

brucejobs
-
Posts
24 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by brucejobs
-
-
My tcp-udp tunnel will not start. Indicating I need to start or update my tunneltonet app. This says I have either;
1. My Post Argument syntax is incorrect - is it?
a) authtoken [djz65e0MERpMYCW1UbimEcfSvTzlSaNAYDs]
b) authtoken djz65e0MERpMYCW1UbimEcfSvTzlSaNAYDs <-- this is what i am using
(not a real authtoken)
2. The tunnel config is incorrect. I am assuming to configure the internal IP (tower ip) and docker Port (plex 32400).
3. A complete misunderstanding and its a combination of all the above.
For clarity I am attempting to have plex working past CGNAT and without port forwarding. I know I could use Tailscale, for *reasons, I am seeking alternatives.
Send help. -
Hey gang,
Recently I migrated my public facing services away from reverse proxy to cloudflare zero trust tunnels. Amazing, highly recommend - you can remove all portforwarding and drop swag or the like.
However, (I take responsibility for this) I failed to pay attention to the auto generated script which clearly states no auto updates...
docker run cloudflare/cloudflared:latest tunnel --no-autoupdate run --token <insert token here>
The docker logs are showing:
WRN Your version 2023.8.2 is outdated. We recommend upgrading it to 2023.10.0
I cannot open a console to the docker and run the (currently unknown update command) to update the docker.
Looking for some advice on how to update without having to rebuild it, with command too please.
If the answer is "just rebuild it", what is the correct syntax to set the replacement docker with auto update; is it "docker run cloudflare/cloudflared:latest tunnel --yes-autoupdate run --token <insert token here>"?
Or, is there a reason we don't auto update the tunnel docker?
Please help, not much documentation around on this that I know how to find.
Sincerely,
PEBKAC #9001 -
On 2/13/2022 at 12:18 AM, Vinster411 said:
I'm having this exact same issue. but for me (and assume everyone) the device allocation is always changing. Sometime the drive is sdc and then on the next reboot it's sdm.
Is there a way to check if the drive has it disabled before enabling it?
I only have this issue on mechanical drives, the ssd/nvme's don't have the issue.
I just don't want to have the script blindly running for devices that don't exist or on ssd/nvme's
Vin
I also had same challenge. Solved it for me, but...
!!! USE AT YOUR OWN RISK !!!
It will check all disks in your system ignoring any USB disk which may happen to be your OS, enabling write-cache. Add to start up scripts as others have mentioned.
#!/bin/bash # The list of devices to check and enable write cache on devices="/dev/sd[a-z]" for device in $devices do echo "Checking device $device" if [ -e $device ]; then is_removable=$(lsblk -d -no RM $device) if [ $is_removable -eq 1 ]; then echo "This is a USB device, possibly the UNRAID OS disk. It is not recommended to enable write cache." continue fi write_cache_status=$(hdparm -W $device | tr '\n' ' ' | awk -F'[()]' '{print $2}') echo "Write cache status: $write_cache_status" if [ "$write_cache_status" == "off" ]; then echo -n "Enabling write cache on $device... " hdparm -W1 $device if [ $? -ne 0 ]; then echo "Failed" else echo "Done" fi else echo "Write cache already enabled on $device" fi else echo "Device $device does not exist" fi echo "" # Add an empty line for formatting done
No responsibility taken for lost data, crashed system etc.
Output if ran manuallyChecking device /dev/sda This is a USB device, possibly the UNRAID OS disk. It is not recommended to enable write cache. Checking device /dev/sdb Write cache status: on Write cache already enabled on /dev/sdb Checking device /dev/sdc Write cache status: on Write cache already enabled on /dev/sdc Checking device /dev/sdd Write cache status: on Write cache already enabled on /dev/sdd Checking device /dev/sde Write cache status: on Write cache already enabled on /dev/sde
-
On 8/24/2022 at 12:08 AM, JonathanM said:
Keep the server plugged in where it is, so it doesn't lose power during the test. Find a way to switch the input power to your new UPS without unplugging it. Switched outlet, power strip, whatever. It's vitally important the ground stays connected the entire time. Plug the USB communication lead into your server, verify it is detected and monitoring properly. Find roughly 300W of load, like a small space heater on low, or something similar. Old school halogen floodlamps are good too. Plug that into the power protected outlet of the UPS, verify the server is showing the load in the UPS monitoring. Turn off the supply to the UPS, and observe the server. Don't intervene, just let it think the power is down. Time how long it waits to start shutting down, and how long the process takes. Verify the dummy load on the UPS has stayed stable, no blinking lights or abnormal heater fan speed variations. When the server powers off, turn off the dummy load. Leave the power turned off to the UPS for a period of time, to simulate prolonged outage. Power up the UPS if it turned off, turn on the dummy load, boot the server. See how the stats look for charge percentage and such.
This is some solid testing to simulate real life advice. thank you.
-
Thanks for the reply Squid. Gave me a lightbulb moment, we confirmed that for an unknown reason the Ports were removed from the docker. We tried versions from binhex and linux but same end result, we downloading the docker the ports were not pre configured. So we manually created new ones based off my install and this has worked. Simple really and cannot believe I missed something so basic.
To answer why Bridge? Bridge, Host, and custom proxynet all produced the same result, which I know understand why and can absolutely slap myself for.
Again, appreciate your time to point out the obvious.
-
Hello,
Apologies for the big post, attempting to include as much info from the get go for those who may be inclined to assist.
I am helping a friend out trying to resolve why his plex docker does not display the port mappings, like so.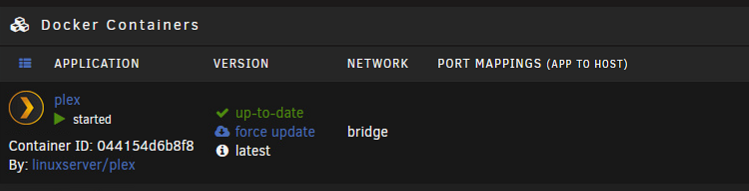
However when running 'docker network inspect bridge' there is an IP assigned.

Sharing the run command.
docker run -d --name='plex' --net='Bridge' -e TZ="Australia/Perth" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Tower" -e HOST_CONTAINERNAME="plex" -e 'VERSION'='docker' -e 'PLEX_CLAIM'='' -e 'PUID'='99' -e 'PGID'='100' -e 'UMASK'='022' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:32400]/web/index.html' -l net.unraid.docker.icon='https://raw.githubusercontent.com/linuxserver/docker-templates/master/linuxserver.io/img/plex-logo.png' -v '/mnt/user/Tv Shows/':'/tv':'rw' -v '/mnt/user/Movies/':'/movies':'rw' -v '/mnt/user/appdata/plex':'/config':'rw' 'linuxserver/plex'
I then attempted adding to a custom network with IP but was greeted with en error: "docker: Error response from daemon: user specified IP address is supported only when connecting to networks with user configured subnets."
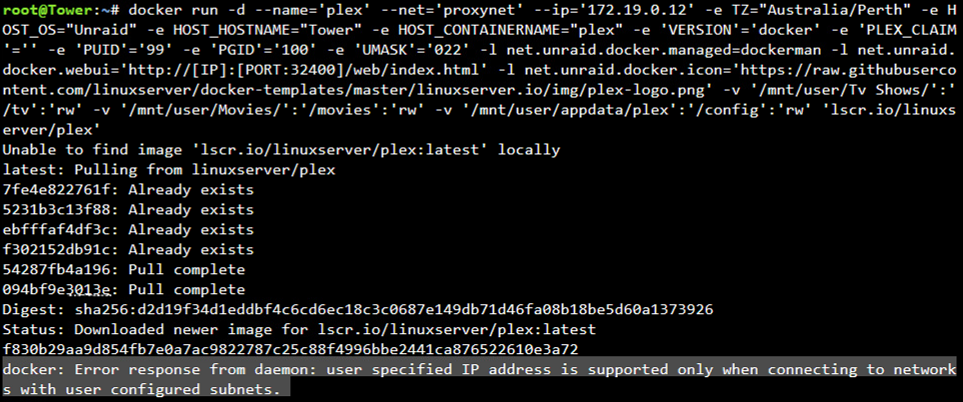
I confirmed the network name and network segments were correct. But that is the stretch of my so called "investigation". Please forgive my lack of knowledge.
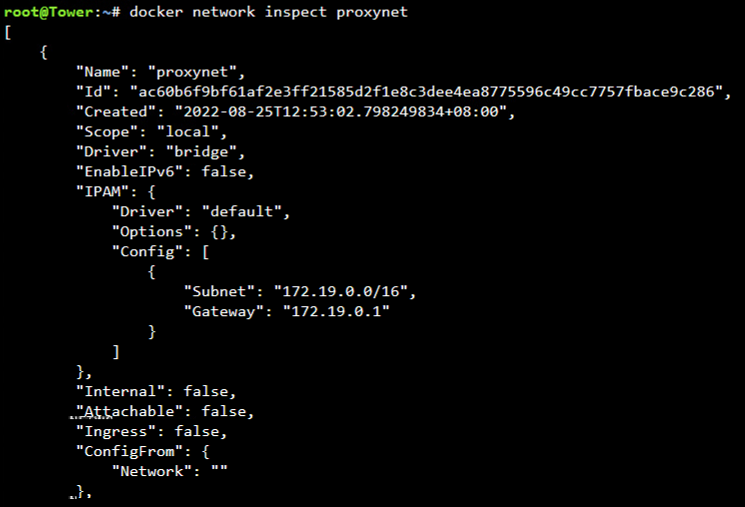
Additional info.
No errors in application log file that is accessible from the GUI.
The Web GUI link to open the docker in a web page does not attempt to open a webpage - like a dead link. The same is true for other networks, Host and Custom. Assigning br0 interface permits a manual IP to be assigned but cannot open the GUI, webpage opens and is dead in water from there.
As a last resort I deleted the docker image file and rebuilt from scratch. No change.
Would appreciate some guidance to investigate. Diagnostics file attached. Thanks for reading this far.
Cheers,
BigJobs -
On 4/6/2021 at 5:42 AM, ljm42 said:
It sounds like you enabled SSL access to the webgui. If you would like to disable that and revert to normal http, go to Settings -> Management Access and set "Use SSL/TLS" to "No".
(From your description it sounds like DNS Rebinding has been enabled on your network since you set this up. You should be able to access the webgui by going to https://[ip address] and ignoring any error messages.)
Thanks for this tip. Mine was set to Auto, I set it to "No" and its now working with local address over http.
Question: How do I unbind? Previously if I tried the local address it would hang then update the address to https://hashnumber.unraid.net
I would like to understand more.
Thanks -
On 3/6/2021 at 10:54 AM, SiRMarlon said:
I am working on trying to figure out the extra parameters for the NGINX cofig file now.
Did you work it out? IF so, please share steps from start to finish. thanks
-
On 4/22/2021 at 3:35 AM, mikeylikesrocks said:
You should be able to go into the prefs.xml file located in your Crushftp9 folder located in your Appdata (if you use the standard locations) share. Open the XML file and the banned ip's should be listed. Below is an example of a banned IP. Look for your ip or the ip of your reverse proxy server and delete that block.
<ip_restrictions_subitem type="properties"> <start_ip>61.75.30.52</start_ip> <type>D</type> <stop_ip>61.75.30.52</stop_ip> <reason>05/29/2019 02:43:48.047:password attempts</reason>
After you have deleted the banned ip you can search for the "never_ban" and add your lan range.
<never_ban>127.0.0.1,10.0.*,172.*</never_ban>
Then save and restart the docker container.
Thank you, worked a treat.
-
CrushFTP9 install guide anyone?
I manage to bring up the console but only via reverse proxy. After logging in and clicking Admin I get this error message.
Your IP is banned, no further requests will be processed from this IP
any tips? -
On 4/7/2021 at 11:18 PM, schuu said:
has anyone got this working with swag? looking for a proxy conf file if possible not sure how to make one myself. cheers
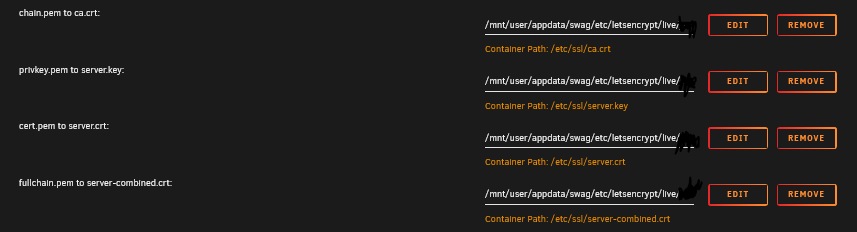
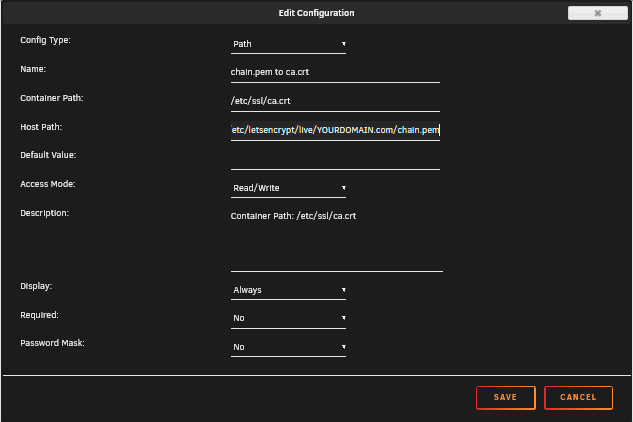
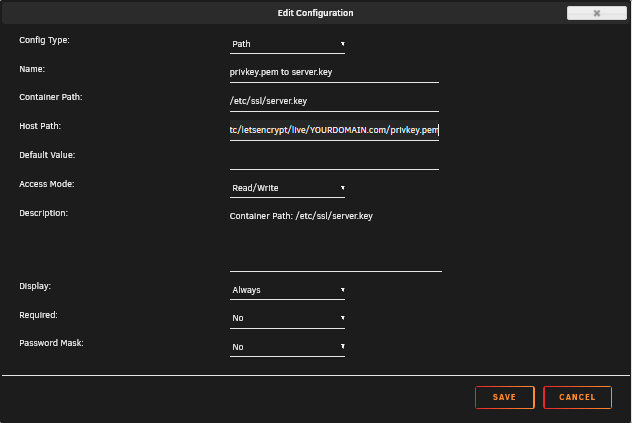
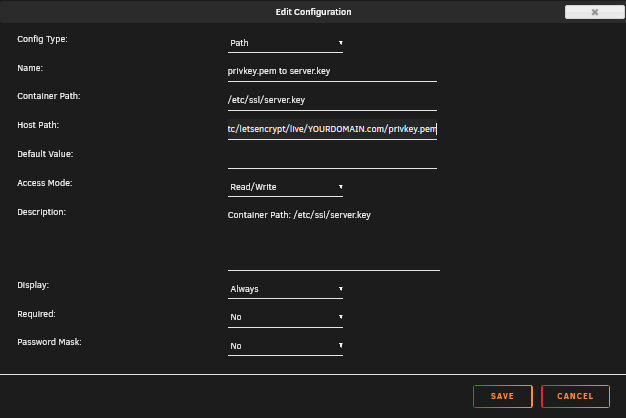
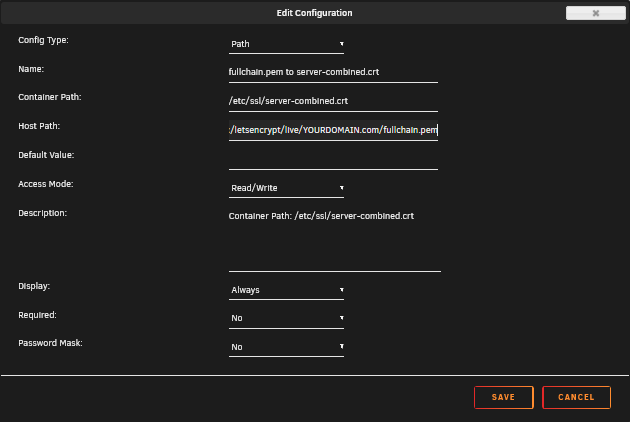
Yes I managed to get this working with swag - made my own proxy conf file. Try the attached conf file. i included screen shots of the config. Turn off HTTPS if using SWAG.
And I added some screen shots of cert mapping, it wasn't abundantly clear in previous posts.
The full string for each. Replace YOURDOMAIN with your actual domain name. Screenshots show you how to configure each.
/mnt/user/appdata/swag/etc/letsencrypt/live/YOURDOMAIN.com/chain.pem
/mnt/user/appdata/swag/etc/letsencrypt/live/YOURDOMAIN.com/privkey.pem
/mnt/user/appdata/swag/etc/letsencrypt/live/YOURDOMAIN.com/privkey.pem
/mnt/user/appdata/swag/etc/letsencrypt/live/YOURDOMAIN.com/fullchain.pem
Let me know how you get on. Good luck.
-
 1
1
-
 1
1
-
-
Found the answer, by accidental discovery. Delete the "server.ini" file in data folder. When you restart it will prompt the "First poste.io configuration" page.
Now, to get reverse proxy working... -
3 hours ago, brucejobs said:
Hello,
I have been able to get to the admin login page. What I failing to comprehend is the login credentials that I must use and how to set about creating those.
I think it may all be in vein because the PTR for my static ip shows my ISP. I have added a PTR on my cloudflared but I dont see that working out. Might have to call my ISP and beg but first, how in the binaries do I get access to my own site. I feel so noob.
Please help.I have attempted to reset the password in the sqlite db using this suggestion "https://tothecloud.dev/reset-poste-io-admin-account/" but getting "no such table" error
# doveadm pw -s SHA512-CRYPT
Enter new password:
Retype new password:
{SHA512-CRYPT}$6$emDaT2RKQD2DgukV$0l5bwcYqsVVenw4fhd3Nrq8QJ/53ImgBtlGcS82UWRkEN.zGeOUu0WaFVtOXOx8dTiHZM1ObL7AA9M/oMDH210
# sqlite3 users.db
SQLite version 3.27.2 2019-02-25 16:06:06
Enter ".help" for usage hints.
sqlite> UPDATE users
...> SET password = '{SHA512-CRYPT}$6$emDaT2RKQD2DgukV$0l5bwcYqsVVenw4fhd3Nrq8QJ/53ImgBtlGcS82UWRkEN.zGeOUu0WaFVtOXOx8dTiHZM1ObL7AA9M/oMDH210'
...> WHERE address = '[email protected]';
Error: no such table: users
sqlite> .exit
This is quickly stepping beyond the realms I normally work in but im happy to learn. Any help? -
On 1/31/2021 at 1:50 AM, aterfax said:
I am not using the letsencrypt docker, I am using swag which is a meaningless distinction since they are the same project with a different name due to copyright issues. You do not really appear to be reading anything linked properly nor understanding anything fully.
I'm not continuing with this dialogue.Fair point, I am surprised you went as far as you did. You were trying to help out and basically were yelled at by a Karen. I followed what was being said and can confirm "/mnt/user/appdata/swag/keys/letsencrypt/" is just a link to to "/mnt/user/appdata/swag/etc/letsencrypt/live/domain.com/".
Thanks for the guide, it helped me understand mapping and best practice from a security perspective. *thumbsup -
Hello,
I have been able to get to the admin login page. What I failing to comprehend is the login credentials that I must use and how to set about creating those.
I think it may all be in vein because the PTR for my static ip shows my ISP. I have added a PTR on my cloudflared but I dont see that working out. Might have to call my ISP and beg but first, how in the binaries do I get access to my own site. I feel so noob.
Please help. -
On 3/18/2021 at 10:09 AM, schuu said:
Did you find a solution for this? I am having the same problem.
The reason is explained at the top on the first page. I tried to quote but I am lacking the understanding how multi-quote works across pages.
-
Thanks for the efforts everyone. I was a bit excited at the prospect but being a noob a linux I even struggle to understand the most basic of things. As such this is beyond me, presently. Such a shame to abandon a mail server, I would L O V E to host my own.
Following thread in hopes some champion with the skill-set can recompile a working unraid app for us plebs. -
22 hours ago, trurl said:
This is obviously lacking in details. My guess is you did something wrong reinstalling your dockers at that point, and reinstalling them with the Previous Apps feature just did it over again like you had previously, so also wrong,
Probably best to start over and try to get a single docker setup correctly and go from there.
Correct and it looks that way.
22 hours ago, trurl said:Is plex working?
Yes.
Thanks all the same, appreciate someone else telling me the bad news. I will try to get my old cache drive, pop it in and see what mess I have. -
Hi,
Have recreated the Docker image. The only difference is now Pi-Hole is broken for some reason. I didn't copy the install error but it basically said the image already existed, could not copy, could not start, try installing separately. But its there?
Anyway I am still seeing these errors
Unable to connect to indexer, check the log for more details
Unknown exception: Unable to read data from the transport connection: The socket has been shut down.
Website is still down.
Latest diagnostic nest-diagnostics-20200914-1608.zip
Now that we have sorted the appdata, domains and system shares... What should I do next?
-
alright managed to sneak away for 10 minutes and work on this.
New diagnostics attached nest-diagnostics-20200913-1921.zip
Hmm, not seen this one before. Went to start my docker and I see a warning.
"Your existing Docker image file needs to be recreated due to an issue from an earlier beta of Unraid 6. Failure to do so may result in your docker image suffering corruption at a later time. Please do this NOW!"
I don't think I used a beta before. -
8 minutes ago, trurl said:
Similar applies to your domains share. Do you actually have any VMs?
Yes i did. But that isn't as important to me right now.
-
Hi turl, thanks for response.
The community application "Fix common problems" warned of something like this for sometime but I was not sure how to fix it. I cannot say for sure but if i were a betting man, i would hedge my bets on it was like this before hand.
Fix forward mentality, how do i fix this now? I have a 240GB cache. Would like to run most things off this. I have plans to add a secondary mirror into my cache, just need more Sata Ports. I did try adding a PCIe card but instead of seeing 240GB it saw 4x 60GB drives - the 4 separate sandforce controllers, not the hypervisior because no drivers and not being smart enough i didnt bother looking for a work around. Card is an OCZ Revo 2. Anyway, forgetting that. Do you have any recommendations for correcting my config for my cache drive? -
Hi,
Unraid (Nvidia) Version: 6.8.3
Docker version: 19.03.5Nvidia driver version: 440.59
Few weeks back i replaced the cache drive following spaceinvader1 guide. needless to say I mucked it up.
I run binhex dockers where possible.
Symptoms include:
log filled to 100 percent, could not shut down equaling an unclean shutdown.
sonarr, radarr. lidarr do not communicate with deluge, error: "Unknown exception: Unable to write data to the transport connection: The socket has been shut down."
sonarr, radarr. lidarr do not communicate with Jackett, error: "Unable to connect to indexer, check the log for more details" (i check log and well, 'duuuuh' <-- Me).
deluge lost all current downloads.
monitorr webUI broken - no biggie.
letsencypt webUI broken and has stopped working because my ombi and plex websites no longer work.
What works is plex and pihole. Lnest-diagnostics-20200912-0626.zipeast I have that going for me.I have tried removing and adding back dockers but still 'le fail.
I imagine that I have broken permissions to something or failed to copy across data. I gave the old drive to a friend who hasn't used it , i think the data is still intact. Will get it back soon. Should I put it back to see if things start working again or can I fix forward? I would still need to replace it.
Diagnostics attached. https://forums.unraid.net/applications/core/interface/file/attachment.php?id=90184
Cheers legends.













Immich docker self-hosted google photos setup
in General Support
Posted
Machine Learning using Nvidia GPU
I have it configured as such but not confident its working as expected. CPU runs at 100% and I am not seeing any activity in GPU monitor. Anyone else have ML working?
Cheers,
brucey