

omartian
-
Posts
105 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by omartian
-
-
Hi Guys-
Having some slow transfer speeds on my unraid server and was hoping you guys can lend some insight.
Before i would transfer files locally and would be in the 110-120 MB/s range. Lately it's been in the 60 MB/s range.
I first thought it might be the disk i'm writing to (disk 10) because that's when i noticed the slow speeds. When adding it, i had to shrink my array and remove some smaller drives to make room for it.
My first step was checking to see if it was a disk or cable issue. I moved data using unbalanced (diag file taken during a transfer) between disks. I moved data from disk 6 to disk 10 (the disk i suspected) and was at 62 MB/s, i then moved data from disk 10 to disk 6 and had the same speed. I took disk 10 out of the equation and moved the same file from disk 6 to disk 5 and the speed was slower at 45 MB/s.
Next, I power cycled my wifi router, gigabit switches and swapped out the ethernet cables from my Verizon fios box all the way to my pc and my unraid server. Did not make a difference.
I'm debating on swapping sata cables in my unraid box but if it was a faulty sas-sata cable, wouldn't some of the moves in my first step not be affected?
i wanted to reach out here and see if there is something i'm missing. Any and all help is much appreciated. Thank you.
-
On 11/4/2023 at 1:34 PM, Opawesome said:
FYI, I found a comment under one of SpaceInvaderOne's video on YouTube that someone figured out how to finalise the "stop array" operation when this problem occurs (link) :
I hope this workaround will help until, hopefully, this issue is fixed.
This worked for me as well.
-
 1
1
-
-
2 hours ago, JorgeB said:
That script should not be used with current releases, you can try this workaround.
This looks like it worked. Thank you. Anybody else seeing this i used these command lines in terminal where DiskX = disk that is caught in unmounting loop under the log (in my case disk2)
dd if=/dev/zero of=diskX bs=1M count=310
mkfs -t xfs diskX
mount diskX /mnt/diskX
Like magic, the array stopped and i was able to continue on w/the steps in the video.
-
Hi guys-
Trying to shrink my array using spaceinvaderone's option 2 seen here:
I was able to succesfully run the clear disk user script but when i try to stop the array, i get the "array stopping - retry unmounting disk share(s)..." error in the bottom left corner.
I have stopped VM's and docker. I don't have any terminal windows open. When i check the log, I see this on a loop (disk 2 is the one i performed the clear disk script on):
Dec 22 04:17:03 Nasgard emhttpd: Unmounting disks...
Dec 22 04:17:03 Nasgard emhttpd: shcmd (1139124): umount /mnt/disk2
Dec 22 04:17:03 Nasgard root: umount: /mnt/disk2: not mounted.
Dec 22 04:17:03 Nasgard emhttpd: shcmd (1139124): exit status: 32
Dec 22 04:17:03 Nasgard emhttpd: Retry unmounting disk share(s)...in terminal ive tried this and this is what i see:
root@Nasgard:~# losetup
NAME SIZELIMIT OFFSET AUTOCLEAR RO BACK-FILE DIO LOG-SEC
/dev/loop1 0 0 1 1 /boot/bzfirmware 0 512
/dev/loop0 0 0 1 1 /boot/bzmodules 0 512
root@Nasgard:~# umount /var/lib/docker
umount: /var/lib/docker: not mounted.
root@Nasgard:~# umount /dev/loop2
umount: /dev/loop2: not mounted.I've attached my diagnostics.
Any way to unmount my disks so i can remove disk 2? I don't want to risk rebooting the array because it looks like it'll lead to an unclean shutdown and prompt a parity check which is what i was trying to avoid.
-
On 12/13/2023 at 8:03 PM, jkexbx said:
I'm trying to just use the commands and sometimes after I run the umount command, and run the dd command, the progress will run at ~400kb/s with no way to stop it. I end up having to reboot.
Has anyone run into this before and found a better way to unmount reliably? I found the same issue occurred with the script.
umount /mnt/disk8
dd bs=1M if=/dev/zero of=/dev/md8 status=progress
Did you ever figure out how to unmount reliably? i was able to run the script, but when i tried to stop the array, it hung up on unmounting. Ended up having to do a non-clean shutdown and had to run a 38-hr parity check. I need to remove 2 more drives from my array and want it to be smoother next time
Edit: this terminal command at the end of this post allowed me to unmount my disk. Hope it helps someone
-
On 12/13/2023 at 9:06 PM, jkexbx said:
Are you referring to this thread?
Or do you mean an alternative to using the umount /mnt/disk8 command?
I've found that command is extremely unreliable when running the dd bs=1M if=/dev/zero of=/dev/md8 status=progress command.
What happens currently:
- Run the umount command
- The disk size changes to a random number
- I then run the dd command, and progress is running at 400kb/s
- I fail to kill the running dd using every method available
- I stop the array, but it fails
- I hard shutdown the server
- It comes back up
- I try to mount the array, but it's in some half broken state where VMs can start, but the GUI still allows you to modify disks
- I then do another reboot through the GUI
- Everything comes back normally
- The disks I'm trying to zero show unmountable: wrong or no file system
- I run dd again on them and it runs fine.
I did use the command fine previously, and the only thing different was I first mounted the disks in SMB to double check they were empty. Once the current command finishes, I'll try that. Not sure how that makes a difference, but I think that's the only thing different between when it worked previously and now.
So had a very similar thing happen. Script ran w/o issue, but when going to unmount my disk, i received the unmount error. I tried the unmount script, but no luck, iwas able to shutdown my system, but when it came back up, it started a parity check.
Should i let the parity check w/the now zeroed drive? If i receive some sync parity errors, should i write to parity?
I'm reluctant to perform the new config step without running the parity sync. Let me know how to proceed.
-
7 hours ago, Kilrah said:
Nothing to do with the script itself but if you have reconstruct writes enabled for the array then any write will read all other disks, yes.
Thanks for the reassurance
-
So, i'm running the script on my machine and it's clearing the drive i'm trying to remove, I'm getting writes to parity and the drive being cleared, but I'm getting reads on all my other drives. Is that supposed to happen w/this script?
-
4 hours ago, JorgeB said:
Flash drive dropped offline, try a different port, ideally USB 2.0, and if it keeps happening replace the flash drive.
Great! Will do. Thanks for looking at it.
-
Hi guys-
I'm getting this error on my flash boot drive. it's a usb 2.0 drive that's been doing great for the last 2 years. attached is a diagnostic.
I have a flash backup from one month ago. Was able to reboot and the error is gone.
Is my drive dying? Should i just create a backup from last month's files or will that transfer over the issue which has been going on with this drive?
-
4 hours ago, JorgeB said:
Were the diags saved after the problem? There's nothing relevant logged that I can see.
I restarted the server after the issue. Should have save a diagnostic right then and there. if it happens again, i'll do that. Thanks for looking over it.
-
Hi Guys-
Having an issue with my server that's been rock solid for the last year. I was trying to access some local files on my nas as i've done many times before.
After about 10 secs, txf goes from 120 Mb/s down to 0. I restarted the array and saw that under the boot disk on the home page, i had an error that said "error code ENOFlash3". After turning off my system, i put the boot drive into another PC and scanned it for errors. When none popped up, I put the flash drive back on my unraid machine and it fired out w/o issue, this time w/o a boot drive error code. However, still getting the same issue with transfers.
I've attached my diagnostics. After rebooting it, i created a zip backup of my OS drive. I was under the impression that you can only swap your boot drive 1x/year so before i did that, wanted to get your input re: the diagnostics. Also, didn't know if there was a corrupted item on the boot drive, would this backup i just made also be corrupted.
My next most recent backup of the boot drive is 12/2020.
Thoughts?
-
On 7/29/2021 at 5:59 PM, simono5 said:
Hi mate, I don't use SWAG, instead NGINX Proxy Manager. It's GUI based rather than config files. I find it so much easier to use.
So I've got Home Assistant working remotely using NGINX Proxy Manager. It's pretty easy. I have NGINX set up for a few dockers as well as HA VM.
Happy to help you if I can but I'd recommend moving over to NGINX PM 🙂
Hi. Sorry to dig up an old thread.
Do you have nginx running as a docker in unRAID for your HA VM?
I have HA as a vm and having a tough time setting up a reverse proxy w nginx.
Was trying to use the guide
https://www.juanmtech.com/getting-started-with-home-assistant-2021/
He uses mariadb and nginx add-ons w/in ha.
I was never able to open ports 443 and 80 w/my HA IP, but just realized that ha is configured for 8123.
Can you point me in the right direction to get nginx working as a reverse proxy for my ha vm?
-
Just now, JorgeB said:
For now it will help, but when both are full you'll have the same problem.
It shouldn't.
Just now, JorgeB said:Great! Thanks.
Not really a problem for me, more of an inconvenience. Just wanted to make sure i wasn't messing something up by putting my cards in the wrong slot. I knew upgrading would have it's drawbacks.
-
1 minute ago, JorgeB said:
If you have 8 disks on this HBA it will bottleneck, about 50MB/s maximum is the expected speed, you can run the diskspeed docker controller test to check bandwidth.
Thank you. The plan is to use 8 drives on each HBA card. right now, one card is fully utilized and the other one only has one drive plugged in. plan on getting more drives over the next few years.
So changing the pci slot won't do anything, correct? will saturating the other HBA card slow transfer speeds even more in the future?
-
10 minutes ago, Squid said:
The diagnostics show that the parity check was running for less than a minute before you grabbed them. Does it speed up after a while?
it's almost 2 hrs in and still at 55 MB/s
-
So recently upgraded my NAS case from an r5 to a meshify 2 xl. All my components are still the same but added another pci sata/sas expander card.
All the drives are recognized and it's running ok so far, but I'm running a parity check and i'm getting 1/2 the speeds currently running at about 55 MB/sec. At this rate it'll take me 3 days to run a parity check.
I have one sata/sas card in the pcie x1_2 slot, another in the pciex4 slot. i have my gpu in the pciex16 slot.
Have i congested all my lanes? Will this only be an issue during parity checks? would it be quicker if i run it headless w/o the gpu and put one of the sata/sas cards in the pcie x 16 slot?
I've been debating about using my kids amd 5700g in my unraid box and giving them the 2600 + GPU. I primarily use my unraid box as a plex server and the highest bitrate i've seen is misery 4k at 111.54 Mbps, so I think it should be ok for local streaming.
attached a diagnostic just in case.
components
Aorus b450 pro wifi
SSD Samsung Evo 860 x2
Ryzen 5 2600
EVGA 750w supernova g+
Fractal design meshify 2 xl
16 gb of ram
Amd gpu 4800? Or hd 7870 on pic
2x LSI SAS 9207-8i SATA/SAS 6Gb/s PCI-E 3.0 Host Bus Adapter IT Mode SAS9207-8i US
nasgard-diagnostics-20211013-0941.zip
-
On 9/23/2021 at 8:00 PM, trurl said:
Where did you hear that? I think that and not overclocking RAM are the fix for most people.
Server has been up for 1 week wo crashes after disabling c states. Before I couldn't go 1-2 days. Hope that's it. Thank you.
-
having same issue. did you ever find a solution. I reverted to 6.8.3 and was doing well, but then the crashes and kernel panics started up again. can't go more than a day or two w/o a crash.
-
29 minutes ago, trurl said:
Where did you hear that? I think that and not overclocking RAM are the fix for most people.
i guess from this thread:
figured by putting idle power state to typical would make disabling unnecessary, but maybe i misunderstood it.
-
21 minutes ago, trurl said:
I seem to have followed this faq (disable xmp, switched idle control to typical) except for disable c state. I've heard that that isn't desirable however.
Also, I'm running it w and old Radeon 4800 gpu. Could that be the issue? .should I run it headless?
-
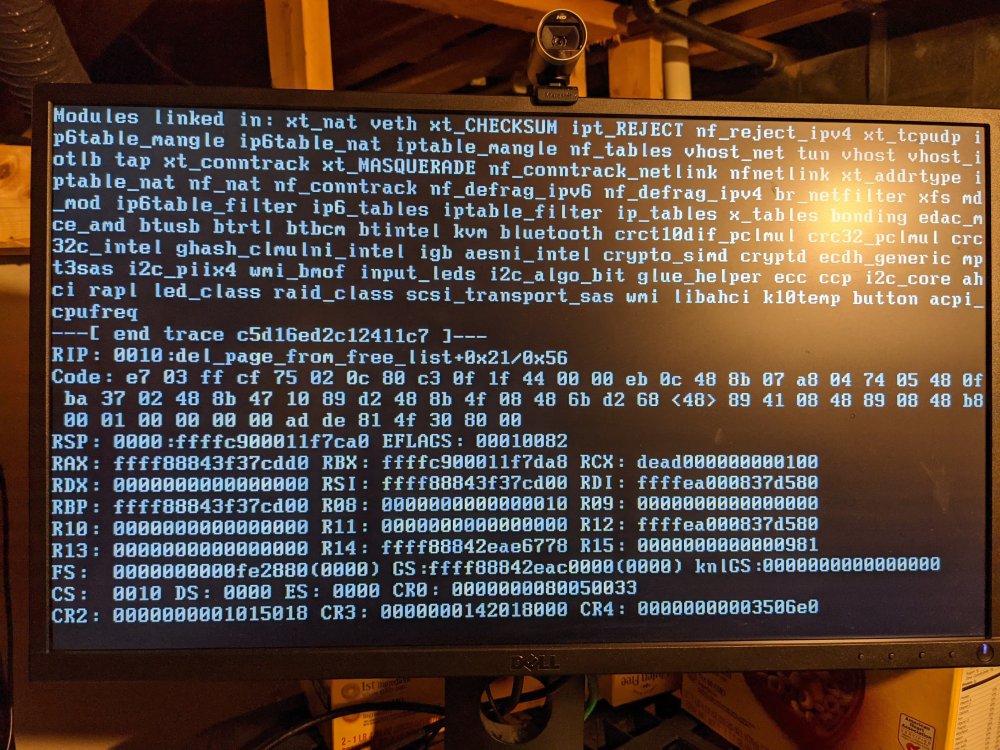
I have a ryzen 5 2600 based unraid server on the latest os.
I've had random crashes and kernel panics several times a week requiring a hard reset.
Attached is my diagnostics as well as the crash screen.
Troubleshooting steps:
1. run memtest for 24 hrs (8 passes or so) w/o any issue
2. disabled xmp profile of memory
3. turned idle power setting from mobo bios from auto to typical
4. I initially thought it was 6.9.2 so i downgraded to 6.8.3 but it would crash as well (not nearly as frequently)
My next step would be to swap out the usb OS drive to see if their is an issue.
I've also heard that moving dockers that had a static ip over to a seperate nic (br2) might help. I also have my discs set to spindown after 45 mins but heard that if you keep it as never, it might help.
I'm really picking at straws here. I'm hoping it's not a ryzen issue.
Any thoughts on where i should go from here?
-
20 minutes ago, JorgeB said:
Diags are after rebooting so not much to see, if it happens again see if you get get the diags on the console, if got get at least the syslog.
will do. thanks.
Should my parity check be correcting? i assume so since it was an unplanned, dirty shutdown. my monthly parity checks are usually non-correcting.
-
On 6/8/2021 at 12:33 PM, dauntouch said:
Is there an issue for this so we can track when its safe to upgrade to 6.9.x?
Would like to know this as well


slow local transfer speeds
in General Support
Posted
I could have sworn i was getting faster writes before. Even if it goes down into the 40's, it's still ok? I'm using WD white label drives in my server. Thought that those could write close to 200 MB/s