

-
Posts
14 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by SOULV1CE
-
Is redirecting to https when inputting a URL with http a known issue for the WebUI? I saw one previous comment asking about this back in January but havent seen anything since. My example: I put in this for WebUI label: http://[IP]:[PORT:8443]/ When I click WebUI on the container it goes to https://10.0.0.100:8443/
-
Thanks for this! I think it might not be necessary to have to define net.unraid.docker.managed: "composeman" because I saw it already existed by default in the docker-compose.override.yml that gets created for a project. Also I just want to mention that it works fine with using environment variables to define these as well - my setup is working correctly like this with the actual values defined in a .env file: net.unraid.docker.shell: ${LABEL_SHELL} net.unraid.docker.icon: ${LABEL_ICON_CODE-SERVER} net.unraid.docker.webui: ${LABEL_WEBUI_CODE-SERVER} Setting external: false did not work for me for an already created network in Unraid - when I tried to do this I got the error: However using network_mode: "skynet" was successful.
-
Thanks for this comment. I made some further progress and will share to make it more Unraid friendly. To add WebUI option for the container we can toggle Advanced View and add the following to the WebUI section http://[IP]:[PORT:8090]/ The icon URL can also be updated from the Advanced View, you are right that it wont display in the native format from Github (I think it was .svg or something). Instead I just updated used the icon from this page which is saved as .png. Also I enjoyed the little QR code Easter Egg from this one https://forums.unraid.net/uploads/monthly_2023_04/gopher.thumb.png.7ca4e3809e310e5a43056ab4aa6b6080.png I added the following to the Post Arguments for my system to redirect to the correct IP address for the PocketBase Admin UI. The default URL goes to 0.0.0.0. --http 10.0.0.100:8090 Along with your mention of adding a path mapping for database persistence, I also added the container port variable in case I need to change the host port, and also the timezone and IP scan range. These can be changed within the application as well I noticed afterwards, but I would rather have them set in the container. Here is a screenshot of my setup in case this will help anyone else in their configuration:


-
 All disks connected through Supermicro backplane to HBA connected to motherboard. I can see operating lights on HBA and it is getting power, maybe something happened to it? I think I have another HBA I can swap out to see if that is the problem. Thank you for the quick response to my post.
All disks connected through Supermicro backplane to HBA connected to motherboard. I can see operating lights on HBA and it is getting power, maybe something happened to it? I think I have another HBA I can swap out to see if that is the problem. Thank you for the quick response to my post. -
Shows no device for all of my drives. Diagnostics attached. Any help is appreciated thank you. omnius-diagnostics-20230526-1028.zip

-
I just solved a problem I was having with adding the PAPERLESS_TRASH_DIR parameter that I wanted to share. As mentioned in the Paperless documentation the default value of this parameter is "Defaults to empty (i.e. really delete documents)." Because it is empty it is never mapped to any container path - I verified this by looking in the /paperless.conf.example and src/paperless/settings.py file. So because of this you first need to create a container variable for PAPERLESS_TRASH_DIR and map it to a container path such as /usr/src/paperless/media/trash because nothing is ever defined for this. Now that we have defined the variable to the container path, we can then proceed with mapping the container path /usr/src/paperless/media/trash to a host path such as /mnt/user/data/media/documents/paperless-ngx/media/trash/. Finally after doing this when deleting a file it should be moved to the host path folder /mnt/user/data/media/documents/paperless-ngx/media/trash/ and not be permanently deleted.

-
I just set this up right now and got the webUI to load. After initial pull I noticed the container stopped so I went into the logs and saw the following error: I then referenced this section of the pgAdmin docs and ran the following command in my Unraid terminal to set the needed permissions for the pgadmin user: sudo chown -R 5050:5050 /mnt/user/appdata/pgadmin4 Now when I went to start up the pgadmin4 container again all was successful and the webUI launched successfully. Hope this helps! Also I just noticed that after I typed all of this out @dreadu posted the same solution before me back in June 2022 that I completely missed because scatter brain🤦♂️ Leaving this comment up in case others are like me who miss it as well!
-
Ok thank you for the explanation! I have a BPN-SAS3-846EL1 backplane using both the J49 and J50 connections to a single LSI 9300-16i HBA. I unplugged ports 2 & 3 on the HBA. So just for me to be 100% clear, there is no redundancy benefit for me to plug these back in because this is not supported in Unraid?


-
Yes I have dual channel transmission cables from my backplane to HBA. I shutdown, unplugged one of the cables, rebooted and now magically the VM cache pool is valid again! So it seems it was something with the dual channel that was causing the issue maybe? Is it ok to plug in the second cable again? New diags are attached. omnius-diagnostics-20230106-0926.zip
-
I have cache pool of 5 SSDs for VMs. I was trying to set up iGPU passthrough and ran into some errors. Here is what happened: set graphics card to iGPU in VM template went to Intel GVT-g plugin and assigned a mode to VM tried to start VM but just kept trying to start, wasnt seeing any relevant info in logs tried to reboot server but nothing was happening - probably waited 20 minutes or so did a hard shutdown as I wasnt getting anywhere when server came back up, a parity check started but I cancelled it and then I saw the invalid pool config error since the pool was unmountable, i couldnt edit the VM config to set the graphics card back to VNC so I turned off VM Manager, rebooted again, but did not fix the issue. Ive also removed the assigned VM from Intel GVT-g plugin Diagnostics are attached. I do have a VM backup (untested though as I just took it today) but I would prefer to try and fix the issue instead of reformatting if possible. Appreciate any advice on next steps. Thank you for reading. Edit: Was searching around and tried the following - I stopped the array, unassigned the drives, started the array, stopped, and then re-added the drives and started again. Now I have a different error "Unmountable: No pool uuid". I rebooted to see if this would fix at all but it did not. omnius-diagnostics-20230105-1751.zip
-
[Solved] PERC H310 causing system not to boot
SOULV1CE replied to master.h's topic in Storage Devices and Controllers
This post saved my bacon. Works with my Dell PERC H200 on Gigabyte G1.Sniper 5 motherboard. -
Does anybody have an idea why my F@H will not use more than 2 CPU cores when I have 24 available? I can't figure out why it is not using the rest of them. I am using the latest LSIO docker. I have tried all of the following below with no success: New installation with default configuration, no CPU pinning Changing power from MEDIUM to FULL CPU pinning to specific cores (CPU 2 - 10 HT; 18 total) Specifying the number of cores (18) in config.xml When I look in the F@H container log I can see that it recognizes my CPU correctly as it shows the following: Here is what my config.xml file looks like. Any advice or ideas would be very much appreciated I am pretty stumped.
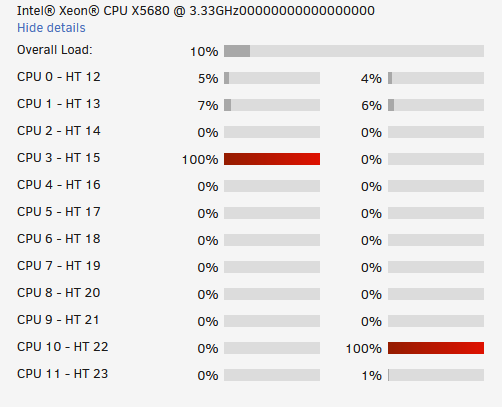
-
Unraid 14th Birthday Case Badge Giveaway
SOULV1CE replied to SpencerJ's topic in Unraid Blog and Uncast Show Discussion
Case badges look awesome. Thanks for making such a fun and great product!








