

-
Posts
180 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by JustOverride
-
-
On 7/25/2023 at 6:19 PM, itimpi said:
This is a feature that is meant to be coming in a future release although I have no idea of the timescales. There were changes made in the 6.12.x releases to start getting ready for this.
This is likely to happen in the same timescale as the above feature. In the 6.13 release we have been told that the aim is to make the current Unraid 'array' just another pool type and then you can have any mix of pool types (including multiple Unraid 'arrays' if you want.
However having said that until it actually happens we cannot be certain when it will happen or if Limetech will deem some other mix of features to be higher priority.
🙃
I thought this was implemented but when I went to actually use it today I see that it isn't. I guess we wait now.
-
This seems like a great option for unraid. Should be added to unraid by default IMO. I haven't added it yet just because I can't be bothered to stay on top of it to ensure it works well. For example Nextcloud is already pushing its luck with the random issues it has that requires manual updates, etc.
-
I updated without backing up the USB, restarted without stopping the array...lolyolo
Updated without issues, no parity check, (everything went as expected).
Thank you team!
-
Not sure what kind of black magic you guys did but my Unraid server runs about 50w lower on idle. I read somewhere that someone mention they were having lower power usage too from this update. I'm still on 6.12.3 and my system is running pretty solid (I will upgrade once I'm ready to mess with ZFS, need a few new hard drives too).
Anyway, great job Unraid team!
-
 1
1
-
 1
1
-
-
11 hours ago, SimonF said:
Have a look at this post
I can't find this location and/or file:
"Upon boot, if all PCI devices specified in 'config/vfio-pci.cfg' do not properly bind, VM Autostart is prevented. You may still start individual VMs. This is to prevent Unraid host crash if hardware PCI IDs changed because of a kernel update or physical hardware change. To restore VM autostart, examine '/var/log/vfio-pci-errors' and remove offending PCI IDs from 'config/vfio-pci.cfg' file and reboot."
I found the second one, the config file. Where can I find this? (Don't have a var folder in the USB, and the 'logs' folder has other type of logs) So, I went and deleted the 'config/vfio-pci.cfg' file. Hopefully this will fix it, If it doesn't I'll edit and update.
1. If the system knows about it (by throwing the error) why doesn't it just fix it?
2. Please see one again. -
Getting this email when I start the server:
Event: VM Autostart disabled
Subject: vfio-pci-errors
Description: VM Autostart disabled due to vfio-bind error
Importance: alert
Please review /var/log/vfio-pci-errors
-
Upgraded from 6.11.5 to 6.12 without problems. Everything seems to be working fine...
...
but how do I reset the dashboard layout, I know I read it sometime before but I forgot. Doesn't seem to be something that is clearly visible.found it.. its the blue wrench at the main panel. -
Just checking back to report the issue. Seems like the slight OC I had on the CPU started to catch up to it. During Plex schedule tasks which are a bit CPU intensive caused the CPU to thermal lock. Once I turned the OC off now it reaches 83c (which is still a lot) but continues to run without issue. Looking to upgrade the cooler now, maybe just update the whole system as it was just an old gaming computer that became the server kinda thing.
Any recommendations?
-
I have copied the syslog from the USB's log folder.
-
On 2/20/2023 at 5:13 AM, JorgeB said:
Enable just the easiest option, mirror to flash drive.
Ok, Turned that option to Yes.
Meanwhile, here are the logs for this mornings crash using the previous settings I posted. Let me know if these help any. Also, curious to know where in the logs do you look? I was checking out \logs\syslog.txt
-
6 hours ago, JorgeB said:
Enable the syslog server and post that after a crash.
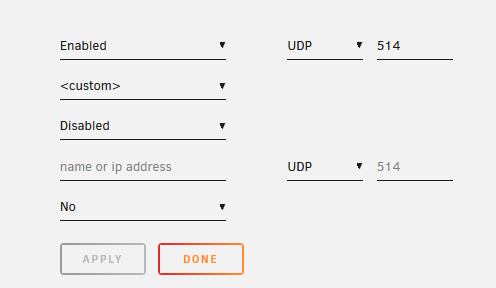
Is that it? It doesn't let me select the local syslog folder, the only option is '<custom>'.
-
Randomly Unraid becomes unresponsive. VM's weren't running, just Dockers but nothing new recently. Unraid cannot be reached from the web, cannot check physically as it is running headless. However, connecting a keyboard to the system to attempt a blind shutdown does not work (keyboard does not get power) and I have to forcefully reset/shutdown.
-
On 2/3/2023 at 2:16 PM, JorgeB said:
If you want to verify integrity you can use rsync with the checksum option, note that it will take a long time, unless there are suspected issues a normal rsync transfer should maintain integrity.
Could you provide me with directions on how I would go about using rsync?
-
So, asking for a friend...
What is the best way (verifying data integrity) to move the data out of Unraid into another data storage system like Truenas or just back into a regular disk? Like what is the actual safe process, because technically there are a bunch of ways of achieving this.
My assumption is:
1. Buy a new hard drive as large as the array.
2. Run pre-clear to ensure it is clear and to pre-test it.
3. Turn off dockers/VM's, have nothing using the Array.
then..
?4. Add the hard drive as a UD and copy everything from the array '/unraid/user/' using Krusader.
?4. Add the hard drive in another system, and then copy everything using robocopy (with a 10G nic).5. Wipe the USB and array drives and use a new system.
6. Move data back into new system.
-
12 minutes ago, JonathanM said:
How do you handle user shares that have part of their storage go away when that pool is down? For instance, I keep some VM vdisks on the parity array, and some in a pool. They all seamlessly are accessible via /mnt/user/domains, and I move them as needed for speed or space, and they all just work no matter which disk actually holds the file.
In THAT case, whatever uses the array would go offline and not work obviously for your particular scenario. But what WE'RE asking is for the VM's/dockers that remain in a stand alone or cache drive. There could also be a way to mark a VM/docker as 'keep in cache/alive' or w.e so that it is not moved to the array. Plenty of ways to implement it really.
(Edit) You know when you really look at it, what we want is to be able to keep our internet going while doing w.e that requires the array to go down. Pfsense, ubiquity, homassistant? etc. That's what we're really asking here. These things run mainly in RAM too so I'm not seen what the big problem is. -
On 7/24/2022 at 2:26 PM, irishjd said:
Hello, have some issues with your Dashy Docker package.
I recently had Dashy installed as a Docker container and all was well. I messed with it for a couple of days until it was all dorked up. I then decided to start over and remove it and the re-install it. Now, every time I try to install it, I get this error:
docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: rootfs_linux.go:75: mounting "/mnt/user/appdata/dashy/conf.yml" to rootfs at "/app/public/conf.yml" caused: mount through procfd: not a directory: unknown: Are you trying to mount a directory onto a file (or vice-versa)? Check if the specified host path exists and is the expected type.
I have tried uninstalling Dashy from APPS, open the GUI file manager and deleted user/apppdata/dashy, and I even installed Appdate Cleanup and ran it (it found some leftover Dashy data and deleted it). However, I still get the error when I try to re-install Dashy, I still get the error.
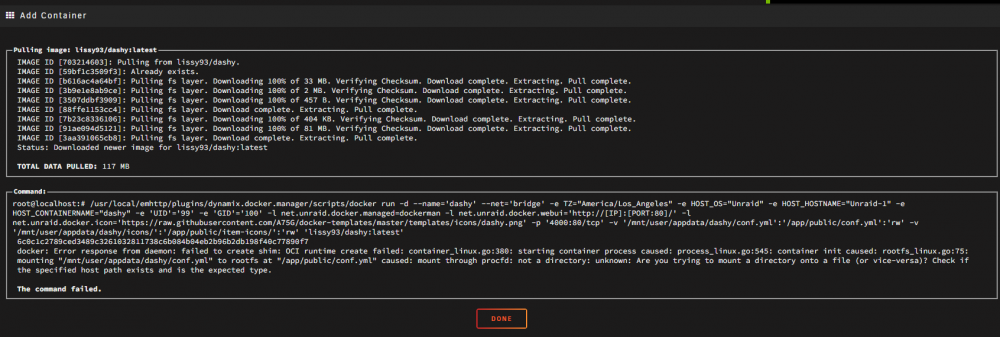
I have tried every Google hit I got on this topic to no avail. Can some one please point me in the right direction to fix this?
Same exact issue with me. Cannot get it going again.
-
Upgraded to 6.11.1 from 6.11 without issues.
Thanks LT team!
-
(user tab)
Group settings for users when selecting shares. Basically each created group has pre-set user access for the shares which will make it easier to assign access to users.
(share tab)
Groups for selected Disks (included, excluded). Perhaps have this also be the same groups as the 'Spinup group(s):'.
This will just make things easier to manage, and make these changes in one place (groups) and have it apply in their respective places automatically.
-
24+ hrs after update without issues.
@TexasUnraid Zoggy posted the commands in this tread for you to see what packets you have running from NP and which ones are installed in unraid. I was running NP before upgrading and then found out I didn't needed any packets. Just run those commands, save the list, then uninstall NP before upgrading. If you have issues with anything you try to run, you can check the list of running packets on unraid vs what you had before to know what is missing and an idea on what packet to install.
-
Upgraded from 6.10.3 to 6.11 without issues. Also, I thought I was going to need to reinstall some packets but everything seems to be working fine out of the box (at least my usual containers). Great job Limetech!
PS: I notice in the latest releases (including this one) having to remove plugins simply because Unraid is coming with these things already, which is a big plus! Again, great job team!
-
3
-
-
I also have perl and python that I need to use. Holding on upgrading until I hear about this.
-
10 hours ago, JohnnyP said:
Really exited about the ZFS groundwork here and looking forward to the upcoming official ZFS support. I actually switched to TrueNAS Scale for my new server because of ZFS. And although I enjoy TrueNAS Scale quite much, it just can not compete with Unraid in the HomeLab space. So thanks for all the great work!
Yea same here, I heavily second this.
LOVE unraid, but ZFS is sooo nice. Can't wait for the next update!
-
To claim the server, be sure to login using plex.tv. Then go to the settings under 'account' and you will see the claim button there. Be patient, things are running slow and you may have to do it 2-3 times since a lot of people are doing it too.
-
On 3/23/2020 at 5:31 AM, binhex said:
that is a volume mapping NOT an environment variable, you need to define the volume mapping AND set the value for TRANS_DIR to the volume mapping you defined, see Q1 from the link below for explanation:-
https://github.com/binhex/documentation/blob/master/docker/faq/plex.md
On 3/23/2020 at 8:57 AM, djgizmo said:Thank you for the link....
However the FAQ (and when I searched for the question in this thread) says to set the value for TRANS_DIR but does not say how to set this value. Is this just a custom variable (key/value) in the container configuration in Unraid? I'm not trying to be difficult, just want some clarification as it's not described anywhere in the thread or the FAQ.Wow same here. Thanks for everything, but please add that link to the top post.




My friends aren't interested so...
in Lounge
Posted
to