

BR0KK
-
Posts
30 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by BR0KK
-
-
You will need to set the filesystem permissions on disk. By default, the timemachine user is 1000:1000. Granting Permissions to write to the directory can be achieved by executing the following command on the host (Unraid): sudo chown -R 1000:1000 /mnt/user/timemachine/ The backing data store for your persistent time machine data must support extended file attributes (xattr). Usually for shares in the Unraid Array this is not a problem. Remote file systems, such as NFS, will very likely not support xattrs. This image will check and try to set xattrs to a test file in /opt/${TM_USERNAME} to warn the user if they are not supported but this will not prevent the image from running. Also note that if you change the User Name (TM_USERNAME) value that it will change the data path for backup data inside of the container from /opt/timemachine to /opt/value-of-TM_USERNAME.Is there a linux newb proof human readable version of this ....
I know I need to set some permissions but where in what shell?
Thx
-
So ... i am a total newb and don't know how to operate this ... How do i get to my shares and mot that 17 GB directory i seem to be locked in ?
-
Ohh neat ... but my old unraid setup is janky af and based off of a esxi vm ....
I just want the data off of there so I will probably have to migrate the license to that new usb stick... better anyways the one from that unraid vm is ancient ...
I want a complete new setup hence forth everything but the hdds is new ...
Thx btw
")
-
I did dl the myserver plugin after login it tells me that unraid myserver is experiencing outaged and usb backup is grayed out
I have a license but I want to copy my data off of that unraid vm I currently got l. Then transfer the license to this setup
-
Ok thx
I need n active license for that and unraid has an outage :D?
-
So I am a total newb ....
I have this plugin installed ... the newest version.
I want to auto backup my USB stick to the array.
I see a warning on the plugin page....
NOTE: USB Backup is deprecated on Unraid version 6.9.0 It is advised to use the Unraid.net plugin instead
What the hell is the .net plugin and where can I find it ?
Thx
-
Thank you verry much my instance is up and running again
-
Well i don't know what happened but my UR setup was stable for at least a month and now im facing mayour problems.
I use UR mainly as a file dump server and as a backup reopo for my VEEAM Backup Server.
I recently switched from a rock solid N40L based system to an ESXi (Plop) based system wich worked like a charm.
My storage devices are connected to a M1015 HBA (2x 8 TB WD whites , 2x 480 GB Sandisk SSDs , 4x 250 GB Crucial SSDs) wich is passed throgh to the VM (the complete HBA).
This worked fine till now:
I know, i know .... UR doesn't "like" support vm based systems!
I need some advice what the heck is goning on here:
VEEAM alerted me that the backup didn't work. I investigated a bit and eventualy found out that UR was not working right.
The GUI was still up and runnning and could be used.
I couldn't acces the server via \\tower\ nor \\192.168.178.3\ (Explorer)
So i tried the obvious and went for a quick reboot; after the reboot i tried to access it again but couldn't...
And on top of this the GUI wasn't showing up either.
Logging in via the ESXi console was possible and ther was the message to go to UR IP Adress
I tried this a couple of times (poweroff or reboot via the Shell) but it wouldn't come back to life :/
I looked at the logs but .... linux and me speak very different languages...
I assume ther is a faulty harddrive in there somewhere (sdh? <--- nice feature woud be to not print out the device name but rather the serialnumer or some other more fedined marker. How should i figure out wich device this refers to when the macine is offline. The GUI does do this so maybe *hint*)
Thank you
-
Is there a way to find out what usb stick works and what doesn't. The one i have here runs fine with ESXi on multiple machines. Why doesn't the creator recognise the stick at all; WIndows does, rufus too ?
thx for the reply
-
So whats to do when the stick i dedicated for unraid doesn't get recogised in the USB creator tool?
It's a bog standard 32 GB USB 3 stick from "intenso" (the small ones). I formatted it to FAT32 and the Volume is labled UNRAID (30 GB available)....
Can i dl an ISO somwhere and use rufus to copy unraid to this usb stick?
thx
-
Awesome this ssems to work. The UPS icon is there and it can read the battery from my USB connected smartups 750 through unraid
Now i need to figure out how to shutdown the esxi itself incase of a power failure
-
Yes Yes .... my mistake for not reading correctly
-
im currently trying to understand how to remove drives from the cache pool/ pool .... without loosing everything ....
It would be nice if you could provide screenshots of how to do this... so that the windows script kiddies like me have it easier to understand what needs to be done....
I followed the guide to in the faq but now im lost.....
1. Stoped the array
2. unassigned the cache drives (2 in my case) --> my mistake for mot reading....
3. set the drive slots to none
4. Started the array
Nothing happened ? In the guide it said that there will be a move process after this but that didn't happen?
Cache Pool is now "not mountable" because of the missing ssds....
This i think is clearly my mistake but....
Maybe its possible to implement an easier sollution like a "unassign drive and move" botton to the Main Page. One that allow the user to click on and dissable one specific drive at a time while a process in tha background takes care of the data beeing mooved
Im very hesitant to try the other option about "forgetting the config", since that went bad real quick last time (complete Dataloss - Also my mistake)
-
System is back up and working correctly after the rebuild. It even recogised disk 5 in the pseudo backplane. I'll watch this closely and as soon as the new hardware arrives ill try to move everything there.
Thank you verry much for the help provided
-
Yeah i know this system isn't great but it worked for a while.
Everything works and for the age and configuration of my N40L the performance i get isn't realy that bad

The N40L backplane is directly connected to the mainboard. It features a sff-8087 to 4x SATA breakout. Not a real Backplane maybe its connected internaly as a portmultiplyer?
The Portmultiplyer (sylba 8 port SATA) is where all the small and the cache drives are connected to.
The N40L will get its retirement eventually. New Hardware is on the way anyways; thought i try this on my N40L before investing in a more stable permanent sollution. Maybe as a backup system for my unraid based on freenas
 (before unraid i used that os and it also worked OK on the N40L)
(before unraid i used that os and it also worked OK on the N40L)
-
Ok i have some reading to do.
I restarted my server and it seems as if my backplane is dying. The drive is not recognised when i leave it in the slot it was before.
On a diffrent port (just sata) i clould assign the drive again and now the rebuild is in progress. 8 TB will take a day to restore

Thank you for the help
tower-smart-20191021-1936.ziptower-diagnostics-20191021-1737.zip
-
28 minutes ago, itimpi said:
Note that a failed drive is not "rebuilt from parity". It is rebuilt by reading all the 'good' drives in conjunction with the parity drive. This is why you never want untrustworthy drives in the array as a rebuild requires that all 'good' drives are. read without error. It is possible this is what you meant but it may also mean that you do not understand how parity works.
I do have 2 parity disks installed (each 8 TB) wich in theory should give me 2 drive failure coverage. What do the other disks (smaller 1 TB drives and cache drives) have to do with parity or rebuilding process?
16 minutes ago, johnnie.black said:SMART report will be a good indication, you can also run an extended SMART test.
I'll look at the smart values and do a SMART test. As disk 5 is inside a backplane, can i disconect this drive and connect it via a normal sata port on the same machine without loosing the array?
-
Is there a way to inspect the drive before i put it back into unraid. Externaly, maybe via a HDD testing tool to figure out if the drive has an issue.?
12 minutes ago, itimpi said:Any data written while the drive is being emulated will be there.
Does that include reboots or complete powerdowns?
-
Yes i'll try that as soon as i get home.
Drive 5 is connected va a backplane. The same backplane all the 8 TB Drives use)
Is it safe to just reboot or do i have to stop the array first (Stop the array, set it to "do not start automatically" and then powercycle the unit)?
Can i just power down the unit and restart it?
What happens to the data that is not written to the disk yet? (
Drive 5 is beeing emulated via the parity drive; right? What if, there was data written to the emulated drive no. 5 while beeing in this state?.
The data isn't that important but i'd like to know more about how this works (or not)
If the drive comes back online i'll assume that unraid will try to rebuild this drive from the parity drive's (does that include the data that might have been written to the emulated disk?)
Thank you for the help so far
-
Hi, just attached the diagnostic logs
-
Hi there,
I'm new to unraid.
Everything worked fine for a long time and i started to get compfy with my installation.
I wanted to do a backup of my server with duplicati and got this running. It copied arround 900 GB of 2.5 TB to my NAS verry slowly ... but ok ... i can wait
.
Yesterday i went to check on my server and it displayed an error message that one of my 8 TB drives has failed.
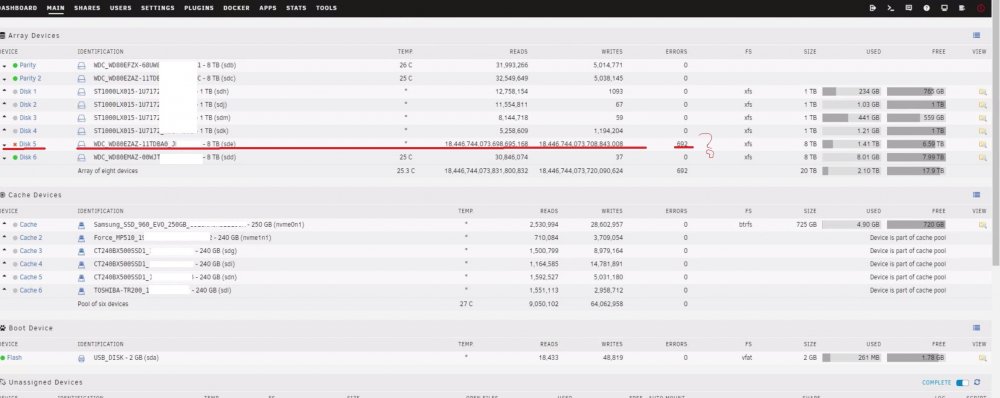

I'm not sure how to proceed now. As i've read unraid is currently emulating the one 8 TB drive via the parity drive and my data is safe for now.
I need to get a spare drive today ....
I dissabled all dockers besides krusader and there are no vms on that machine.
This drive is brand new and successfully did the preclear..... is there a chance the drive is fine and unraid just had a "hickup".
I have a second 8 TB Data drive which currently sits empty (Picture 1, last drive)
I know that i can install krusader and copy over the files but because im a noob i'm not sure how to do so fasely without causing issues with the shares? ( Picrure 2)
System, nextcloud and appdata are folders created by unraid. If i go with krusader can i just copy them from disk 5 to disk 6?
Thank you
-
Resurected my old n trusty N40l which now has 12 GB of DDR3 ECC installed.
-
Is there a way to use a local (or remote) nas to point the backup to?
As i understand the local filesystem can't access my nas because cloudberry is inside a docker. This means i need to mount the nas to the docker?
-
OK i need to read up before dooing something i regret


Timemachine Application Support Thread
in Docker Containers
Posted
The shell tells me "no such file or directory"
Sorry I'm a newb and thx for the help.