is examined. Unless doing a logical (-L) traversal, do not traverse symlinks to directories.
Is it possible that the Unraid Mover uses this command or a similar one?
EDIT1: Yes, that is the problem. Because if I copy the symlink target files back to the cache, the mover now moves the symlinks to the array (but skips the duplicated files, which is an expected behavior).
EDIT2: One "bug" is this "fuser" command in file /usr/local/sbin/in_use:
fuser -s "$FILE" && exit
fuser fails if the file does not exist, and as it follows symlinks, it does fail:
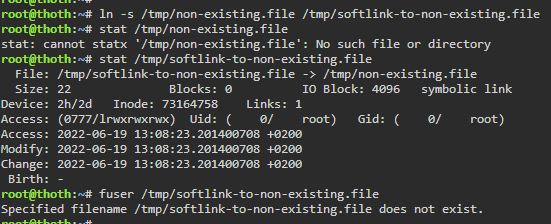
So Limetech should use something like this instead, to avoid in-use checks for symlinks as symlinks can't be in-use at all:
[[ -L "$FILE" ]] && exit 1
-
2
-
-
8 minutes ago, Hank Moody said:
I'm running 6.10RC2 and I can't transfer single 10kb files onto shares without reestablishing the connection ultiple-times. SSH (winscp) doesn't work well currently too. Tried with different shares and settings, rebooting the server, this is driving me nuts.
You problem is different. Nobody in this topic suffers from reconnects.
-
On 8/12/2021 at 1:15 AM, limetech said:
Your syslog from diags report that ACPM is enabled...
I think around this lies the problem.
One of my servers has "perfectly" working ASPM (without setting any additional Kernel options):
lspci -vv | awk '/ASPM.*?abled/{print $0}' RS= | grep --color -P '(^[a-z0-9:.]+|ASPM.*?abled)' 00:01.0 PCI bridge: Intel Corporation 6th-10th Gen Core Processor PCIe Controller (x16) (rev 07) (prog-if 00 [Normal decode]) LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 00:1b.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #17 (rev f0) (prog-if 00 [Normal decode]) LnkCtl: ASPM L0s L1 Enabled; RCB 64 bytes, Disabled- CommClk- 00:1c.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #1 (rev f0) (prog-if 00 [Normal decode]) LnkCtl: ASPM L0s L1 Enabled; RCB 64 bytes, Disabled- CommClk- 00:1c.5 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #6 (rev f0) (prog-if 00 [Normal decode]) LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 00:1d.0 PCI bridge: Intel Corporation Cannon Lake PCH PCI Express Root Port #9 (rev f0) (prog-if 00 [Normal decode]) LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 01:00.0 Ethernet controller: Aquantia Corp. AQC107 NBase-T/IEEE 802.3bz Ethernet Controller [AQtion] (rev 02) LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ 04:00.0 Ethernet controller: Intel Corporation I210 Gigabit Network Connection (rev 03) LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+ 05:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd NVMe SSD Controller SM981/PM981/PM983 (prog-if 02 [NVM Express]) LnkCtl: ASPM L1 Enabled; RCB 64 bytes, Disabled- CommClk+But its syslog claims the opposite?! Why does FADT return the wrong ASPM capabilities?
ACPI FADT declares the system doesn't support PCIe ASPM, so disable it
And I have a different server which does not return this message in the syslog, but all its devices return "ASPM Disabled", although it's enabled in the BIOS (and enabled, when using Ubuntu). Even "pcie_aspm=force" doesn't change anything. Only setpci works.
For me it sounds like a driver is missing?!
Maybe this script helps to enable ASPM automatically:
-
Can confirm this behavior.
-
29 minutes ago, JonathanM said:
Occasionally we see people manually updating or adding things to their containers
No pity with these ^^
-
 2
2
-
-
3 hours ago, Oreonipples said:
I'm just not in the mood to setup all my dockers again right now.
Don't need to. Change to Dir and then Apps > Previous Apps to install them as before. The only thing what happens is re-downloading the packages. Any if you created such, you need to recreate custom networks. But you don't need to change templates or similar things. The docker.img does not contain any important data.
-
2 hours ago, Oreonipples said:
thinking maybe its that my drive is btfrs as this is higher than it was without this on my xfs cache drive
It will be less with XFS, but 12MB/s (sure?!) is too much for writes to log files. Your problem lies somewhere else.






Kworker 100cpu bug fixed with go code
in Stable Releases
Posted
This returns only relevant gpe interrupts: