

AinzOolGown
-
Posts
88 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by AinzOolGown
-
-
On 5/27/2023 at 6:11 PM, snolly said:
So, firmware M3CR046 that solves the issue is not available from Crucial in a direct download. You need to use Windows and Crucial Executive software which is crappy and some people are mentioning that in order to update the firmware this way you need to be able to write to it and actually have something being written to the disk while updating otherwise the process will fail - which is totally ridiculous. So I made a bootable portable Win11 usb stick which took 3 hours to do and the Crucial software does not launch in there (crashes).
I then combed the interwebs and I found a user who contacted Crucial and they gave him the firmware file. Thread here and I also attached the FW on this post. You need to unzip the zip file and use the .bin file in there.
I had a BTRFS cache with 2 affected MX500 drives in there.
- Stopped the array
- Removed one if the MX500.
- Started the array and waited for it to rebuild the BTRFS cache.
- Now one of the MX500 was listed as unassigned device.
- Copied the FW .bin file somewhere in Unraid
-
run this command
hdparm --fwdownload /mnt/user/athens/temp/mx500/1.bin --yes-i-know-what-i-am-doing --please-destroy-my-drive /dev/sdb
- where first argument is the path to the .bin file and the second one is the name of the drive I need to update. In this case /dev/sdb
- rebooted the server and I checked that the drive has been updated to M3CR046 (click on the drive's name and go to identity tab)
- stopped the array and added the updated drive back to the cache.
- started the array and wait for the cache rebuilt.
- stopped the array removed the other drive and then do steps 3 to 9 for the second drive.
I hope this helps anyone who faces the same issue. Hopefully I will not face the same problems again.
Hi Snolly,
Thank you very much, this saved me
")
-
Wouuhouuuuuu seems to finally work !
And recovered my long awaited prod dockers yessssss !
Thank you so so much JorgeB
-
 1
1
-
-
Ok, Firmware updated, confirmed they are in M3CR046 and in the middle of the appdata restore
Finger crossed ^^
-
Oh, so the MX500 Can be a good choice after firmware update.
I'll try then. Finger crossed, it's a real pain to be unable to access prod Docker since 1 month 😭
Thanks again 🥇
-
Hi JorgeB,
Thanks to bear with me ^^
I'm thinking of changing the SSD, this time i'm searching possible unraid incompatibility for each SSD i think can be good but every model return plenty bad result...
Do you have some brand/model to recommend please ? -
Thank you very much JorgeB
I think i'm damned
Snolly's post say that to view the firmware information, we need to "click on the drive's name and go to identity tab"
Mine's look like this :

Also, my Crucial SSDs are not listed in /dev/
maybe because Unraid can't view past the HBA card ?
That doesn't make sense since it can mount them successfully
-
To follow, i see anothers btrfs errors, after invoking mover
I don't understand, SSD are new, câbles and HBA card are new too, i'm in despair
Here's the fresh diagnostic
tower-diagnostics-20231021-1207.zip
When i deleted/redone cache pool, there was no reformating proposed or done by the system
Do i need to force one ?Scrub was saying "no error found" before invoking mover
-
Hi
")
So, i replaced the card just now, and tried to reactivate VM, but the list is empty
Maybe it is linked with the cache settings in shares
I changed them, but maybe have to invoke mover ?
Thanks !
P.S. I have a backup of libvirt.img
EDIT : Nevermind, i replaced the libvirt.img and all VMs reappeared
-
1
-
-
Ok, thank you very much :)
-
Hi
So i received HBA Card and was wondering how to proced the cleanest way
Do i scrub SSD like this (when they're still connected to RAID Controller) before replacing RAID Controller by HBA Cardor :
1/ Replace RAID Controller with HBA Card2/ Scrub SSD
3/ delete + redo Cache pool
4/ Restore Backup ?
Please
-
Hi
I copied what i can
Deleted the cache pool / pluged new SSDs / recreated a new cache pool and assigned the new SSDs with new cables
Then i reswitched appdata on "only" cache and done a CA plugin restore
Plugin said restoring complete but i have a notification saying error occured
Syslog indicate a lot of btrfs error
I switched to Discord somewhere inbetween, and it seems that my RAID controller card is the culprit
Synd & Kilrah helped me and they advised to replace my card by a 9300-8i, so i ordered one and now i'm waiting for it to arrive and retry a CA restore
Thank you JorgeB for your help and patience, when you're stressed, it's a big help to have support !
Will repost the next steps when i'll try with the new card.-
1
-
-
Sorry JorgeB, rsync gives me errors too
cmd was :
rsync -a /mnt/cache/appdata/ /mnt/user/Backup-Saves/TowerDockers/Cache/appdata/
I tried a CA Backup and same, it gives errors 😱Ran a Filesystem checks on Cache, attached logs
-
Can i just copy the content via SMB and do the opposite when the new drives will be installed ? (sorry i prefer to double-check, there's some prod Dockers for my business and that would be hell to lose anything
)
-
Thanks JorgeB
Here it is -
Hi
So, i followed this process and changed all shares that use cache to "Yes". VM & Dockers are disabled but mover have finished and shares (appdata/system) remain on it.
I opted to completely replace my cache drives/SATA Cables
Can i just save the remaining content elsewhere and move it back when the new cache pool will be operationnal ?
Is there a better way to move the remaining files to the array ?
And, how to do this the right way ? (to conserve permissions and such) i have a Mac and PathFinder ready for that
Also, i have a share set to "no" for cache, but strangely the last files created on it are on cache O_o
Thank you
-
Thanks JorgeB
That reminds me... Sorry i forgot to tell you, just some days before this behavior, one disk of my array went offline 2 or 3 days. Unraid emulated it and i noticed just some hours later by chance. I changed a cable and rebuilt array. All seemed good to me, but in fact, it might have corrupted the array ?
If this is it, how can i correct that please ?
i read about some "scrub" command, i have it for cache array but not for data array
Will it erase all cache ? I wont lose any data right ?Thank you
P.S.: Installed Squid's script from your link, thanks again !
Included most recent logs, it start to worry me
In the meantime, i had a notification "Error on cache pool - No description" -
Hi Squid, thank you
Yep, i figured that and done testings when i built the server, but all the tests was successfull so i decided to keep them
It's been 4 years and never had a RAM issue since. If it is really a RAM problem, then i don't understand how it can be all ok since 4 years and suddently is not ok anymore
Memtest86 also tells me everything's fine 😭
-
Hi there
Since some days (i'm running solid since 4 years), my dockers stops gradually and it's very hard to make all the systems run again fine (and it shortly redo the same errors :/)
When i try to restart them, unraid show an Execution Error so dead end
I've searched and found some post talking about bad RAMs and i ran 2 (paralleled and unparalleled) MEMTEST86, which PASSed fineAlso found ie this topic that talk about a full cache but it doesn't seem to be the case for me either, so i'm a little lost
root@Tower:~# btrfs dev stats /mnt/cache [/dev/mapper/sdk1].write_io_errs 192912 [/dev/mapper/sdk1].read_io_errs 145891 [/dev/mapper/sdk1].flush_io_errs 1086 [/dev/mapper/sdk1].corruption_errs 628 [/dev/mapper/sdk1].generation_errs 0 [/dev/mapper/sdj1].write_io_errs 0 [/dev/mapper/sdj1].read_io_errs 0 [/dev/mapper/sdj1].flush_io_errs 0 [/dev/mapper/sdj1].corruption_errs 0 [/dev/mapper/sdj1].generation_errs 0 [/dev/mapper/sdl1].write_io_errs 0 [/dev/mapper/sdl1].read_io_errs 0 [/dev/mapper/sdl1].flush_io_errs 0 [/dev/mapper/sdl1].corruption_errs 0 [/dev/mapper/sdl1].generation_errs 0I'm attaching diagnostics and some logs if anyone can point me where i can head next to fix this issue please
Thank you very much in advance !
-
On 5/15/2022 at 11:50 AM, Adeon said:
Hey, i installed your Netbox container and it stared up fine (Postgresql14 container is installed).
But after i created a user and tried to login (netbox accepted my credentials) iget this error in the webUI:
<class 'redis.exceptions.ConnectionError'> Error 99 connecting to localhost:6379. Cannot assign requested address. Python version: 3.10.3 NetBox version: 3.0.12-dev
And this in the Container log:
/usr/local/lib/python3.10/site-packages/django/views/debug.py:420: ExceptionCycleWarning: Cycle in the exception chain detected: exception 'Error 99 connecting to localhost:6379. Cannot assign requested address.' encountered again.
If i delete the cookies netbox starts up fine again, but as soon as i try to login i get the same errors.
I also had this in the Unraid Systemlog:
nginx: 2022/05/15 11:46:49 [error] 8247#8247: *8020 connect() to unix:/var/tmp/netbox.sock failed (111: Connection refused) while connecting to upstream, client: 10.0.20.10, server: , request: "GET /dockerterminal/netbox/token HTTP/1.1", upstream: "http://unix:/var/tmp/netbox.sock:/token", host: "10.0.10.20", referrer: "http://10.0.10.20/dockerterminal/netbox/"
nginx: 2022/05/15 11:46:49 [error] 8247#8247: *8209 connect() to unix:/var/tmp/netbox.sock failed (111: Connection refused) while connecting to upstream, client: 10.0.20.10, server: , request: "GET /dockerterminal/netbox/ws HTTP/1.1", upstream: "http://unix:/var/tmp/netbox.sock:/ws", host: "10.0.10.20"Hi !
I just installed Netbox with PostGres15 and got the exact same errors&logs
I don't saw any response to this post but maybe i missed it ?
Do someone now how to fix this please ?
Thank you very much in advance !
EDIT : So, switched to another Netbox docker repo and all's fine with this one
Thanks nonetheless -
On 7/24/2022 at 3:35 PM, mjeshurun said:
https://help.nextcloud.com/t/all-files-lost-after-nextcloudpi-upgraded-to-v1-48-2/142529/7
I just need to learn how to run occ with NCP installed as an unraid docker app.
Hope someone here can help me with the commands needed to run occ.
Hi
You can actualy have access to /var/www/nextcloud by clicking on "console" in the docker's icon menu
In my case, this folder's content are pretty much totally gone so i can't use these commands
Edit :
So, i re-thought all this and decided to let go of Nextcloud.
It's been pretty much 10 years i run this and the maintenance time is just too high
It broke itself too often, the DB crash, the software do what it please, in short it's not suited in production, in my case at least.At side, i also run Synology NAS for some years, both personnaly and professionnaly, and it it so much more rock solid, never had any trouble !
And it possess the same functions as Nextcloud, can do webdav, auto file-upload (pictures/videos/you name it), sharing etc, so much better choice.
Goodby high maintenance time and welcome just enjoy a working synchro/server/services without doing much.
Thank nonetheless for the help and good luck
-
Hi !
Yesterday my NCP made seppuku, that is so strange
8AM, i'm heading to work like always
In the middle of my way, i received notif about some connection problems. It happends from time to time if the synchro runs when i have a poor mobile network, so i just discarded it.
It persisted for some hours, so i tried to connect to my Nextcloud instance via the mobile app, and it gave me "No files".
Thought my server just froze so decided to wait 'till i'm home.
7PM, home, server is all good, all service running except Nextcloud and i can't connect to it (but i can connect to NCP's admin)
I don't understand what's going on, i haven't changed anything in config, there was just a parity check running
Bellow the logs & informations
- When i click on "WebUI" in Unraid NCP docker's menu, i now have this in place of Nextcloud's login screen :
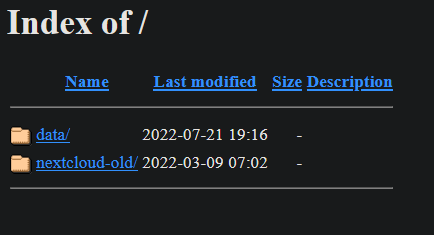
- There, if i correctly understand, it tells that the last DB operation was 22 Jul at 07:34
- NCP's System Info :
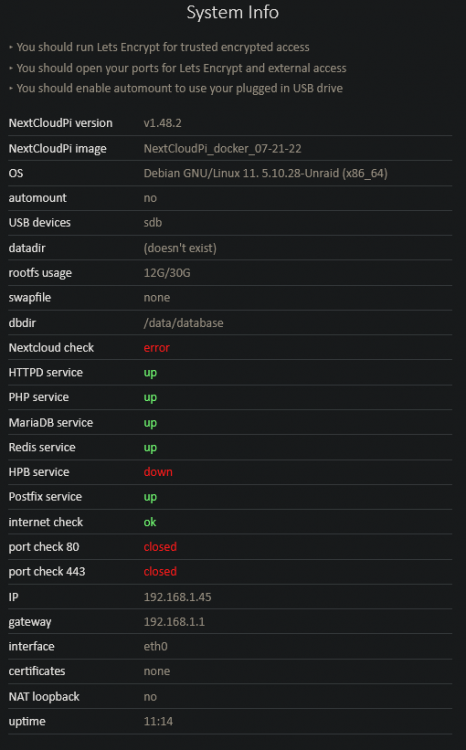
Do someone ever saw this ? O_o
Thank you in advance
P.S.: Made this morning the latest NCP docker's update but no change
Already rebooted the server and tried to reinstall docker
/data/nextcloud.log is empty
tower-syslog-20220721-1732.zip NCP docker's log.txt NCP -data- tree.txt
-
5 minutes ago, dlandon said:
You don't need to use the cli to clear the disk. Enable Destructive Mode in UD settings and use UD to clear the disk. Click on the red X next to the serial number.
Show a screen shot of the disk in UD.
Thank you very much !
That solved the issue ^^ -
Hi there !
")
I just shuked a new WD 12Tb drive and wanted to preclear it with this new plugin
First, there was no way to have the preclear option show, then i read that the disk must not contain any partition, so i deleted it by the cli.
Now the little preclear icon show on unassigned partition but the preclear fail everytime
And if i go on the plugin UI, it doesn't list the WD 12Tb at all
P.S.: i Tried to use the
wipefs -a /dev/sdlcli (for my case) but fail again
Do you have any idea please ?
Thank you !
-
Hi
")
It would be fabulous to have the "simple" option to disable a certain wireguard peer like this : https://github.com/WeeJeWel/wg-easy (just by unticking the peer line) without to delete it (actual behavior), please !
(i have Dynamix wireguard)
Thank you very much





[Support] FoxxMD - elasticsearch
in Docker Containers
Posted
Hi !")
I, too, can't run this docker properly
Tried several different versions (but in 7.** flavor because wikijs only accept 6.* or 7.*)
- userscript is in place and running
Here's the conf:
The short log from elasticsearch docker related to wikijs is joined
And the error in WikiJS docker :
If anyone have an idea, thank you !")
DockerLog.txt