

Julius
-
Posts
38 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Julius
-
-
I'd like access to a USB device from within a VM. Problem however is that it uses the same Group as the UnRaid USB stick;
Group 4 00:14.08086:a36dUSB controller: Intel Corporation Cannon Lake PCH USB 3.1 xHCI Host Controller (rev 10)
USB devices attached to this controller:
Bus 001 Device 004: ID 051d:0002 American Power Conversion Uninterruptible Power Supply
Bus 001 Device 003: ID 0781:5567 SanDisk Corp. Cruzer Blade
Bus 001 Device 002: ID 289b:0505 Dracal/Raphnet technologies
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
USB Device 002 needs to be passed through. Why is this so hard to share with a VM in 2020 ?
-
The Fix Common Problems script is telling me my ca mover tuning plugin is deprecated, then links to an update fork for me, but there's no url or anything to install it there.
Oh, apparently 'Apps' are now the same as 'Plugins' ? Why the different tabs in the menu then?
-
2 hours ago, plantsandbinary said:
So setting it to "Custom: br0" and giving it its own I.P. address solved the problem completely using default settings.
There is no "Custom: br0" under my docker Network type options. Already gave it its own IP (as I clearly wrote), still it fails saying its IP is 0.0.0.0, which it is not.
I switched off docker support for my unraid entirely. Back to using VMs for all, much easier to maintain, to secure (csf/lfd firewall), no strange translations, soft-linking or proxying, and I found a very good config for pihole using a nginx server.conf with php-fpm here.
-
12 hours ago, testdasi said:
You need to give the docker its own IP. There's something using port 443 according to the error.
Alternatively map port 443 to a different port.
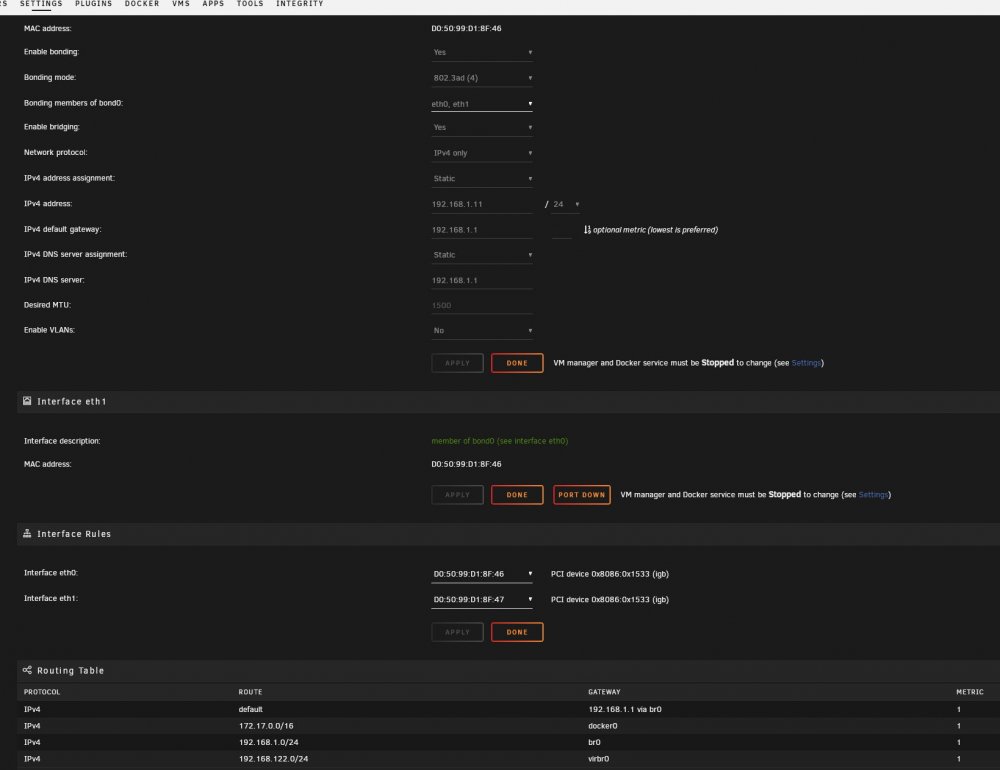
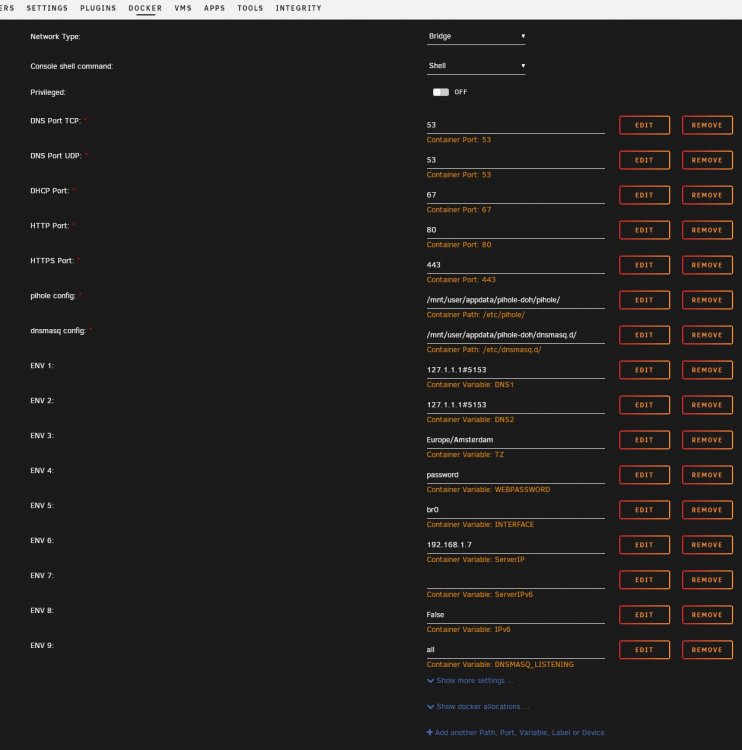
Already tried both options, and more. It doesn't work. Unraid runs on 2 interfaces (eth0 and eth1, as bond0) with 192.168.1.11, I've set the docker to use a free IP 192.168.1.7, but even when I set it to use the same IP and different ports (81 and 445 for example), there's no pihole web-ui running. The docker keeps failing to start, and when it does start it says it's using 192.168.1.11, which I did not set. Attached are the network config and docker config. (Good grief, what do people see in those docker containers? It's a complete flaky network-mess, full of translations, redirections and proxies, adding latency and complexity. And extra webservers running just for one app. I keep saying it; VM's are more efficient, easier to maintain and easier to make accessible. But much to my surprise, pi-hole doesn't even properly support being installed on Debian 10, with the shipped php-fpm and nginx, otherwise I already would have done that in the VM's I run on this unraid server.
-
For me there's never a br0, and I have not set anything aside from defaults. Also, /var/lib/docker/network/files/local-kv.db does not exist on an up to date unraid server.
The networking stack is still very flaky in unraid. If I change the docker settings for networking, it can entirely hang the server and make it inaccessible.
While all I have here are 2 NICs connected with a bond, so that speed is faster to/from the server. Other than that nothing deviates from the default.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='pihole-with-doh' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e 'DNS1'='127.1.1.1#5153' -e 'DNS2'='127.1.1.1#5153' -e 'TZ'='Europe/Amsterdam' -e 'WEBPASSWORD'='password' -e 'INTERFACE'='br0' -e 'ServerIP'='192.168.1.7' -e 'ServerIPv6'='' -e 'IPv6'='False' -e 'DNSMASQ_LISTENING'='all' -p '53:53/tcp' -p '53:53/udp' -p '67:67/udp' -p '80:80/tcp' -p '443:443/tcp' -v '/mnt/user/appdata/pihole-doh/pihole/':'/etc/pihole/':'rw' -v '/mnt/user/appdata/pihole-doh/dnsmasq.d/':'/etc/dnsmasq.d/':'rw' --cap-add=NET_ADMIN --restart=unless-stopped 'testdasi/pihole-with-doh' 39f5fd7455f1fa5dfed989b1cefa10fdebea845722d37b2dc8861afc9b8c0203 /usr/bin/docker: Error response from daemon: driver failed programming external connectivity on endpoint pihole-with-doh (ec98edf36e66ae40c9ead8078e625cbcc65563379fd10c2073956e49ac008095): Error starting userland proxy: listen tcp 0.0.0.0:443: bind: address already in use. The command failed.
Whatever I do, I can't seem to get it running.
-
My personal idea on this has always been in favor of spinning them down depending on the duration they are generally not spun up again. Basically what jonathan is saying as well, if they're offline for more than, say, 12 hours, I'd say that's a win for disk longevity. I think I also read that in a google datacenter document as well. I now have unraid set to a Spin-down delay of 45 minutes, after having started with 15 minutes I noticed that was moot, since some disks would be doing stuff intermittently right after they were then spun down, like receiving a finishing bit from a backup from a remote server, or loading or unloading files from a device on the LAN. None of the tasks last longer than 45 minutes each, so if a disk is doing nothing for that time, it can be spun down and would not be accessed soon after. We don't stream stuff from the unraid server, so you may want to consider setting it to the max duration of any video you access from it, that does make sense I guess. Depending on how many disks, how you have divided the use of them under Shares (I have some of the 10 disks in the array excluded for parts, so they can remain spun down longer), and how many people are accessing your server. I have a really large cache (1TB) so that helps as well for the reads and re-reads from SSD that don't require new access from the array.
-
3 minutes ago, saarg said:
This container doesn't use Apache, but nginx. So if you didn't use this container I find it strange you are posting this here.
What might seem easy to you might not be as easy for others. For people not used to setting up a VM with all the requirements, this docker is easier.
Oh I wasn't even checking. I thought it did use apache, since I saw that being mentioned somewhere. I'll edit my post, because that part was irrelevant anyway. It's not the apache vs nginx that makes the VM better (for me).
-
I've tested these two options;
1) this Piwigo docker, accessing a separated mariadb instance. Rather complex and slow loading large amounts of images.
2) Piwigo, mariadb, nginx, php-fpm and CSF, all on 1 debian minimal VM.
Both instances of piwigo access the exact same folders from an unraid share with terabytes of imagefiles.
The second option performs noticeably faster, even without doing proper IO tests etc. The difference is so obvious, that I'm not even going to bother testing it with tools. Could be because I run unraid with a decent Xeon and 32GB RAM, but still; I don't see any advantage over docker instances for piwigo, and I just wanted to share that, because frankly, setting up piwigo in that VM was so much easier, other than maybe using a little fewer resources I don't understand what all the fuss on having it as a docker instance is about.
The SSL/TLS cert for NGINX is located in an Unraid Share with Unraid Mount tag in the VM. Same LetsEncrypt wildcard cert I use for the unraid UI. So no weird proxying or network complexities. Plus, a csf/lfd firewall in front of the piwigo server VM, allowing me to serve the stuff through my internet-router to the world.
-
 1
1
-
-
No end in sight. I have no idea why.
In the bottom left corner it says;
"Array Stopping•Retry unmounting user share(s)..."
Nothing is connected to it, except that one browser tab.
This is super time-wasting. I try to change config, adding a disk etc. Only way to get there is by powering down and immediately pressing to stop the array when it starts.
-
5 hours ago, trott said:
turn off the AER did actully not fix the issue, if I were you, I will change the HBA card, once the error cannot be automatically corrected, you might lose your data
I don't think you've read correctly, the AER is doing the reporting of the corrected errors, not the correcting itself. The AER driver receives the corrected error notification but fails to clear it. Besides, the error is not coming from the card, but from the pcie hardware on the mainboard. Of course I can try a different card, but I doubt it will make a difference, the source is in unRAID's linux kernel, not the card's hardware. (Already one of the best ones with vast config options and up to date firmware.)
-
Found out it is a known kernel error for many linux distros relating to Advanced Error Reporting; http://billauer.co.il/blog/2015/10/linux-pcie-aer/
and apparently can be switched off per device. See also https://gist.github.com/Brainiarc7/3179144393747f35e5155fdbfd675554
Problem is, I can't test for days yet, because parity is being recreated here.
")
-
OK, that's reassuring, thanks. I asked because I noticed /etc/ssh got new updated ssh_host* keys while I had not rebooted the server. Perhaps stopping and starting the array re-generates keys if some do not exist there?
-
Hmmm.. apparently doesn't make one bit of difference either how I set boot options for the card, or if the boot-flash is even there or not.
As soon as I use this LSI 9207-8i card in this PCI-e slot, I get this;
Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 134131744 bytes) in /usr/local/emhttp/plugins/dynamix/include/Syslog.php on line 20Note that *everything* else is error-free on this unRAID server and its hardware.
Attached is the latest run that filled up syslog..
-
2 minutes ago, trott said:
I also have HBA card with only 4 SATA connected, no such issue. what's firmware version
Latest version from the broadcom site, think it's called Avago in bios now. Going to try and erase BIOS entirely from the card, following this and check if that solves it..
-
OK, for now I 'fixed' this by destroying syslog every few hours via the user scripts plugin;
#!/bin/bash rm -f /var/log/syslog touch /var/log/syslog chmod 0644 /var/log/syslog exit 0
-
Same here, all is functioning fine, but syslog is filling up in minutes everytime after I clear the log. And I have no PCI-e slots available to switch to/from.
Can someone at unRAID dev tell me how to disable logging for this?
Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Multiple Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: can't find device of ID00dc Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Multiple Corrected error received: 0000:00:1b.4 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: PCIe Bus Error: severity=Corrected, type=Physical Layer, (Receiver ID) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: device [8086:a32c] error status/mask=00000001/00002000 Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: [ 0] RxErr (First) Sep 23 11:09:05 silent kernel: pcieport 0000:00:1b.4: AER: Corrected error received: 0000:00:1b.4This is coming from the PCI slot where a LSI HBA card is. I only use 4 SATA connections of the 8 available, perhaps that causes this, but still, it's pretty ridiculous.
-
On 10/14/2018 at 12:03 PM, ken-ji said:
So this is what needs to happen for SSH to work without prompts, or errors after a reboot.
Unraid server:
- /root/.ssh directory with permissions (700)
- /root/.ssh/id_rsa file needs to exists with the permissions (600); this is your private key
- /root/.ssh/known_hosts with permissions (600); this file contains the public key of the servers you've connected to and stops the prompting of the untrusted host/ unknown keys; if the server changes (or a MITM attack occurs) this will prevent SSH from connecting until the server public keys match or is scrubbed from the file
- /root/.ssh/config with permissions (600); this specifies some config options, like the server aliases, keyfiles, etc - this is not necessary if you are connecting to the other server as root, using the server IP address (or a name that your Unraid server can resolve into its IP adrress)
- (optional) /root/.ssh/id_rsa.pub file; this is the public key pair to your private key
I noticed unRAID alters /etc/ssh content at random times, not sure why or when, but it's not just at boot time.
Do you know if unRAID also alters the /root/.ssh folder at any time, or is that left alone (except at RAMdisk creation of course) ?
Either way, I could run a cron overwriting them every few hours or so, preceded by updating the (custom ssh) source's known hosts and authorized keys files.
-
Does the 'At startup of Array' run before or after the go script?
Does the 'At startup of Array' execute before or after ssh service daemon starts?
Is there a chart somewhere showing the runtime levels (or order) per plugin or service?
-
12 hours ago, Squid said:
User scripts plugin. Schedule run at array stopping or array starting
Sent from my NSA monitored device
Yes, that will do, thanks!
Regarding ssh, do you know if it's easy to change the code that keeps updating the /etc/ssh content after each restart of sshd? I mean, even that last bit of my previous post (updating the source that I use to overwrite the ssh) isn't fail-safe, because I found out the hard way that unRAID updated the keys without me knowing. If someone at unRAID core is reading; could you please make that an Advanced option? Something like
"Leave /etc/ssh alone after initial ramdisk creation and sshd restarts [x]"
would help us a lot.
-
So far I've used the go script to overwrite /etc/ssh and /root dirs with my own keys and config for shell, and persistent .bash_history file and such, like so;
# force overwrite root config to /root/ and etc/ssh and set permissions cp -af /boot/config/xroot/. /root/ cp -af /boot/config/xssh/. /etc/ssh/ chmod -R 0700 /root chmod 0600 /root/.ssh/* chmod 0644 /etc/ssh/*
and then I manually rsync to update them from time to time, like so;
rsync -qua --min-size=1 --no-specials --no-devices --no-links /root/* /boot/config/xroot rsync -qua --min-size=1 --no-specials --no-devices --no-links /etc/ssh/* /boot/config/xssh
but that last bit I would like to be able to perform automagically at shutdown or reboot. Any good spot for this?
-
On 9/13/2019 at 7:22 PM, fluisterben said:
Just wanted to add how I expanded on this a little;
Here's my /boot/syslinux/syslinux.cfg
default menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 30 label Unraid OS menu default kernel /bzimage append tpcie_acs_override=downstream,multifunction isolcpus=2,8,4,10 nohz_full=2,8,4,10 rcu_nocbs=2,8,4,10 initrd=/bzroot label Unraid OS GUI Mode kernel /bzimage append pcie_acs_override=downstream,multifunction initrd=/bzroot,/bzroot-gui label Unraid OS Safe Mode (no plugins, no GUI) kernel /bzimage append initrd=/bzroot unraidsafemode label Unraid OS GUI Safe Mode (no plugins) kernel /bzimage append initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest
so, as you can see, I added;
isolcpus=2,8,4,10 nohz_full=2,8,4,10 rcu_nocbs=2,8,4,10
in order to have VMs use two hyperthreaded pairs, 2,8 and 4,10 (of the 11 cores total in the Xeon used by me)
Assuming you use that Xeon from your signature (which is the exact same one I have in my unraid server, E2136), did you measure a change in some way, and if so, which/what/how? I copied these settings for my syslinux as well, and at least the VM performance seems snappier but that could be placebo..
-
7 hours ago, itimpi said:
There is something wrong with your description
 It is not technically possible to have a 10TB drive in the array if one of your parity drives is only 6TB. It is a requirement that ALL parity drives must be at least as large as the largest data drive.
It is not technically possible to have a 10TB drive in the array if one of your parity drives is only 6TB. It is a requirement that ALL parity drives must be at least as large as the largest data drive.
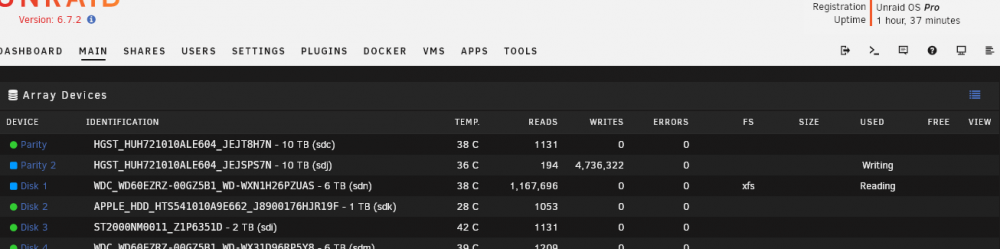
I had just added that 10TB to unraid, it wasn't used by the array yet (although it was in the dropdown to select with a stopped array), so yes, my description was incorrect if that's what it said.
Either way, 'swapping' disks in one go works, it is now copying the parity from old parity 2 to new parity 10TB, and said it will then recreate the ex-parity disk as the (new) disk1 for the array (FYI, disk 1 wasn't the 10TB before, it was another disk that needed to be replaced);
-
8 hours ago, Squid said:
Over the network. Global Share Settings, Enable Disk Shares
You probably wanted to ask how many disks can fail without losing any data. That answer is equal to the number of parity drives. In your case 2 data disks can fail simultaneously without loss of data.
That disk share over the network option is one I had not encountered in config yet, very handy! Thanks.




[Plugin] VFIO-PCI Config
in Plugin Support
Posted
Thanks, the Libvrt Hotplug USB App worked for me.