

razierklinge
-
Posts
18 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by razierklinge
-
-
On 10/21/2022 at 12:31 PM, squish102 said:
I have a similar problem that I cannot log into iMessage. It will log in and then drop me back to the login screen. I have tried and will continue to try the workarounds with eth0 but they don't seem to work.
I had this exact issue. Triple checked that I followed every step correctly and got nowhere. Ended up having to call Apple to "authorize" my account. If you run iMessage through terminal using:
sudo /System/Applications/Messages.app/Contents/MacOS/Messages
You'll get an ID number that you give the customer service rep and they'll basically unlock your account and iMessage will magically work. It took me multiple calls to get someone who knew where to put that number. I mentioned a few times that I believed my account was locked and finally the person figured it out.
Edit: Also, they'll try to get you to let them remote into your Mac. Just say you arent in front of it at the moment or aren't able to for whatever reason. Them remoting in to troubleshoot will get you nowhere.
-
This is a strange problem that I've been experiencing randomly for the past few weeks. Looking at the Dashboard I will see my CPU load spiking to 100% or near that every few seconds. I've attached a gif below that shows what it looks like. The gif is not sped up at all, it is real-time. While this is happening I can tell there is sluggishness in the unraid interface. Even going to the terminal and starting to type it will pause for a second before catching up with everything I typed. I'm also unable to play 4k files over the network as it also affects my network throughput. It's odd that all cores are spiking as well because I have cores 10/22 and 11/23 isolated to a VM. The VM is also very sluggish and pretty much unusable while this is happening.
I've stared at top/htop endlessly and nothing stands out as the cause. I tried looking at various i/o wait tools and I don't see anything of note. Rebooting sometimes makes it go away, but only for a random amount of time. I've even booted with auto-start disabled and at some point it will start happening. So I think that rules out the possibility of any dockers/VM's causing it. Any help on this would be greatly appreciated...I'd really like to be able to watch my 4k content.
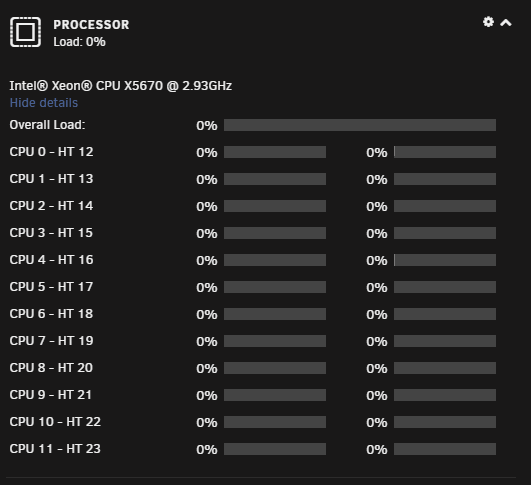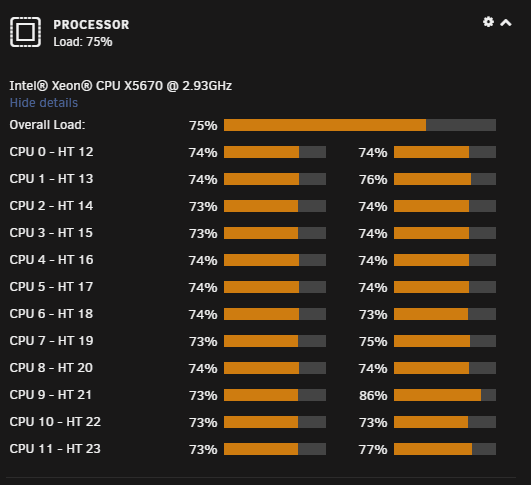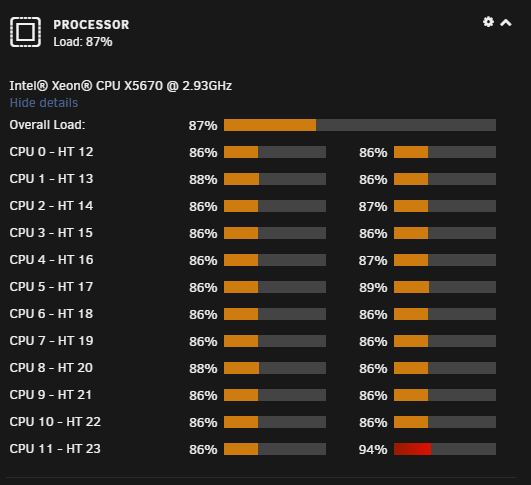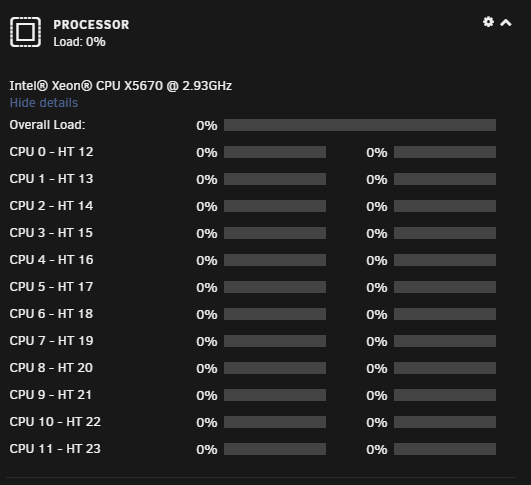
-
20 hours ago, dexxy said:
I've been having a similar problem. Have you had any luck with solutions? I'll start off at ~100MB/s download speeds on rclone (running directly on rclone) or in filezilla running on a windows 10 VM. After about sixty seconds the speeds will drop off entirely, even hitting several bytes/second.
I forgot to update this thread with what I did to resolve my particular problem. Strangely it was my qBittorrent docker itself that was incapable of downloading any faster than around 30MB/s. I switched my torrent client to Deluge, and then installed the 'ItConfig' plugin and loaded the "performance" settings. With this new setup I am easily able to hit gigabit speeds with torrents. So unfortunately I don't think I can give you any tips for how to fix your rclone speeds.
-
4 hours ago, testdasi said:
First thing first, get your unit right please.
You use "mb/s" for everything. Do you mean megabit per second? Then your "Ran a file write speed test on my cache drive and was able to hit 160mb/s write speed consistently" suggests a potential issue with your cache drive. 160 "mb/s" is 20 megabytes/s - incredibly slow.
Also Have you checked if your ISP and/or VPN is capping your torrent speed?
My apologies, all my comments are referring to megabytes per second, not megabits.
It's not my ISP or VPN causing the problem as far as I can tell. My torrent speeds are what tipped me off to this problem, but I'm using "curl" in the terminal to download an iso file to specific locations to test my speeds now. When I direct the file to be saved at /mnt/cache I'm hitting 108MB/s, but when I save it to a folder in /mnt/user I get 30MB/s max. And I've verified the file is going to my cache drive when saving to the folder in the user directory.
I know there is overhead involved by using the fuse filesystem, but a ~70% decrease in speed seems excessive. And I'm sure I was able to get at least 100MB/s on my torrents a few months ago. So something along the way has changed, and I've not really touched my unraid settings since I set it up last year.
I should mention that I was originally on v6.7.2 when I noticed this problem, and have moved to v6.8.0-rc7 to see if would make a difference. Which it didn't.

-
Tried enabling Direct I/O and saw no difference at all in the download speed to /mnt/user/*
-
Anyone have some ideas of what this could be? It's incredibly frustrating to pay for gigabit and only hit about 30% of what it can do.
-
1 hour ago, BRiT said:
Try uninstalling PreClear Plugin.
I can't say this is a cause, but it's not good to have a current version of something from 2019-08-01 replaced with something from 2017-01-22. [ https://libevent.org/ ]
Nov 24 00:07:21 Shaun-NAS root: +==============================================================================
Nov 24 00:07:21 Shaun-NAS root: | Upgrading libevent-2.1.11-x86_64-1 package using /boot/config/plugins/preclear.disk/libevent-2.1.8-x86_64-3.txz
Nov 24 00:07:21 Shaun-NAS root: +==============================================================================
Nov 24 00:07:21 Shaun-NAS root: Pre-installing package libevent-2.1.8-x86_64-3...
Nov 24 00:07:22 Shaun-NAS root: Removing package: libevent-2.1.11-x86_64-1-upgraded-2019-11-24,00:07:21
Nov 24 00:07:22 Shaun-NAS root: Verifying package libevent-2.1.8-x86_64-3.txz.
Nov 24 00:07:22 Shaun-NAS root: Installing package libevent-2.1.8-x86_64-3.txz:Unfortunately that didn't seem to help. But I have been having this issue for a couple weeks now, long before I updated Preclear.
Something interesting I just found... I changed my qBittorrent docker to use /mnt/cache/appdata instead of /mnt/user/appdata and I am now able to curl to the /config directory inside the docker at gigabit speed. So it's as if writing to /mnt/user directory, whether it's going to the cache or not, is slow? I'm not sure, sounds weird.
-
1 hour ago, BRiT said:
Very odd, since I'm easily able to hit my max wirespeed [ 330 mb/s ] using nzbget docker from usenet to its tmp download directories mapped from /mnt/cache/.
Really hard to take guesses on what's wrong with your setup without solid information to look at like at a minimum your Diagnostics from after your d/l attempts.
Attached my diag file. I really can't make sense of why the dockers are so much slower.
-
Tried some more dockers, all of them hit some sort of ~30mb/s limit, EXCEPT for the pihole docker. Not sure what that tells me. Can pihole somehow slow down network throughput?
-
18 hours ago, Squid said:
Probably dumb question, but are you sure the curl was downloading to /mnt/cache and not /mnt/user where it potentially could wind up on the array depending upon settings, etc
I made sure that the downloads were going to /mnt/cache. Here's the weird thing, I swapped my ethernet cable and now I'm able to hit gigabit speeds using curl, but my torrent downloads are still having the same behavior and only getting to 20-30mb/s.
So I tried doing curl to "/mnt/cache/appdata/qbittorrent" using the unRaid terminal and hit 108mb/s. I then opened up a console into the qbittorrent docker itself and went to /config, which is effectively the same path and tried doing curl, and was only able to hit 30mb/s. I tried this in other dockers and got the same result. Is there something that would limit the speed that dockers are able to download? And I've verified that my docker image is on the cache drive.
-
Recently I noticed that my download speeds are slower than usual on my server. I have gigabit internet and would regularly get upwards of 70-100mb/s downloads on large torrents. Now I'm barely able to hit 30mb/s.
Some tests I ran:
- Speedtest/downloaded files using my Windows system - hit gigabit speeds easily
- Ran a file write speed test on my cache drive and was able to hit 160mb/s write speed consistently
- Using a mapped folder from my cache drive, I downloaded a large file to it using Windows and was able to get ~70mb/s (probably need a better server to download from)
- In the unRaid terminal I used curl to download a file to my cache drive and was only able to get around 25mb/s. It seemed as if it would get up to 25mb/s and then suddenly drop down to around 17mb/s and then climb again.
Anyone have some ideas why this might be happening or some things I can check to figure out what's going on?
Thanks.
-
On 9/19/2019 at 2:28 AM, Djoss said:
Did you started the backup as a new device? If yes you could try the same thing on onRAID to see if this make the difference.
I did a replace and did not start a new device. This worked on my home PC's Ubuntu. I then created a VM with my unraid server using the same Ubuntu version. Got stuck in the same place as the Crashplan docker does, while trying to re-sign in after going through the replace device prompts. The logs show the same errors that I posted earlier in the thread, with connections being dropped/closed. So there is definitely something unique about how unraid is configured that is making Crashplan break.
-
On 9/5/2019 at 9:20 AM, Djoss said:
So update to the latest Docker image and run the following commands:
docker stop CrashPlanPRO mv /mnt/user/appdata/CrashPlanPRO/log /mnt/user/appdata/CrashPlanPRO/log.old docker start CrashPlanPRO
Wait a few hours and try to contact the support team again.
So what I ended up doing was creating an Ubuntu VM on my regular home PC and installed Crashplan there. At first it seemed like I was running into the same problem during the sign-in process, but I restarted the CrashplanEngine and then was able to login successfully and the backup started running.
I suppose this means there is something going on with my Unraid server's configuration that is causing this problem of being unable to connect/backup. Looking at @Spritzup's message above, I realized I have a PiHole docker running that maps port 443. Is this potentially a commonality between those of us having issues connecting to Crashplan? It just seems strange that I've had this setup for a while now without any problems until recently.
-
9 hours ago, Djoss said:
Did you tell you which version of Linux you were running?
Could you provide the output of the following command:
grep -w OS /mnt/user/appdata/CrashPlanPRO/log/app.log /mnt/user/appdata/CrashPlanPRO/log/service.log
This is what the support said:
QuoteWhen reviewing your device details it appears that you are running Linux version 4.19.56.
CrashPlan for Small Business currently supports the following distributions of Linux:
Red Hat Enterprise Linux 7.6
Red Hat Enterprise Linux 7.5
Red Hat Enterprise Linux 7.4
Ubuntu 18.04
Ubuntu 16.04
Ubuntu 14.04
Output of the command:
/mnt/user/appdata/CrashPlanPRO/log/app.log:OS = Linux (4.19.56, amd64) /mnt/user/appdata/CrashPlanPRO/log/service.log:[08.30.19 22:38:57.446 INFO main up42.common.config.ServiceConfig] ServiceConfig:: OS = Linux /mnt/user/appdata/CrashPlanPRO/log/service.log:[08.30.19 22:38:57.831 INFO main om.code42.utils.SystemProperties] OS=Linux (4.19.56, amd64)
-
6 hours ago, Djoss said:
I would try to contact CrashPlan support. I think they can assign you to a different server.
Just don't tell them your are running CP in a container
")
Too late
I contacted them last week and he said without any prompting from me that he could see I'm running the app in an unsupported version of Linux and that I would need to run it from a supported OS before he could provide any support.
-
23 hours ago, Djoss said:
Try to look at /mnt/user/appdata/CrashPlanPRO/log/service.log. You may have more details about the issue.
So I'm seeing lots of stuff like this:
[08.30.19 23:09:58.735 INFO erTimeoutWrk e42.messaging.peer.PeerConnector] PC:: Cancelling connection attempt due to timeout - pending connection=PendingConnection[timeout(ms) = 30000, startTime = Fri Aug 30 23:09:23 MST 2019, remotePeer = RemotePeer-[guid=4200, state=CONNECTING]; Session-null, pendingChannel = com.code42.messaging.network.nio.NioNetworkLayer$1@57340d4d][08.30.19 23:09:58.737 INFO erTimeoutWrk 42.messaging.network.nio.Context] Channel became inactive. closedBy=THIS_SIDE, reason='Connect cancelled', channel=Context@1942087335[channelState=0], remote=[[[email protected]:443(server)], transportPbK=X509.checksum(be4b2a71961d23dabb77ea3851a2fc8d)]
[08.30.19 23:10:23.738 INFO re-event-2-4 abre.SabrePendingChannelListener] SABRE::Channel connect failed for guid 42, cause=io.netty.channel.ConnectTimeoutException: connection timed out: /162.222.41.12:443
[08.30.19 23:10:23.739 INFO re-event-2-4 .handler.ChannelLifecycleHandler] SABRE:: Channel became inactive. closedBy=THIS_SIDE, channel=[id: 0xe810da0f], sessionState=RemotePeer-[guid=42, state=CONNECTING]; Session-[localID=916848385999105934, remoteID=0, closed=false, remoteIdentity=ENDPOINT, local=null, remote=null]
[08.30.19 23:11:13.740 INFO erTimeoutWrk e42.messaging.peer.PeerConnector] PC:: Cancelling connection attempt due to timeout - pending connection=PendingConnection[timeout(ms) = 30000, startTime = Fri Aug 30 23:10:38 MST 2019, remotePeer = RemotePeer-[guid=4200, state=CONNECTING]; Session-null, pendingChannel = com.code42.messaging.network.nio.NioNetworkLayer$1@2259404e][08.30.19 23:11:13.740 INFO erTimeoutWrk 42.messaging.network.nio.Context] Channel became inactive. closedBy=THIS_SIDE, reason='Connect cancelled', channel=Context@1972117142[channelState=0], remote=[[[email protected]:4282]]
[08.30.19 23:12:13.743 INFO erTimeoutWrk e42.messaging.peer.PeerConnector] PC:: Cancelling connection attempt due to timeout - pending connection=PendingConnection[timeout(ms) = 30000, startTime = Fri Aug 30 23:11:43 MST 2019, remotePeer = RemotePeer-[guid=4200, state=CONNECTING]; Session-null, pendingChannel = com.code42.messaging.network.nio.NioNetworkLayer$1@2a52b0f]
[08.30.19 23:12:13.743 INFO erTimeoutWrk 42.messaging.network.nio.Context] Channel became inactive. closedBy=THIS_SIDE, reason='Connect cancelled', channel=Context@2116878626[channelState=0], remote=[[[email protected]:4282]]Here's the odd thing. I wiped out my install and even recreated docker.img. When I did all that I was able to login and say I wanted to replace an existing backup. It said it would pull my settings and have me login again, and THAT is when things go to shit. It sits on "Connecting..." indefinitely and those messages above are what I see in the logs. If I kill the docker and restart it I am unable to login and get "Unable to sign in cannot connect to server" messages. The only time I can login is if I wipe out my container config and start fresh.
I've gone into the container console and tried pinging the IPs it's unable to connect to and it seems to work fine. I'm very confused why this is suddenly broken.
-
My crashplan has been saying "unable to connect to destination" for weeks, and I have no clue what changed. It's been fine for months without any interaction. Any ideas what I could check? I've tried restarting my whole server, restarting the docker itself, doing "rz, restart" in the internal crashplan console window. Nothing has made a difference.

[Support] SpaceinvaderOne - Macinabox
in Docker Containers
Posted
Sorry but this isn't accurate. Like the other person mentioned, I would login to iMessage and get kicked out after a few seconds, no popup would ever happen. But if you run iMessage through the terminal you WILL get a customer code in the log. I called, gave them the info, and on the 2nd call the lady said, "Oh I see where I need to put that code. Try logging in now." And it suddenly worked. So a popup may or may not happen to indicate your account needs to be authorized.