

MammothJerk
-
Posts
109 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by MammothJerk
-
-
20 hours ago, MAM59 said:
you may have been fooled by a known UNRAID problem: the CPU Usage also counts in blocked IO.
If a disk cannot write fast enough to empty the buffers, the process is halted and cpu usage shows 100%.
Of course, all other processes have to wait too, so it looks like the machine is halted. But it will recover soon again.
(of course until the copy still exits, this will happen over and over again)
You can tell if your 100% are real 100% or come from the IO halt, if you look at the CPU temperature. If machine is stalled but temp is low to normal, you are facing the blocked IO problem. If CPU is almost glowing, you really see 100%.
If you have the IO problem, there are some ways to make it smoother. But for getting totally rid of it you usually need faster disks/controllers/cache drives.

The CPU temp is pretty much stable at around 50C, does this look like the IO problem then?
I have a 9201-16i coming in soon for expanding my setup as opposed to the onboard sata ports so maybe that will help?
my cache drive is a kingston a400 960g, maybe adding another one in to the pool would help with the speed?
my normal array drives are a bunch of wd red 20TB's but as the issue is only with the cache drives im not sure they are relevant.
Any ideas of tests that i could do to troubleshoot this better?
-
Unraid: 6.12.4
X10SL7-F - Dual Gigabit Ethernet LAN ports via Intel® i210AT
Intel® Xeon® CPU E3-1231 v3 @ 3.40GHz
32gb ddr3 ecc memory
My usual CPU usage is around 30-40% with 50 containers running and i've noticed that the cpu usage on all cores hits 100% whenever i'm downloading anything at high speeds (20MB/s+).
This is so bad that almost everything else on the server stops working, if i'm downloading and trying to update my docker containers the updates per container can take up to 10 minutes each.
It usually brings the rest of the containers to a crawl as well, i cannot open plex or jellyfin, i cannot open radarr/sonarr either, they will just open the webui "loading" pages where they say something like "loading battlestation" and this similarly will just keep loading upwards to 10 minutes. and forget about doing any operations like imports and renames.
The downloads are writing to the cache so the parity calculations shouldn't be a factor, even looking at the parity when the cpu is at 100% shows no writes being made.
I tried stopping all containers except for resilio sync and still all cores are pinned at 100% when downloading at 40-50MB/s to the cache pool.
pausing the downloads immediately brings down the cpu usage to about 10%.
I've tried looking at the CPU usage via top but it never shows more than 20% being used by resilio sync even though the unraid webui shows 95-100% on all cores
is this expected behavior? does this CPU always hit 100% usage when downloading at around 50MB/s in other systems? does it have something to do with the NIC? is it unraid? is it the filesystem?
Thanks.
-
On 8/23/2023 at 9:30 AM, bonienl said:
For upcoming version 6.12.4 I added a new option to specify the life time of notifications. Default is 3 seconds.
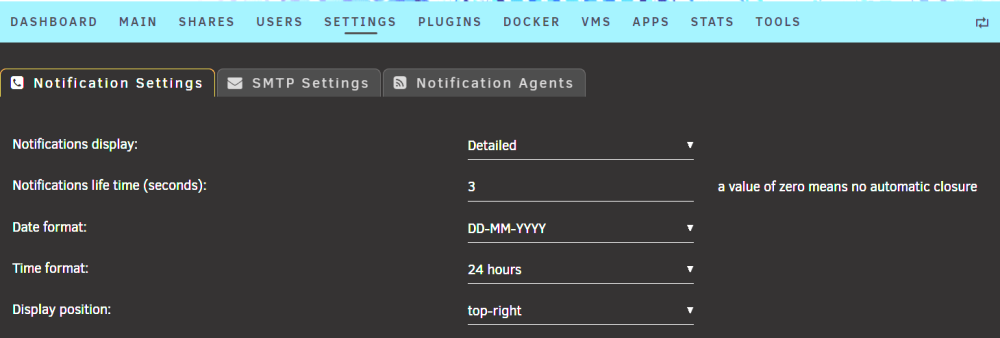
Thanks!
-
The feature of mandatory auto-closing of notifications was added in 6.12.0.
I would like for this to be an optional change as in adding a toggle for this behavior, possibly in Settings -> notification settings. (maybe a 3s|5s|10s|off dropdown or something.)
Seems like an unnecessary change and i would like to get the old behavior back.
-
 1
1
-
 1
1
-
 5
5
-
-
2 hours ago, Jaycedk said:
Hi there.
First of thanks for making this plugin.
I keep getting backup failed, but can't seem to figure out why.
Can I get someone to look at this log ?
Thanks i advance
")
[17.06.2023 10:14:07][GoAccess-NPM-Logs][debug] Tar out: tar: /mnt/user/appdata/Nginx-Proxy-Manager-Official/data/logs/proxy-host-2_access.log: file changed as we read it; tar: /mnt/user/appdata/Nginx-Proxy-Manager-Official/data/logs/proxy-host-3_access.log: file changed as we read it [17.06.2023 10:14:07][GoAccess-NPM-Logs][error] tar creation failed! More output available inside debuglog, maybe.-
1
-
-
On 1/28/2023 at 7:20 PM, jbrodriguez said:
that's odd, it should accept the custom flags.
in the history tab, is the "-H" showing in the rsync commands ?
on the hardlinks issue @jbrodriguez
On 1/11/2023 at 10:25 AM, MammothJerk said:I just moved the contents of an old 8tb drive to a new 20tb drive, unbalance reported 7.76tb were moved but the 20tb disk itself shows 13tb used.
I had a lot of hardlinks on the 8tb drive, all of which broke when using unbalance to move all the contents to a different disk.
I have a couple more disks that i want to do this operation on, but if i could i would like to avoid having to recreate several terrabytes of data, to then just delete when i recreate the hardlinks.
Is it possible to keep hardlinks intact when scattering a drive to one other specific drive? All the relevant data is in /mnt/user/media/
On 1/12/2023 at 7:33 PM, MammothJerk said:from my reading of the webui, unbalance seems to run different commands per each subdirectory one level deep

this would break all of my hardlinks from seeding to movies even though they are correctly in the same unraid share. but unbalance is moving their directories separately for some reason.
Seems to be some logic that moves the subdirectories separately which is what is breaking the hardlinks between said subdirectories.
i.e if i have two hardlinked files
/disk9/media/movies/movie.mkv /disk9/media/seeding/movie/movie.mkvthe /movies/ and /seeding/ subdirectories get moved separately and the hardlinks break.
-
1
-
-
the "Delete backups if they are this many days old:" settings doesn't seem to work for me, i still have backups from late december and early January even though my limit is set to 30 days.
-
I found that the support link at the bottom of the page links to the old support page, and you haven't added yourself to the credits.😁
-
from my reading of the webui, unbalance seems to run different commands per each subdirectory one level deep
this would break all of my hardlinks from seeding to movies even though they are correctly in the same unraid share. but unbalance is moving their directories separately for some reason.
-
I just moved the contents of an old 8tb drive to a new 20tb drive, unbalance reported 7.76tb were moved but the 20tb disk itself shows 13tb used.
I had a lot of hardlinks on the 8tb drive, all of which broke when using unbalance to move all the contents to a different disk.
I have a couple more disks that i want to do this operation on, but if i could i would like to avoid having to recreate several terrabytes of data, to then just delete when i recreate the hardlinks.
Is it possible to keep hardlinks intact when scattering a drive to one other specific drive? All the relevant data is in /mnt/user/media/
-
/mnt/user/appdata/PlexMediaServer/Library/Application Support/Plex Media Server/Cache/PhotoTranscoderis in my excluded folders so it shouldn't even be looking at it in the first place
i am able to open the folder but they are all empty
EDIT: Appears that when i migrated the settings from the old version there was a stray space in the excluded folders path which i assume is what messed it up.
running another backup now and will get back to you
+1 to the suggestion about better excluded folders management

-
1
-
-
Just updated on one of my servers and it ran into errors
2022/12/08 20:09:50 [15577] total size is 1,010,836,695 speedup is 19.19 [08.12.2022 20:09:52] Backing up libvirt.img to /mnt/user/Backups/libvirt backup/ [08.12.2022 20:09:52] Backing Up appData from /mnt/user/appdata/ to /mnt/user/Backups/appdata backup/[email protected] [08.12.2022 20:09:52] Separate archives disabled! Saving into one file. [08.12.2022 20:09:52] Backing Up /usr/bin/tar: ./PlexMediaServer/Library/Application Support/Plex Media Server/Cache/PhotoTranscoder/d4/: Cannot savedir: Structure needs cleaning /usr/bin/tar: ./PlexMediaServer/Library/Application Support/Plex Media Server/Cache/PhotoTranscoder/8f/: Cannot savedir: Structure needs cleaning /usr/bin/tar: ./PlexMediaServer/Library/Application Support/Plex Media Server/Cache/PhotoTranscoder/6d/: Cannot savedir: Structure needs cleaning /usr/bin/tar: Exiting with failure status due to previous errors [08.12.2022 20:25:42] tar creation failed! [08.12.2022 20:25:42] done -
I recently started getting the error
"Share " " contains only spaces which is illegal Windows systems."
and the button to "Ignore error" is not responding when i click on it. tried in both edge and firefox
and to be clear the share is created with alt+0160, not spaces, so windows does not have an issue with it. Not sure if you are able to differentiate that in the plugin.
-
5 hours ago, PSYCHOPATHiO said:
Since I upgraded to the 6.11 RC I can no longer download or even see any plugins.
All I get is "Please wait, retrieving plugin information ..."
Any fix for this issue?
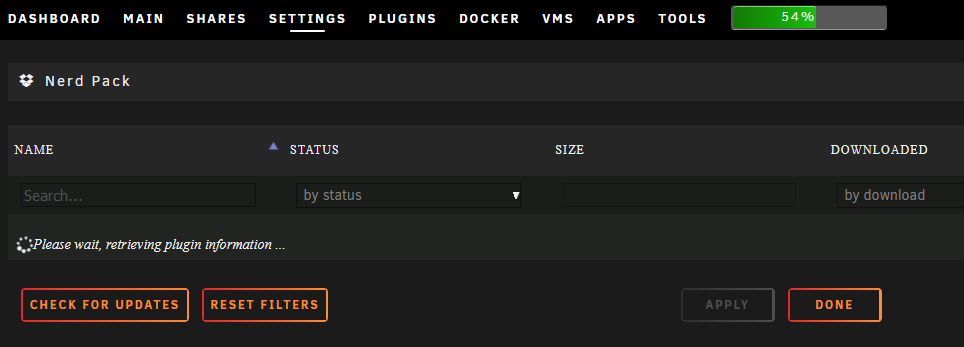
i have this same issue. 6.11.0-rc3
-
8 hours ago, technoluddite said:
I've just seen exactly this behaviour (takes many minutes to progess from "[info] Writing changes to Deluge config file '/config/core.conf'...", WebUI nonresponsive, and deluge-web pinning one cpu core at 100%), and have found what was causing it for me.
'\appdata\binhex-delugevpn\web.conf' had grown to over 40MB causing both the config-parser script and deluge-web to choke trying to parse it. Looking at the file this was because there were thousands of 'session' entries; I'm guessing that it caches active sessions to the webui in the web.conf, but for some reason never clears them, causing the file to grow out of control.
Stopping the image, deleting all of these entries (bringing the file down to a much more reasonable 620bytes), and restarting the image made everything start up quickly with the webui working as normal.
Hopefully that's helpful to someone!
i don't have this issue but i was curious so i checked my web.conf as well.
i have 25,000 lines of session entries but the file is only 883kb. for your file to balloon past 40mb means you've got over 1,000,000 lines of session entries.
that definitely sounds to me like there's a different issue somewhere rather then it just being the active sessions never being cleared.
-
I'm playing around with the console trying to set up some execute scripts and in trying out a couple of commands i keep getting the same error.
trying to resume a torrent that is currently paused i'm sending in the console
deluge console resume oertbgoyertboy792345796ygand
deluge-console resume oertbgoyertboy792345796yggibberish being the hash or $torrentid in the execute script
both giving me the error message
Could not connect to daemon: 127.0.0.1:58846 Password does not matcham i using the correct commands here or am i missing something?
-
49 minutes ago, tjb_altf4 said:
I think this would be the applicable fix:
https://github.com/binhex/documentation/blob/master/docker/faq/vpn.md
You may also be hitting the Docker network configuration default security model, where containers on the default network cannot communicate directly with the host (Unraid).
Yes that does indeed work!
I only recall having to mess with VPN_INPUT_PORTS and was not aware of the VPN_OUTPUT_PORTS variable as well.
Thanks!
Spoilerthis somewhat works but is not the most ideal solution.
the container i'm calling for in the execute script has to be on the "delugevpn" container network with --net=container:delugevpn for this to work.
then be called as localhost:port in the execute script.
this container can then not communicate with anything else outside the "delugevpn" network so even more containers need to be added to the "delugevpn" network.
If this is the only way then that is what i have to do but i was hoping there was another way.
-
22 hours ago, pinion said:
I have a script I'm trying to run on completion of a file (via execute plugin). It basically just runs a curl command but it is timing out. In trying to troubleshoot the issue I've realized that I can curl google.com and get results and of course get my ip with curl ifconfig.co but when I try to curl my unraid IP it times out. I'm actually trying to issue a curl to an API at 192.168.0.5:9393 but regardless just trying to run curl on any internal IP times out. Is this expected behavior or do I have some other issue?
i have the exact same issue, trying to run execute plugin calling another docker container but the request is timing out
-
the culprit was plex trying to analyze a old .mkv file that links to 2 other .mkv files.
the 2 mkvs were originally released as anime episodes but then got bundled into a movie, so to save space i used segment linking to create a file that acts as the movie without using double the space.
-
I've had this issue every other day for a while now, not quite sure what causes it.
i've been suspecting Plex detecting intros so i tried a couple of days to turn off the docker when the "fix common problems" scan is running but it didn't seem to correlate with the error appearing or not.
Here my diagnostics
-
also an issue in firefox 98.0.1 in unraid 6.10.0-rc4
-
i've got a server built of unused parts from older computers in a define r4. the current motherboard only has 6 sata ports whilst i need 10 in total.
from what i understand i need to add an HBA card to my system to expand its storage capacity.
i'm running 6x3tb WD reds + couple SSDs so nothing crazy needed in the speed category.
my motherboard has an open pci, and a pcie slot.
from what i understand all i need is an HBA card in IT mode that fits in my motherboard, and then a SAS to SATA cable to connect the card to my drives.
hitting up ebay this is something that looks promising: https://www.ebay.com/itm/143299825144?epid=14036731155
cheap, IT mode, and specifically mentions unraid.
Am i missing something here or would the mentioned card work just fine in my situation?
i'm not quite sure what to look for.
-
if your container writes to a separate log file you can read it with notepad++ nad the documentmonitor plugin.
appears SOL if the container doesnt have a log file though.
-
only seems to be an issue when theres a lot of writes to the log at the same time but not much that i can do about that





[Support] - Unifi-Controller: Unifi. Unraid. Reborn.
in Docker Containers
Posted
I'm trying to figure out why my container doesn't see the network traffic for the unraid server it is running on (192.168.1.111)
i did not change anything in the docker template, running "11notes/unifi:8.1.113-unraid"
I believe i set up the container without changing any settings other than disabling automatic updates.