

glave
-
Posts
179 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by glave
-
-
Quote
It sounds like you are doing a simple upgrade of server hardware (MB, PS, RAM, and enclosure) in that case, you move not only the HD's and cache disks but also the Unraid USB boot disk.
That's not really what I'm doing here. I'm taking the drives out of an existing Unraid server and attaching to a different existing Unraid server. This existing server has a lot of containers already running on it.
-
Quote
Any shares that exist on diskUnraid will suddenly be on dockerUnraid.
Would it? I'm not moving the flash drive at all.
The existing disks in dockerUnraid's array are not a priority at all. They are just two 300gb 2.5" disks with no data. This is purely about getting diskUnraid's drives reconnected without losing data from the original array on diskUnraid.
-
I have two Unraid servers, one is filled with storage and the other mostly doing container things. For ease of reference, I'll call them diskUnraid and dockerUnraid.
dockerUnraid only has 2 drives in it's array, and they are empty. The primary stuff happening there are pool devices and containers. I'm converting diskUnraid to be a DAS, and dockerUnraid will be using those drives now.
I know I will need to first destroy the array on dockerUnraid but I'm wondering on how I bring in the drives from diskUnraid and keep the data intact. Do I just populate them all inside dockerUnraid in the exact same drive assignments they had in diskUnraid? Will parity (I have dual) be destroyed? -
I have a Norco 4220 case and an old i7, but I also have a HP DL380 Gen10. What options do I have to to use the HP as compute but attach the 20 HDDs to it?
I'm currently running unraid on both and using fileshares to access the HDDs but I feel this is a bit less than ideal.
-
Between my two servers I have one that isn't behaving the same with display. I'm trying to set both of them to 'small' but on one server it reverts back to 'normal' every time I hit Apply. Once upon a time I had the theme engine plugin, but that has been removed from both servers.
Is there something I can reset or check that could be keeping the font size setting from sticking?
-
1 hour ago, trurl said:
You can already get Notifications about how full disks are. Disk Settings has utilization thresholds (%) for all disks, and you can override that for individual disks in the Settings for each disk.
If you wait for "No space left on device" it is already too late.
Unfortunately they don't work in some situations, although I haven't tracked down the specifics yet. I have a 50GB minimum set on each share, yet I still have a few disks than continue to fill up past that without triggering warnings.
-
Has anyone created a script that can parse the log file looking for a string and then send a notification using unraid's notification system? I'd like to search for "No space left on device" in the log file, just wondering if something similar may already exist before I reinvent the wheel.
-
Rebuilding both parity at the same time makes sense, but wouldn't replacing both data disks at the same time cause data loss? I thought if I lose/remove more than 1 data drive at once then I lose data?
-
My current parity drives are 12TB and I've got two 14TB on the way. I'll be swapping the 14TB drives in as parity, removing two 4TB drives and replacing them with the 12TB drives that are currently parity. What is the easiest/fastest order of operations that I can achieve this? Right now I'm thinking it will take 4 parity rebuilds to pull this off, which will take a very long time.
-
I recreated the USB with stable release, copied over the config directory and restored the key. I was able to use the 64gb drive that I bought, but I'm not sure if there will be some consequence (?) later since the maximum is stated at 32gb.
-
Also just noticed on the download page that a 32gb drive is the max? The replacement I got was 64gb. Is it possible to use this at all?
-
What is the workflow to move over?
I used the USB creator tool and then copied over all the files from the old drive, but when it attempts to boot I keep gettingFailed to load COM32 file menu.c32 boot:A few more details- My drive died last night right after upgrading to 6.10rc2 and it was doing it's reboot. I tried to use the USB creator tool and told it to use 6.10rc2 but it appears that something is broken with that option, as the tool erases the drive, pauses, then closes the program without warning. No files are put on the drive. I knew this wasn't correct, so I tried again and this time chose stable. This worked as I expected and downloaded the zip at the end and extracted it. I then copied my old flash drive contents on to the new drive. Should I have done that? Should I just move the config folder only?
-
Last night I upgraded from 6.10 rc1 to rc2. After rebooting I'm getting a kernel panic-
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(2,0)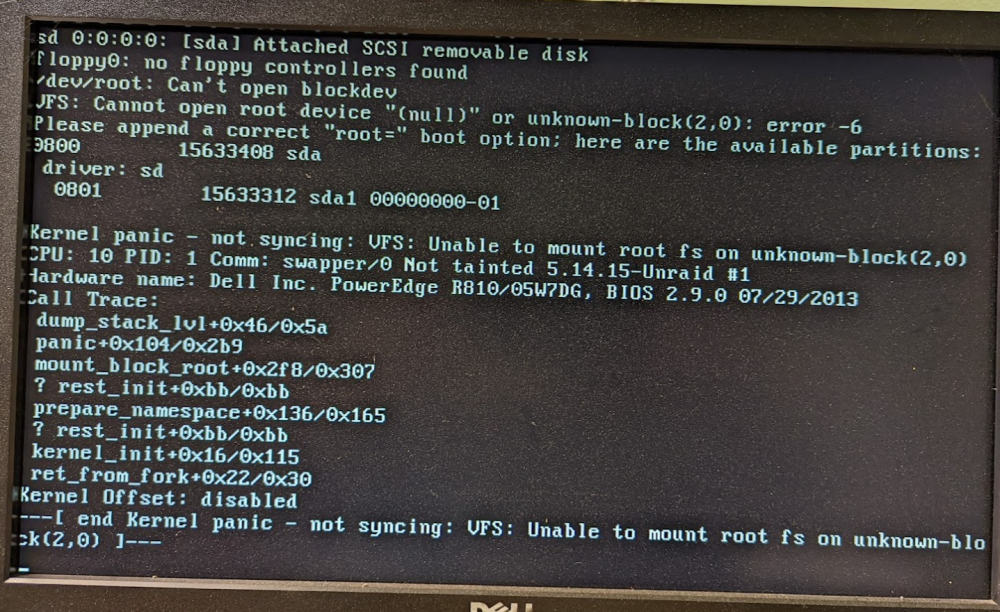
This is a pretty new one for me, I wouldn't have expected it to fall over. I'm wondering if it's the flash drive...
Any help appreciated!
-
Is there a way to monitor disk space on an unassigned device? I've had a few instances where they fill up and I discover it because some process has stopped working in a docker due to full disk.
-
Has anyone else had any issues with the web ui not actually displaying anything? The page title loads and you can view source code, but nothing is actually rendered on the page.
-
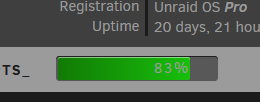
Contrast on the used space % of the array is pretty difficult to read. So far everything else is looking good.
-
 1
1
-
-
Should I be able to see devices attached to a Dell PERC H700? I've got a single drive attached to it and the array itself can see the drive, but UD doesn't show it.
-
Is there a way to trigger a notification to be sent from unraid's notification system?
I have sonarr move TV episodes it replaces to a .deletedBySonarr folder and over time they can get pretty big if I don't catch it. I'd like to make a script that checks the size of that folder and if it's larger than X GBs send me a notification.
-
1 hour ago, jonathanm said:
@Squid was maintaining a solution for that here,
but when the delay and start order got built into the stock gui, I don't know if it's possible to use this plugin currently.
Yes, I've had this plugin forever and I actually checked it before posting. I didn't realize that part about being able to use a different IP/port. I'll give her a shot!
-
4 minutes ago, WashingtonMatt said:
On the docker tab, select advanced view. Then set the wait time in the autostart column.
While that could work, it wouldn't really solve the problem. If the other server didn't come up for some reason I'd still be eventually launching the docker without ensuring the presence of the mounts.
-
I've seen similar situations to this posted before, but it's not working as I'd expect.
I'm running Plex docker on 1 server, and my primary storage shares are on another. I use unassigned devices to mount the storage shares via NFS. On occasion, something may happen and the servers reboot. The server that has Plex boots MUCH faster than the storage one, and even though I have the NFS directories set as RW:Slaves in docker, Plex will still launch and thinks I no longer have files so it clears the DB and I have to rescan.
Is the RW:Slave flag supposed to prevent the docker from launching? Is there an elegant way I can achieve this elsewhere if not?
-
15 minutes ago, glave said:
Yea, it resolves, but I appear to be unable to connect to or ping any of the ips.
Name: us-east-1-elbdefau-1nlhaqqbnj2z8-140214243.us-east-1.elb.amazonaws.com
Addresses: 52.86.8.163
34.232.230.241
52.205.36.130
Aliases: hub.docker.com
elb-default.us-east-1.aws.dckr.ioLooks like AWS has a bad route. 54.240.229.185 is the last hop I can hit before it dead ends.
-
20 hours ago, Taddeusz said:
It's hosted on Docker Hub, hub.docker.com. I was just able to pull it to my laptop with no problem. Can you nslookup hub.docker.com?
Yea, it resolves, but I appear to be unable to connect to or ping any of the ips.
Name: us-east-1-elbdefau-1nlhaqqbnj2z8-140214243.us-east-1.elb.amazonaws.com
Addresses: 52.86.8.163
34.232.230.241
52.205.36.130
Aliases: hub.docker.com
elb-default.us-east-1.aws.dckr.io -
I can't pull the image down. Is the address still correct?
TOTAL DATA PULLED: 0 B



Looking for a little guidance on moving array from an existing Unraid server into a different already existing Unraid server
in General Support
Posted
LSI 9300-16i in IT mode? That's in containerUnraid and is what the drives will attach to. Would that be ok?