

-
Posts
25 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Astryl
-
-
On 8/1/2023 at 12:36 AM, giganode said:
RMi and HXi series use corsairmi.
At the moment, the following psus are implemented:0x1c0a, /* RM650i 0x1c0b, /* RM750i 0x1c0c, /* RM850i 0x1c0d, /* RM1000i 0x1c04, /* HX650i 0x1c05, /* HX750i 0x1c06, /* HX850i 0x1c07, /* HX1000i 0x1c1e, /* HX1000i with USB-C 0x1c08, /* HX1200i */
If you want to go for the hx1500i, I can try to integrate it. But for that we need to buy it.It's arrived, what do you need from me?
-
Has support for the HX1500i been added yet? Looking at a new PSU and want to get one compatible with this plugin still.
-
On 10/30/2022 at 3:05 PM, Squid said:
Have you uninstalled the original and reinstalled the fork from Apps?
Yes, this is UTD from your repo.
-
Working fine for months and now it seems that the context menus are disappearing again on 6.11.
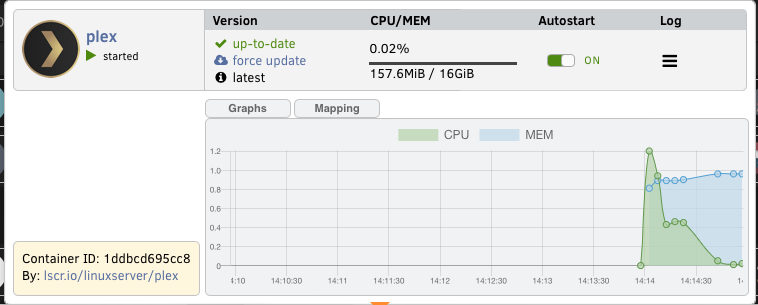
-
On 5/16/2022 at 9:17 AM, crafty35a said:
Mine all look correct. But I notice that your containers are showing different numbers for total RAM available. The 1.78Gib total you are seeing is the sum of the two containers that show 8GiB total RAM.
Are you somehow limiting the RAM available to some containers? if so, that's probably what's causing the numbers to not be included in the total.
Almost all of my containers run with CPU and Memory limits. The 1.78gb / 8gb is what's available for the first container in that folder. The other containers in the same folder are not adding to the aggregate total.
Attached is a screen on one of my folders. It shows a max of 512MB allocated; but I purposefully did not cap one of the containers in this folder to show that it is not displaying this properly.
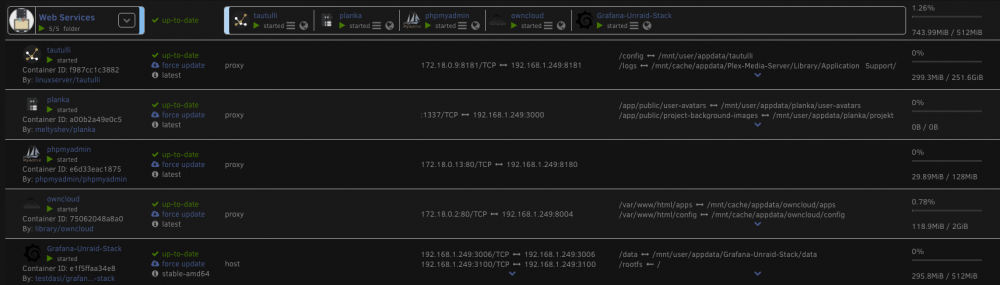
-
I use the dashboard fairly regularly and this would be amazing, please!
-
Anyone know how to get the folders to display the correct ram allocations and usage %s? Folders themselves don't aggregate the totals.
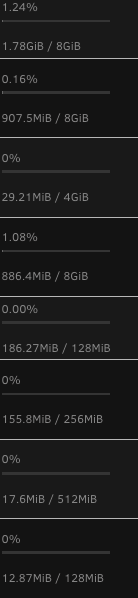
-
Use a production WSGI server instead. * Debug mode: off WARNING:werkzeug: * Running on all addresses. WARNING: This is a development server. Do not use it in a production deployment. INFO:werkzeug: * Running on http://172.17.0.9:5000/ (Press CTRL+C to quit) ERROR:root:Something went wrong while checkig for new Videos from BiographicsWanted to start using this to build my Plex youtube library since you've included the youtube-agent schema and I couldn't get meta data to load properly when trying to use TubeSync. However, adding anything via the GUI does not work; and after manually adding a channel to the monitoredChannels.txt I get this error with no other errors.
Any ideas?
-
Updating the VM to Q35 5.1 fixed this issue.
-
-m 65536 \ -object '{"qom-type":"memory-backend-ram","id":"pc.ram","size":68719476736}' \ -overcommit mem-lock=off \ -smp 1,sockets=1,dies=1,cores=1,threads=1 \ -uuid a1b3e671-4ac9-86b0-dfd8-b927bd0d0dc2 \ -display none \ -no-user-config \ -nodefaults \ -chardev socket,id=charmonitor,fd=33,server=on,wait=off \ -mon chardev=charmonitor,id=monitor,mode=control \ -rtc base=localtime \ -no-hpet \ -no-shutdown \ -boot strict=on \ -device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 \ -device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 \ -device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 \ -device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 \ -device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 \ -device nec-usb-xhci,p2=15,p3=15,id=usb,bus=pcie.0,addr=0x7 \ -device virtio-serial-pci,id=virtio-serial0,bus=pci.2,addr=0x0 \ -blockdev '{"driver":"file","filename":"/mnt/user/domains/Arcana/vdisk1.img","node-name":"libvirt-1-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-1-storage"}' \ -device ide-hd,bus=ide.2,drive=libvirt-1-format,id=sata0-0-2,bootindex=1,write-cache=on \ -netdev tap,fd=35,id=hostnet0 \ -device virtio-net,netdev=hostnet0,id=net0,mac=52:54:00:78:9b:47,bus=pci.1,addr=0x0 \ -chardev pty,id=charserial0 \ -device isa-serial,chardev=charserial0,id=serial0 \ -chardev socket,id=charchannel0,fd=36,server=on,wait=off \ -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 \ -audiodev id=audio1,driver=none \ -device vfio-pci,host=0000:4a:00.0,id=hostdev0,bus=pci.3,addr=0x0 \ -device vfio-pci,host=0000:4a:00.1,id=hostdev1,bus=pci.4,addr=0x0 \ -device usb-host,hostdevice=/dev/bus/usb/003/003,id=hostdev2,bus=usb.0,port=1 \ -device usb-host,hostdevice=/dev/bus/usb/007/002,id=hostdev3,bus=usb.0,port=2 \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on char device redirected to /dev/pts/3 (label charserial0) 2021-11-18T20:12:23.537143Z qemu-system-x86_64: vfio: Cannot reset device 0000:4a:00.1, no available reset mechanism. 2021-11-18T20:12:23.542112Z qemu-system-x86_64: vfio: Cannot reset device 0000:4a:00.1, no available reset mechanism.Played around with it some more. Seems the GPU isn't resetting, I already have the AMD reset app installed from CA. Not sure what changed in 72 hours that caused this to suddenly become an issue.
-
1 hour ago, JorgeB said:
Looks more like filesystem corruption, but those errors are not in the posted diags.
Yeah looking back at it, this is from today and may be related to my UD ssd for my plex media metadata and not relevant to the other issue.
Outside of changing slots on my GPU, does anyone have any insight here?
Last night I tried the following additional steps:
PCIe overrides from "Both" -> "Multifunction"
Adding "video=efifb:off" to my syslinux.cfg
Still freezes at the same place on either the new or old vDisk.
-
Nov 18 02:07:01 ORBITAL kernel: Plex Media Serv[40895]: segfault at 14e338ecb018 ip 000014e33d56caa3 sp 000014e33736d3c0 error 4 in Plex Media Server[14e33ccc5000+bae000] Nov 18 02:07:01 ORBITAL kernel: Code: 8b 45 08 49 8b 4d 20 48 89 ca 48 09 c2 0f 84 1a 02 00 00 48 39 c8 75 0e 49 8b 4d 18 49 3b 4d 30 0f 84 07 02 00 00 49 8b 4d 00 <83> 79 08 ff 0f 84 a5 01 00 00 41 8b 4e 10 83 f9 01 75 05 41 8b 0e Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS error (device sdc1): bad tree block start, want 1228455936 have 0 Nov 18 02:07:09 ORBITAL kernel: BTRFS info (device sdc1): failed to delete reference to Plex Media Server.4.log, inode 53909236 parent 268 Nov 18 02:07:09 ORBITAL kernel: BTRFS: error (device sdc1) in __btrfs_unlink_inode:4034: errno=-5 IO failure Nov 18 02:07:09 ORBITAL kernel: BTRFS info (device sdc1): forced readonly Nov 18 02:07:09 ORBITAL kernel: BTRFS: error (device sdc1) in btrfs_rename:9598: errno=-5 IO failureUh...
Is my cache pool dying? Good health reports on both drives...
-
AMD Threadripper w/ 590X GPU passthrough. Was previously stable for well over a year. Suddenly when I start it I can no longer get into windows. It either boot loops at the "preforming recovery" screen or freezing while loading on the TianoCore splash screen.
Attempted fixes:
Four different vBIOS roms.
New VM XML
New VDisk / Fresh VM (this worked temporarily up until Windows loaded & immediately bricked at a black screen)
Bind & unbound GPU at vfio.
I'm at my wits end, this previously worked completely perfectly without issue.
-
The Unbalance plugin could also do this with little to no hassel via a GUI. Which is what I did when I upgraded my cache pool.
-
Seconding this. I'd go as far as to say making dashboard elements able to be moved from column to column or hidden entirely as well.
-
On 9/2/2021 at 10:40 AM, Shomil Saini said:
*1 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 192.168.0.50, server: , request: "GET /movies/dupes HTTP/1.1", upstream: "uwsgi://unix:///tmp/uwsgi.sock:", host: "192.168.0.4:5000", referrer: "http://192.168.0.4:5000/"
Getting this error in app logs. Any clue?
Thanks
Same error here, following for solution.
-
Anyone else having issues with your VM becoming almost unusable if you leave it up for extended periods of time? I could leave Catalina on 24/7 with no issue.
-
Alright, got everything working finally! Opencore configurator helped a lot to get the autoboot set up & Big Sur is working almost perfectly. I ran the script to change the network adapter to the e1000 variant to enable Apple services and network settings still shows the VMXnet3 as the ethernet connector. XML lists the correct e1000 variant, any input?
-
 1
1
-
-
Still haven’t gotten opencore to work with this K95. Going to grab a keyboard from work and test if I can get beyond the splash screen with another keyboard. Seems odd that I’d have to do this when clover just worked.
-
Just now, ashman70 said:
It doesn't work for me at all, which is too bad as I'd like to try it.
Jazz if you Google:macOS Product: 001-86606, you will see it is indeed Big Sur
Yup got this handled.
Can boot into Big Sur no issue, installed the iCUE software.
Anyways, my K95 keyboard does not register in the opencore boot menu, but does work within the VM (I left it set to VNC & verified this). Is there a way for me to force opencore to autoboot into MacOS or ?
Tried USB hotplug as well, nothing from keyboard or mouse while in opencore.
-
7 minutes ago, mortenmoulder said:
Use Method 2 and use VNC in your browser. Don't passthrough anything until you're actually inside of macOS, as I bet any interference could stop it from working.
Note, any passthrough is after MacOS is installed. Old catalina vers never had this isuse. I'll keep playing with it.
Method 2 apparently tries to download snow leopard but never actually downloads anything.
The VNC desktop is: fb29ccf49415:0 0 ****************************************************************************** Have you tried the x11vnc '-ncache' VNC client-side pixel caching feature yet? The scheme stores pixel data offscreen on the VNC viewer side for faster retrieval. It should work with any VNC viewer. Try it by running: x11vnc -ncache 10 ... One can also add -ncache_cr for smooth 'copyrect' window motion. More info: http://www.karlrunge.com/x11vnc/faq.html#faq-client-caching 2021-01-03 14:48:58,451 Network Request: Fetching https://swscan.apple.com/content/catalogs/others/index-10.16-10.15-10.14-10.13-10.12-10.11-10.10-10.9-mountainlion-lion-snowleopard-leopard.merged-1.sucatalog 2021-01-03 14:48:59,178 Selected macOS Product: 001-86606Edit: Got big sur to download correctly after reloading the docker. Now to see if I get can it to boot after passthrough is done once I have it set up. I'll report back.
-
Finally got this set up with the new container. However even when installing Big Sur it installs catalina? Although it's downloading the Big Sur media. Also, when I do get it set up for passthrough, my keyboard doesn't appear to be passing through correctly as I can't actually click "return" to boot into the MacOS disk after initial installation.
Any input? Didn't have any of these issues before the container moved to opencore.
-
On 6/2/2020 at 1:13 AM, mikefromdot said:
Having an issue with managing instances/using them. I get this error when trying to manage them.
"This version of instance is not compatible with this ADS installation. ADS is version 1.9.8.6 but this instance is version 1.9.9.8"
Is there anyway that I can make my instances the compatible version or should I be waiting for a possible update for the container itself to the latest version?Having this issue now too with an updated ADS vers. Apparently the correct way to fix it is user "ampinstmgr updateall" which requires logging into the console as the amp user. Unless I'm missing something that amp user is created when you compile the docker but I have no idea how to figure out what the password is from the dockerfile. Any help?
-
This is awesome! I've been trying to get this to work forever. Just migrated my MC server. Is there a chance at updating this container to the newest vers of AMP? I'd love to be able to host Terraria as well.




Corsair RMi, HXi, AXi PSU Statistics - CyanLabs's fork
in Plugin Support
Posted
Bus 009 Device 003: ID 1b1c:1c1f Corsair HX1500i Power Supply
Sorry I'm late getting back to you, was waiting on custom cables for it.
Thanks!