

Marc_G2
-
Posts
100 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Marc_G2
-
-
I double checked the firmware on the LSI card and it's 20.00.07.00. Which is the newest as far as I know. (see image of boot screen below). So who knows. Maybe it's a motherboard issue.
The one other thing I should've tried is checking the unRAID error log to see if gave any hints. I've crammed the drive into a shucked WD enclosure. And it's not worth the hassle the remove and check it at this point.
.thumb.png.35f80ed28c3b8a33acd4da6073462a44.png)
-
I'm having trouble excluding directories from an unassigned device share.
Is this the correct input field format for excluding two folders?
'Aux SSD/Priority Share/Folder1', 'Aux SSD/Priority Share/Folder2' -
The drive is HUH728080ALE604. The HBA card is SAS 9211-8i.
-
13 minutes ago, ConnerVT said:
4Kn and 512e format? I'll let the LSI HBA experts comment.
Before connecting it to the system, I tested the drive over usb and formatted it to NTFS with default parameters.
I've put data on it now. So I can't try it unformatted.
-
Yes I was using the same power connection each time. I also tried a different connector which provides the 3.3V. That didn't help.
Also all the disks are sata. I'm using mini sas to sata breakout cables.
-
15 hours ago, JorgeB said:
Is the power cable you are using the same with the LSI and onboard? Also make sure the LSI is using the latest firmware.
The LSI card is powered by the PCIe slot. It's one ATX power supply powering everything. If the firmware version from 2016 is the newest, then I'm on the latest. I couldn't locate anything newer.
I decided to use the hard drive as USB backup drive instead of putting in the array. So the issue is largely moot now. I guess I'll avoid enterprise drives for now.
-
I picked up a used HGST Ultrastar HE8. unRAID doesn't detect it when it's connected via the LSI HBA card. It is detected when it's connected directly via motherboard SATA. Does anyone have an idea why?
I tried two different sata connectors coming off the LSI card. One of the 4 connectors was already in use. So I doubt it's the cable.
Side note: This drive has a very slow spin-up time. So I don't recommend it for anyone who's set their drives to spin down frequently.
-
18 minutes ago, Bob@unraid said:
so the only way is got to the recent unraid version before the update to the current version?
Thanks
I think you'd need to go back to 6.11.X. But that's not recommended. I would try to make use of the network activity monitor or time of day exclusions.
-
32 minutes ago, rbojanssen said:
I have some problems with the S3 Sleep plugin. It's a bit too eager to put the system into sleep....
")
I have execute function on Sleep but no matter what options (Wait for array or Monitor Disks outside) I select it wil ALWAYS put computer to sleep after the Extra Delay after array inactivity.
My disks spin down after 30 mins. Extra delay is set to 5 mins. No matter if the array is active or not it puts my server to sleep after 5 mins. I tried enabling and disabling the "Wait for array inactivity" and select all of the array disks in "Monitor disks outside the array" but after 5 mins, computer goes to sleep.
Tried re-install but results are the same.
The disk activity checker function is broken in the current unRAID version. No one knows when or if it will get fixed.
-
In case anyone's interested, SpaceInvader One did a new video on the topic of sleep/wake with the S3 sleep plugin. Sadly, he did not have any suggestions regarding the disk activity function not working. I'm not sure if he's wasn't affected or he didn't test it thoroughly enough to notice.
https://www.youtube.com/watch?v=lBxQcU1MPY0
-
I plan to upgrade most of my stuff to 2.5 gigabit in the next few months. My server cpu is currently a dual-core i3-6100. That's so low spec, I'm wondering if it will (or currently is) slowing down any kind user or backend NAS functions like parity calculations. Or that it might slow down my network transfer speeds on certain kinds of SSD storage pools.
Thoughts on this?
I'm currently upgrading another gaming desktop. So I have to choose between selling the old hardware or using it to upgrade my server.
-
Any Linux experts here? I suspect the problem with the Sleep plugin's disk activity checker is with this function. If so, it may be an easy fix to just modify the plugin file and then repackage it as a txz.
HDD_activity() { result= if [[ $checkHDD == yes ]]; then [[ -f /dev/shm/2 ]] && cp -f /dev/shm/2 /dev/shm/1 || touch /dev/shm/1 awk '/(sd[a-z]*|nvme[0-9]n1) /{print $3,$6+$10}' /proc/diskstats >/dev/shm/2 for dev in ${array[@]}; do [[ $monitor -ne 2 ]] && active=$(sdspin /dev/$dev) || active= [[ $monitor -ne 1 ]] && diskio=($(grep -Pho "^$dev \K\d+" /dev/shm/1 /dev/shm/2)) || diskio= if [[ -n $active || ${diskio[0]} != ${diskio[1]} ]]; then result=1 break; fi done fi if [[ -n $result ]]; then log "Disk activity on going: $dev" echo $result fi } -
5 minutes ago, dopeytree said:
Sleep plugin works... My personal set up is:
- Set to shutdown (to avoid the cpu bug)
- Set excluded hours (6am - 11pm)
- Array activity = yes
- Status & counters
- Monitor all array disks & other caches like 4 disk ZFS pools (I choose to ignore the main nvme cache as this is ALWAYS active)
- Network activity = high (to avoid shutdown during plex or other network transfer)
- User inactive = yes (to avoid shutdown when I am fiddling)
You've confirmed disk activity detection specifically still works? Then I guess it still works some folks on version 6.12.X.
So far there's about 5 people in this thread who's found it to be broken.
-
 1
1
-
9 hours ago, vw-kombi said:
Its like it is ignoring the active disk ? This is with 6.12.4 os also.
Disk activity detection is broken on 6.12 for everyone as far as I can tell. The dev has made no comment about when or if it will get fixed.
-
I changed the file system of my BX500 SSD to btrfs instead of ZFS. I then tested the performance by transferring a 50GB file. There were fluctuations in the transfer speed but it never completely halted like it did when was formatted as ZFS. The total transfer time was probably about cut in half. So I'm going to assume the issue has been mitigated.
My advice to anyone else to only use drives with good sustained write performance if using ZFS. Though I haven't confirmed yet whether that would also fix the issue on my system.
-
52 minutes ago, TCMapes said:
Is there something I should do? I feel like my system is rebooting to protect itself just don't know why.
Yeah reboots like that are usually either due to either power or overheating issues. If your psu is spec'd plenty high, then I would double check all your connections.
-
I'm writing to the SSD at only 100 MB/s. Under normal desktop usage, the BX500 write speed will drop to 40 MB/s when it runs out of cache (which is 48GB). It's not normal for it to completely halt.
I have other SSDs so I'll try a different one. I'll also see if there's any difference between btrfs and zfs.
-
That doesn't explain why there's frequent pauses during large sequential writes. This write performance isn't normal for any SSD. Is it due to ZFS overhead?
-
Is this what you're looking for? Interestingly when the system pauses, this graphs shows no cpu activity unlike the one on the dash
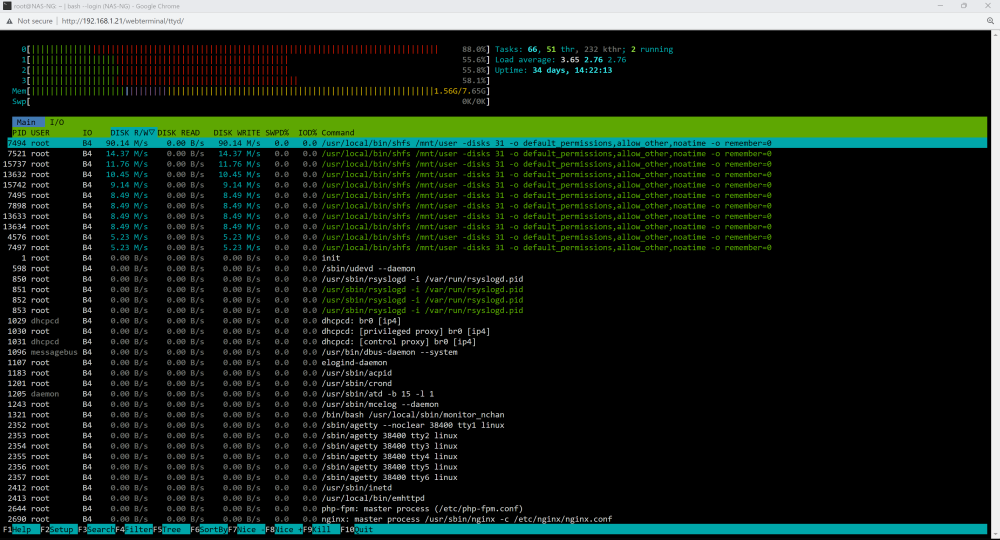
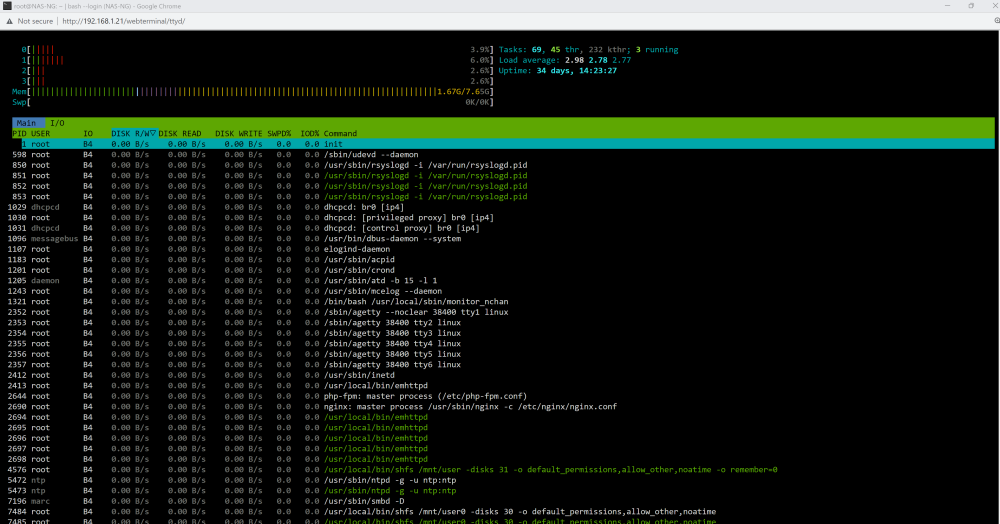
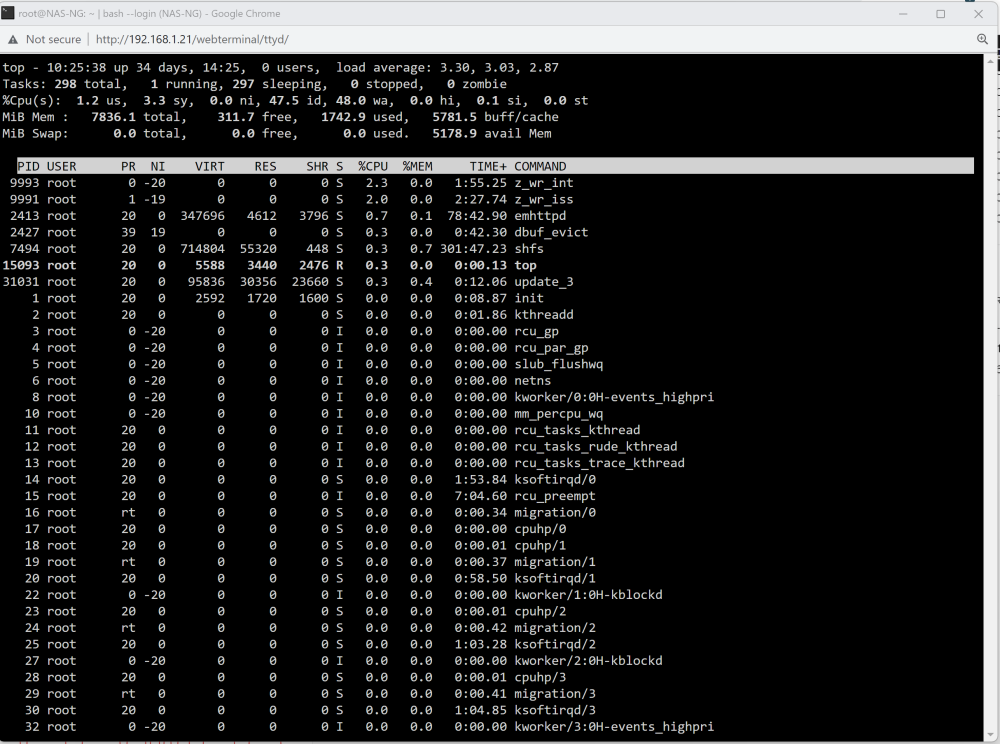
-
5 hours ago, JorgeB said:
Check top during a write, dash graph includes i/o wait.
I'm not sure graph you're referring to.
I did some more tests and found the issue only happens after around 25GB of continuous transfer. Here's a graph of the network activity (1 large file transfer).
During those periods of zero activity, there's 100% cpu usage. So there appears to be some computations happening that's causing the delays

-
On 8/6/2023 at 7:14 AM, Manni01 said:
Just to report an issue with the S3 sleep plugin
I've had same problem with it going to sleep as well. Did you confirm it to only be a problem when the parity check is running?
-
Dynamix Sleep's Array activity detection is completely broken for me right now. I set to monitor activity and counters. But my system keeps going to sleep during a parity scan. I'm not sure, but I think it may have started after updating to 16.12.2.
Does anyone have any ideas???
Edit: just noticed the same issue being reported above.
-
1
-
-
Diagnostics attached in case that helps any
-
I set up a new separate cache for one of my shares and went with ZFS. It's a single drive cache. Is relatively high CPU usage normal when writing to a ZFS cache? Apparently, my CPU can't keep up to the point where my large file transfers regularly halt for 5-10 seconds every 30 seconds or so.
My other cache is setup as 2 drive BTRFS. I haven't had this issue with it.
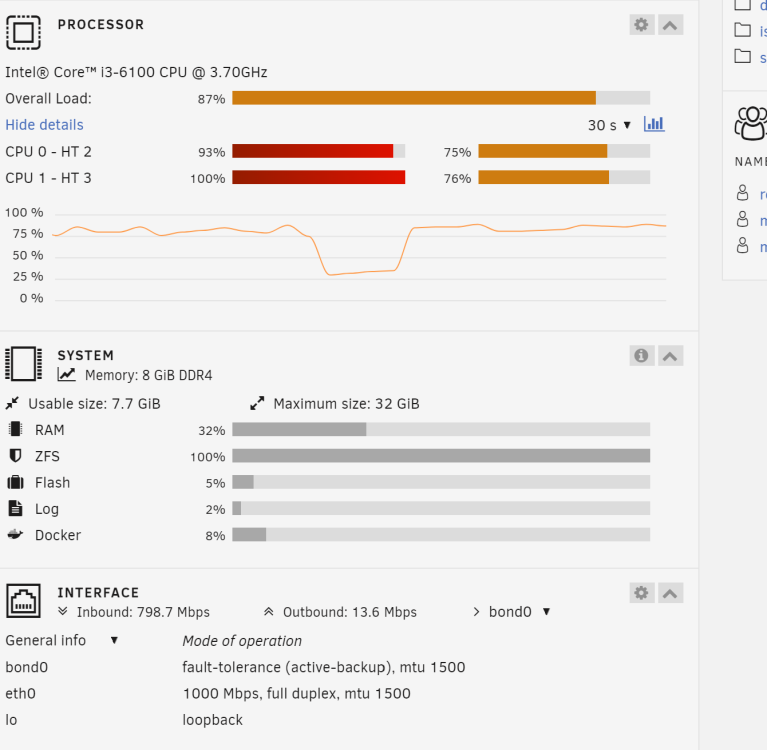
.png.72a2ee704fa70b7c2b543180cb841499.png)






Dynamix - V6 Plugins
in Plugin Support
Posted
Keep in mind, the plug-in is just a front end for executing sleep commands on a schedule. If you initiate sleep via the terminal, I strongly suspect you'll have the same issues waking up.
My old system had major problems with its HBA card after waking from S3 sleep. The issue was fixed after updating my motherboard to the newest BIOS. So I suggest seeing if updating all your firmware fixes the issue.