

timethrow
-
Posts
35 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by timethrow
-
-
Details about the Vulnerability here;
https://www.samba.org/samba/security/CVE-2021-44142.html
As this gets a score of 9.9, Can we expect an update to unRAID v6.9 to fix this (prior to v6.10's release)?
Additionally, is there a way to bind Samba within unRAID to only 1 IP Address? I have 3 networks defined, the main (eth0) is LAN, and have 2 VLANs attached, and unRAID listens for Samba (and other services) on each of those networks, even though the 2 VLANs don't have an IP Assigned (it seems to allocate istelf an IP ending in .128 e.g. 19.168.10.128)? From a security perspective, it would be good to be able to restrict what IPs/Networks it listens on.
Naturally for anyone who has Samba exposed to the Internet (why?!?), I would seriously consider firewalling it to a trusted network or range of IPs only, or better yet put it behind a VPN to minimise the potential attack surface.
-
 2
2
-
-
Hi,
I have 2 Disks showing as Disabled and having Read Errors, this originally started part way through my scheduled monthly parity check.
The disks don't show any smart issues that I can see, and when I try and run a Self Test (Short or Extended they keep disappearing) and after a few seconds (~30) they come back again. Its for Disks 10 (sdz) and 15 (sdx). I have a few times managed to get the Short Self Test to complete, but its rather intermittent, when it does complete, it does not report any errors.
These 2 disks are both connected to a SAS expander, but there are 13 other drives also connected to this expander and these all seem to work ok at the moment.
I have tried rebooting etc, and I also tried disabling the VM PCIe ACS override but no luck with that. No Hardware changes made for a few months and no major software changes either (including no BIOS or Firmware updates).
Diagnostics attached, does anyone have any suggestions please?
Thanks
")
-
+1 from me as well.
-
I always seem to have problems with the "Apply Fix" option for when a Template URL differs, its says the fix is applied and looking at the file it mentions, I can see its not using the new URL, and so FCP still says its an issue.
For example, at the moment, I get this in FCP;
Template URL for docker application pihole-template is not the as what the template author specified. The template URL the author specified is https://raw.githubusercontent.com/spants/unraidtemplates/master/Spants/pihole.xml. The template can be updated automatically with the correct URL.Running the "Apply Fix" option, this is the output.
Template to fix: /boot/config/plugins/dockerMan/templates-user/my-pihole-template.xml New template URL: https://raw.githubusercontent.com/spants/unraidtemplates/master/Spants/pihole.xml Loading template... Replacing template URL... Saving template... Fix applied successfully!
Running a Rescan in FCP, it shows the same issue, but a slightly different template now (its has v2 in the URL);
Template URL for docker application pihole-template is not the as what the template author specified. The template URL the author specified is https://raw.githubusercontent.com/spants/unraidtemplates/master/Spants/pihole-v2.xml. The template can be updated automatically with the correct URL.
Again, Running the "Apply Fix" option, shows;
Template to fix: /boot/config/plugins/dockerMan/templates-user/my-pihole-template.xml New template URL: https://raw.githubusercontent.com/spants/unraidtemplates/master/Spants/pihole-v2.xml Loading template... Replacing template URL... Saving template... Fix applied successfully!Looking at the file the "Apply Fix" mentions, its shows the correct URL for this second message;
root@Tower [Fri Dec 24 09:32]: ~# grep TemplateURL /boot/config/plugins/dockerMan/templates-user/my-pihole-template.xml <TemplateURL>https://raw.githubusercontent.com/spants/unraidtemplates/master/Spants/pihole-v2.xml</TemplateURL>
I feel like its stuck in a bit of a loop, not sure if its FCP or the CA App/Template, but have had this issue a few times in the past and end up having to ignore it.
-
15 hours ago, Taddeusz said:
I'll work on installing Tomcat separate from the Debian package manager.
Heya, Thank you for looking at it and the update. Most appreciated
-
 1
1
-
-
Heya, Thanks for providing this container.
Are there any plans to update the Tomcat Version, as Nessus is reporting that the version Installed has a few Vulnerabilities (CVE-2021-25122, CVE-2021-25329).
Thanks
-
1
-
-
+1 for this.
-
Hi,
As part of the ongoing efforts to improve the security of the appliance and secure by default stance, could we please include a firewall such as UFW by default in the image.
While unRAID comes with IPTables, ufw is (imo) much more user friendly, and can allow users to easily firewall off ports they dont need or restrict access.
If ufw came with unRAID out of the box (currently it requires manual install, until/if its added to NerdPack), it would allow you to apply rules on first boot as required, minimizing the time period where your host could potentially be exposed.
Thanks.
-
Could we please add UFW to this. Tested on v8.9.2 and works as expected.
https://slackware.pkgs.org/current/slackers/ufw-0.36.1-x86_64-3cf.txz.html
Thanks
-
Heya,
I think there are still some issues with this container, I rebooted by unRAID Server (Cleanly, Part of Maintenance) and when starting the container, its given me a fresh install again.
The first time the docker container did not start properly, the service started then stopped;
Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Adding nameservers to /etc/resolv.conf... Changing owner and group of configuration files... Starting the nessusd service... nessusd (Nessus) 8.15.1 [build 20272] for Linux Copyright (C) 1998 - 2021 Tenable, Inc. Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Adding nameservers to /etc/resolv.conf... Changing owner and group of configuration files... Starting the nessusd service... nessusd (Nessus) 8.15.1 [build 20272] for Linux Copyright (C) 1998 - 2021 Tenable, Inc. Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Adding nameservers to /etc/resolv.conf... Changing owner and group of configuration files... Starting the nessusd service... nessusd (Nessus) 8.15.1 [build 20272] for Linux Copyright (C) 1998 - 2021 Tenable, Inc.When manually restarting it a few times, eventually it did a backup and then started a fresh;
.... nessus/plugins-code.db.16321190631015150102 nessus/plugins-desc.db.1632119107882788674 nessus/global.db-wal nessus/global.db-shm Loading backup into new Nessus version path... Changing owner and group of configuration files... Creating symbolic links... Cleaning up deb file used for install.. Cleaning up backup files extracted and no longer required.. Starting the nessusd service... nessusd (Nessus) 8.15.1 [build 20272] for Linux Copyright (C) 1998 - 2021 Tenable, Inc. Cached 0 plugin libs in 1msec Processing the Nessus plugins... All plugins loaded (0sec) All plugins loaded (0sec)As a test I stopped the Docker Service, and started it again, and it did the same thing.
I have a backup I can restore from, but something seems a miss here.
Thanks.
EDIT: Looks like I cant even restore from Backup as it gets stuck in a loop, by the container not starting (same as above logs), and then eventually when you get it started, its doing its own back up and starting again.
-
20 hours ago, KnifeFed said:
You can use '/usr/local/emhttp/webGui/scripts/notify' in your script:
notify [-e "event"] [-s "subject"] [-d "description"] [-i "normal|warning|alert"] [-m "message"] [-x] [-t] [-b] [add] create a notification use -e to specify the event use -s to specify a subject use -d to specify a short description use -i to specify the severity use -m to specify a message (long description) use -l to specify a link (clicking the notification will take you to that location) use -x to create a single notification ticket use -r to specify recipients and not use default use -t to force send email only (for testing) use -b to NOT send a browser notification all options are optional notify init Initialize the notification subsystem. notify smtp-init Initialize sendmail configuration (ssmtp in our case). notify get Output a json-encoded list of all the unread notifications. notify archive file Move file from 'unread' state to 'archive' state.
Thanks, but this only works if you put that in for every eventuality in your script, whereas having the plugin send it after a script has completed (whether successful or not) ensures its always sent.
For example, if my script encounters an error that was not captured, the notify may not be sent if included in the script manually, whereas this way, it will always be sent, so long as the underlying plugin works.
I do have the notify in some of my user scripts, and I also do redirect alot of my output to log files I store on the array (in case I need it) but this is more for being notified for when a script is run and the output, similar to the cron service on a vanilla Linux server. It allows you to check quickly/easily if a script ran and if it has the expected output or not.
-
Heya,
Thanks for the update. Since updating this, the docker image use has gone from around ~1.5GB to 9.8GB, and has maxed out my docker image, I have given it another 5GB and its still growing.
Is this expected, i.e. are there alot of changes or new files in this update, or are there any new paths we may need to map?
This is the tail end of the Docker Log;
config/opt/nessus/var/nessus/tmp/fetch_feed_file_tmp_32_2140101596_1745818318 config/opt/nessus/var/nessus/plugins-code.db.16305872481236034445 tar: config/opt/nessus/var/nessus/plugins-code.db.16305872481236034445: Cannot write: No space left on device config/opt/nessus/var/nessus/plugins-desc.db.163058740051507450 Setting user permissions... Modifying ID for nobody... Modifying ID for the users group... Adding nameservers to /etc/resolv.conf... Backing up Nessus configuration to /config/nessusbackup.tar tar: Removing leading `/' from member names /config/opt/nessus/var/nessus/ /config/opt/nessus/var/nessus/tools/ /config/opt/nessus/var/nessus/tools/bootstrap-from-media.nbin /config/opt/nessus/var/nessus/tools/nessusd_www_server6.nbin /config/opt/nessus/var/nessus/tools/tool_dispatch.ntool /config/opt/nessus/var/nessus/logs/ /config/opt/nessus/var/nessus/nessus-services /config/opt/nessus/var/nessus/plugins-core.tar.gz /config/opt/nessus/var/nessus/tenable-plugins-a-20210201.pem /config/opt/nessus/var/nessus/users/ /config/opt/nessus/var/nessus/nessus_org.pem /config/opt/nessus/var/nessus/tenable-plugins-b-20210201.pem /config/opt/nessus/var/nessus/tmp/ /config/opt/nessus/var/nessus/tmp/nessusd /config/opt/nessus/var/nessus/tmp/nessusd.service Cleaning up old Nessus installation files Extracting packaged nessus debian package: Nessus 8.15.1... mkdir: cannot create directory '/tmp/recover': File exists
Thanks
EDIT: I couldn't get to the bottom of it, and no matter how much extra space I gave the Docker Image, within a few moments it used it all. So I ended up deleting the image, and moving the old appdata and starting a fresh. This solved the disk usage issue, however, on this clean install I had a couple of issues where nessus would not start, going to the console and starting the nessusd service manually worked. Will see how it goes over the next few days. - Thanks again for updating it
-
Is it possible to add an optional feature, to send the output of the script (the same as what is shown if you Run the Task in the Web UI) as a Notification using the unRAID Notification system, so we can see when scripts have run, and if any issues etc were reported? Similar to how in Cron you can set it to email you on completion (assuming you have the right stuff setup).
-
3 minutes ago, SimonF said:
Card doesn't seem to be in lspci, which motherboard slot is it in, have you confirmed slot is avaiilable if nvme etc are conmected.
Thanks for having a look. Its currently in PCIEX1_1 and has also been tested in PCIEX1_2.
I did have a USB Expansion Card in that slot before, and any devices connected always seems to show as expected, so it should be working. -
I have purchased a Dual NIC and installed it in my unRAID device, however it does not appear to be detecting it and allowing me to use it.
I have tried reseating the NIC and moving it to another slot on the Motherboard but no luck. I did install it in another PC as a test and that uses Windows, and it detected it fine.
This is the NIC I am using;
https://www.amazon.co.uk/gp/product/B07Y1P4DGV
I can't see anything obvious in the logs, and can see my onboard NIC shows up fine, but could well be missing something.
Any help / advice is greatly appreciated.
Thanks!
-
5 hours ago, JorgeB said:
The easiest solution is to rebuild them one by one so the partition can be correctly recreated:
https://forums.unraid.net/topic/84717-moving-drives-from-non-hba-raid-card-to-hba/
If it's really a RAID controller you should avoid that, or may need to repeat the same if you change controllers again in the future.
Thanks, thats a shame, as they are quite large disks (3x 14TB & 1x 8TB) so its probably going to take quite a while to rebuild each of them individually. But will give it a go, Thanks. - I was kind of hoping there was an easy way to get unRAID to mount them (as part of the array) and continue from there (even if it meant rebuilding parity), since all of the data is there and its accessible.
Errr, thats probably me just not using the right terminology, I have an LSI Card flashed to IT mode and using a couple of spare slots on that (was using it for over a year prior to this as well, without any issue). Sorry for the confusion.
-
Hi,
I had some data disks (4 of them) connected via USB, and just shucked them and attached them directly to my RAID Controller.
All of the disks, show up and in Unassigned Devices all still have data on etc, but when adding them back to the array (as they now have different identifiers), they show as "Unmountable: Unsupported partition layout".
Is there anyway to correct the partitions, without having to format the drives and shuffle all the data around between the drives?
I dont have diagnostics right now, but will post them as soon as I can.
Thanks.
-
14 hours ago, falconexe said:
That is a new one ha ha. If the data inspector shows clean data, that is very odd. It actually looks like some of our SNs are truncated. Can you share your query? Maybe this one is worth a private virtual meeting or Discord session. I'll have to work around my busy scheduled...
@GilbN You ever see this before?
Thanks for you help, that is most appreciated.
Here are a few screenshots.
The first shows the query in use (the main part), if you need more, just let me know.
The second, shows the serial numbers in the Data View, but the preview showing the incorrect values (it looks like its trying to format it as a number?)
The final one, is something is stumbled on earlier, going on the theory it thinks the serial numbers are numbers/integers (numeric only), and formats it like that, the first drive in the list is the nvme one, which has a Serial Number with a Numeric Value only, the second one, is a regular HDD and has an alpha numeric one, so I tweaked the query (well just part A) to exclude the nvme drive, and after that, it shows the serial number correctly for all the other drives.
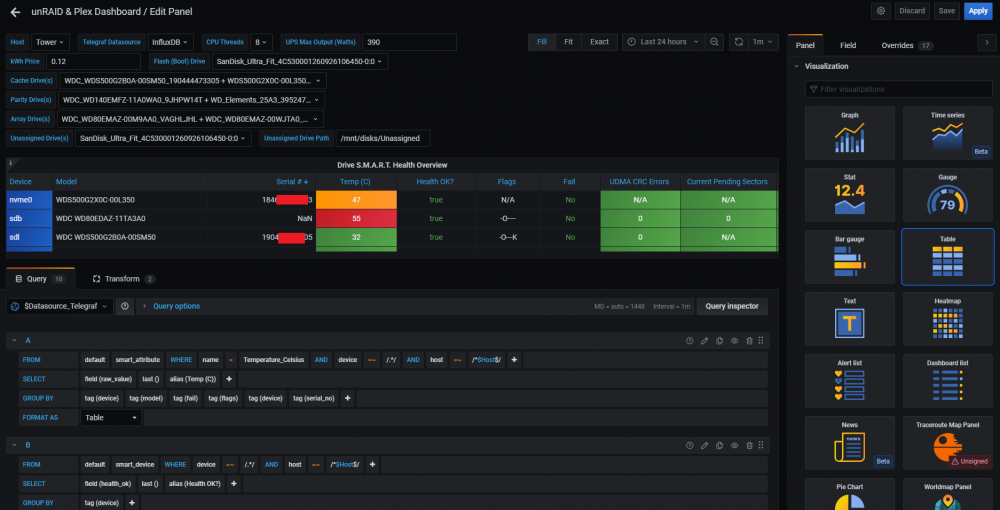
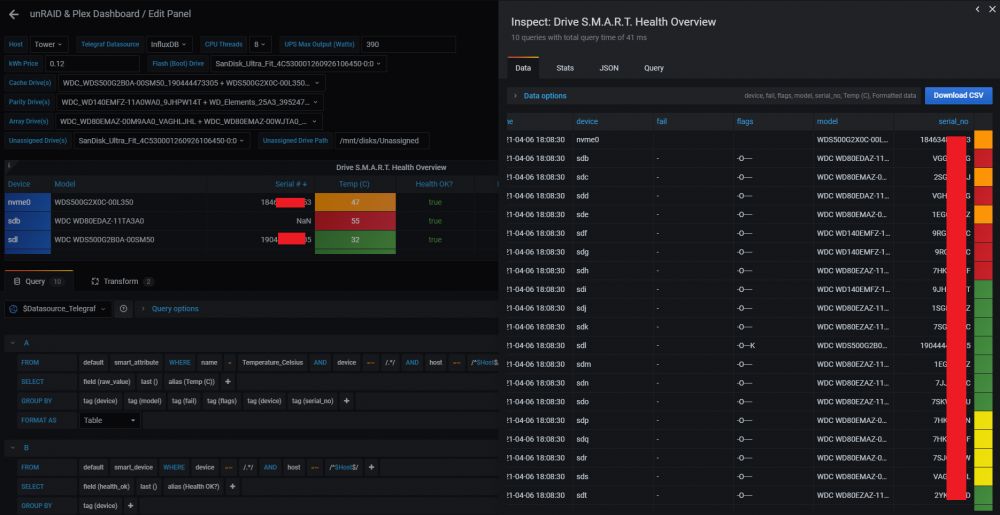
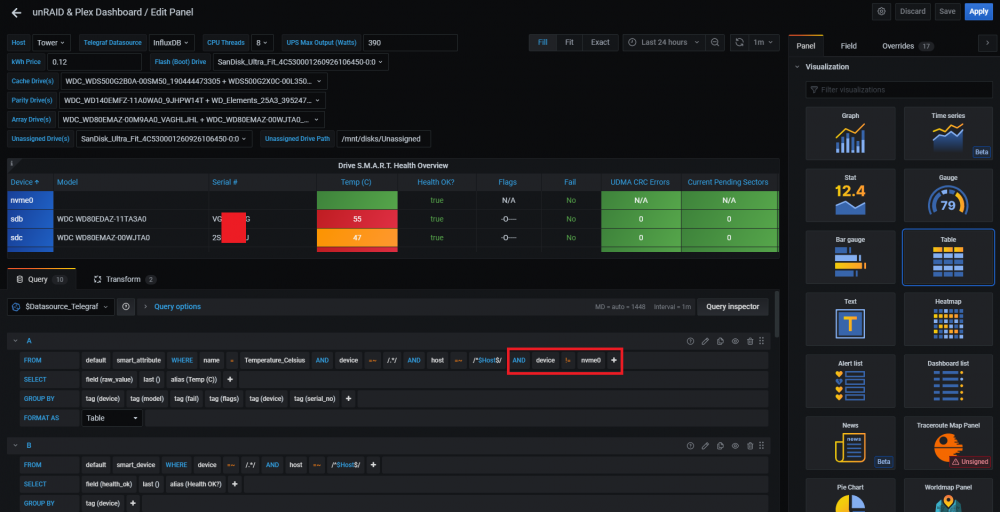
-
Hi,
Thanks for the continued development of this Dashboard its great, its so nice to have all the info in one place.
I have a bit of an odd issue that I can't figure out. I'm using UUD 1.5 (though the issues still appears in 1.6) for me. The Disk Overview section and the SMART Stat Table, dont show the serial numbers of the drives correctly (with the exception of 2 SSDs), they seems to show as NaN or a single number.
I thought it was something in my Telegraf Config at first, but noticed that the Temperatures graph show them correctly. I have checked the overrides for the Table and can't see any obvious issues, I even tried setting an override to format this column as a string but no luck. Oddly when I goto Query Inspector and then Data, it shows the correct Serial Number there.
I am probably missing something really obvious here, but if anyone has any suggestions, they would be most welcome.
Thanks
-
19 hours ago, jbreed said:
Sure thing! Let me know how it looks.
Just updated to the new container this morning, all looks good, no issues from me.
I have run my regular network scan and it completed as expected.
Thank you for doing that, most appreciated
-
Heya,
Is there any chance the container can be updated to use a more recent version of Nessus please, as the current version reports Vulnerabilities with itself (1 High, 2 Low).
I have been manually updating it myself, by downloading the deb file and running "dpkg -i <path_to_deb>" which seems to work, but would be useful to have it done by default.
Thanks.
-
A few suggestions if I may, from my experiences in the Cloud Infrastructure World;
First, Reviewing Docker Folder Mappings (and to some extent VM Shares).
Do all you Docker Containers need read and write access to non appdata folders? If it does, is the scope of the directories restricted to what is needed, or have you given it full read/write to /mnt/user or /mnt/user0 ?
For example I need Sonnarr and Radarr to have write access to my TV and Movie Share, so they are restricted to just that, they don't need access to my Personal Photos, or Documents etc. Whereas for Plex, since I don't use the Media Deletion Feature, I dont need Plex, to do anything to those Folders, just read the content. So it has Read Only Permissions in the Docker Config.
Additionally, I only have a few containers that need read/write access to the whole server (/mnt/user) and so these are configured to do so, but since they are more "Administration" containers, I keep them off until I need them, most start up in less than 30 seconds.
That way, if for whatever reason a container was compromised, the risk is reduced in most cases.
Shares on my VM's are kept to only the required directories and mounted as Read Only in the VM.
For Docker Containers that use VNC or VMs, set a secure password for the VNC component too, to prevent something on the Network from using it without access (great if you don't have VLAN's etc).
This may be "overkill" for some users, but have a look at the Nessus or OpenVAS Containers, and run regular Vulnerability Scans against your Devices / Local Network. I use the Nessus one and (IMO) its the easier of the two to setup, the Essentials (Free) version is limited to 15 IPs, so I scan my unRAID Server, VMs, and a couple of other physical devices and it has SMTP configured so once a week sends me an email with a summary of any issues found, they are categorized by importance as well.
I don't think many people do this, but don't use the GUI mode of unRAID as a day to day browser, outside of Setup and Troubleshooting (IMO) it should not be used. Firefox, release updates quite frequently and sometimes they are for CVE's that depending on what sites you visit *could* leave you unprotected.
On the "Keeping your Server Up-to-Date" part, while updating the unRAID OS is important, don't forget to update your Docker Containers and Plugins, I use the CA Auto Update for them, and set them to update daily, overnight. Some of the Apps, could be patched for Security Issues, and so keeping the up-to-date is quite useful. Also, one that I often find myself forgetting is the NerdPack Components, I have a few bits installed (Python3, iotop, etc), AFAIK these need to be updated manually. Keeping these Up-to-Date as well is important, as these are more likely to have Security Issues that could be exploited, depending on what you run.
Also on the Updates, note, if you have VM's and they are running 24/7 keep these up-to-date too and try and get them as Hardened as possible, these can often be used as a way into your server/network. For Linux Debian/Ubuntu Servers, you can look at Unattended Upgrades, similar alternatives are available for other Distros. For Windows you can configure Updates to Install Automatically and Reboot as needed. Hardening the OS as well, is something I would also recommend, for most common Linux Distros and Windows, there are lots of guides useful online, DigitalOcean is a great source for Linux stuff I have found.
If something is not available as a Docker Container or Plugin, don't try and run it directly on the unRAID Server OS itself (unless, its for something physical, e.g. Drivers, or Sensors etc), use a VM (with a Hardened Configuration), keeping only the bare minimum running directly on unRAID, helps to reduce your attack surface.
Also, while strictly not part of Security, but it goes Hand in Hand, make sure you have a good Backup Strategy and that all your (important/essential) Data is backed up, sometimes stuff happens and no matter how much you try, new exploits come out, or things get missed and the worst can happen. Having a good backup strategy can help you recover from that, the 321 Backup method is the most common one I see used.
If something does happen and you need to restore, where possible, before you start the restore, try and identify what happened, once you have identified the issue, if needed you can restore from Backups to a point in time, where there was no (known) issue, and start from there, making sure you fix whatever the issue was first in your restored server. I have seen a few cases (at work) where peoples Servers have been compromised (typically with Ransomware), they restore from backups, but don't fix the issue (typically a Weak Password for an Admin account, and RDP exposed to the Internet) and within a few hours of restoring, they are compromised again.
Other ideas about using SSH Keys, Disabling Telnet/FTP etc, are all good ones, and definitely something to do, and something I would love to see done by default in future releases.
EDIT: One other thing I forgot to mention was, setup Notifications for your unRAID server, not all of them will be for Security, but some of the apps like the Fix Common Problems, can alert you for security related issues and you can get notified of potential issues quicker than it may take you to find/discover them yourselves.
-
9
-
-
Another +1 for this. If the VM/Docker Container has no paths mapped to the array, and runs on an unassigned device, allowing it to start with the array running and to continue when the array is stopped would be most useful.
-
Would it be possible to open all external hyperlinks in a new Tab?
For example, I was installing a Docker Container and in the Overview section of the Add Container Page, it had a link to the Docs on GitHub, I clicked on the link and it took me from my unRAID Page to the Git Hub page, ideally, it would open up in a new tab so I can stay on my unRAID page and refer to the docs as well. - I know I can right click and open in a new tab, but I think for external links, this should probably be the default behavior?






New Remote Vulnerability for Samba (CVE-2021-44142 & CVE-2022-44142)
in Security
Posted
Slackware is a "proper" Linux distro, it just depends on how its maintained.
I don't think its unreasonable to ask for security patches and fixes in a timely manor, especially for something that has a very high score, and is a core part of the product, even more so since Limetech/unRAID is supposed to be taking a more secure by default stance now.