Leaderboard




Popular Content
Showing content with the highest reputation since 03/27/24 in all areas
-
This is a bug fix release, resolving a nice collection of problems reported by the community, details below. All users are encouraged to read the release notes and upgrade. Upgrade steps for this release As always, prior to upgrading, create a backup of your USB flash device: "Main/Flash/Flash Device Settings" - click "Flash Backup". Update all of your plugins. This is critical for the Connect, NVIDIA and Realtek plugins in particular. If the system is currently running 6.12.0 - 6.12.6, we're going to suggest that you stop the array at this point. If it gets stuck on "Retry unmounting shares", open a web terminal and type: umount /var/lib/docker The array should now stop successfully If you have Unraid 6.12.8 or Unraid Connect installed: Open the dropdown in the top-right of the Unraid webgui and click Check for Update. More details in this blog post If you are on an earlier version: Go to Tools -> Update OS and switch to the "Stable" branch if needed. If the update doesn't show, click "Check for Updates" Wait for the update to download and install If you have any plugins that install 3rd party drivers (NVIDIA, Realtek, etc), wait for the notification that the new version of the driver has been downloaded. Reboot This thread is perfect for quick questions or comments, but if you suspect there will be back and forth for your specific issue, please start a new topic. Be sure to include your diagnostics.zip.8 points
-
Es gibt ein Problem mit 6.12.9 unter ganz bestimmten Umständen. Wer diese Konfiguration betreibt sollte 6.12.9 noch nicht installieren. Es geht um CIFS/SMB Remote Mounts die mit Unassigned Devices in Unraid angelegt werden (/mnt/remotes/xxx). Das heißt Unraid ist der Klient einer CIFS/SMB Verbindung. Die Funktion von Unraid als Server einer CIFS/SMB Verbindung ist nach derzeitigem Erkenntnisstand davon nicht betroffen. Es gibt zwei aktuelle Bug Reports, einer ist von mir: Weiterhin gibt es von @dlandon einen Hinweis wohin das Problem zeigt (Kernel/SAMBA): Erkennen könnt Ihr das Problem eindeutig an den CIFS VFS Fehlern in der syslog. Wenn diese auftauchen, dann seht Ihr oder Eure Software nur einen Teil der existierenden Ordner oder Dateien. Das kann erhebliche Probleme nach sich ziehen. Wer 6.12.9 über 6.12.8 bereits installiert hat, und diese Konfiguration betreibt bzw. den Fehler bekommt --> ein Downgrade auf 6.12.8 ist jederzeit problemlos möglich:
 7 points
7 points -
This release reverts to an earlier version of the Linux kernel to resolve two issues being reported in 6.12.9. It also includes a 'curl' security update and corner case bug fix. All users are encouraged to read the release notes and upgrade. Upgrade steps for this release As always, prior to upgrading, create a backup of your USB flash device: "Main/Flash/Flash Device Settings" - click "Flash Backup". Update all of your plugins. This is critical for the Connect, NVIDIA and Realtek plugins in particular. If the system is currently running 6.12.0 - 6.12.6, we're going to suggest that you stop the array at this point. If it gets stuck on "Retry unmounting shares", open a web terminal and type: umount /var/lib/docker The array should now stop successfully If you have Unraid 6.12.8 or Unraid Connect installed: Open the dropdown in the top-right of the Unraid webgui and click Check for Update. More details in this blog post If you are on an earlier version: Go to Tools -> Update OS and switch to the "Stable" branch if needed. If the update doesn't show, click "Check for Updates" Wait for the update to download and install If you have any plugins that install 3rd party drivers (NVIDIA, Realtek, etc), wait for the notification that the new version of the driver has been downloaded. Reboot This thread is perfect for quick questions or comments, but if you suspect there will be back and forth for your specific issue, please start a new topic. Be sure to include your diagnostics.zip.6 points
-
Devs have said that 6.13 public testing should be ready to start soon (likely within another week or two unless a major bug is found), that will be the first version to bump to the newer kernel with inbuilt ARC support. Likely be in testing for quite a while as it is going to be a big kernel version jump, and this little patch update shows us that kernel upgrades can have all sorts of weird minor edge cases across the mess of mixed hardware people use.6 points
-
I think it's two fold. One, there is a group of individuals that do this for a living and want to play around it to learn it for their job, or as a way to see if it's something they should deploy at their workplace. Secondly, I think others do it because of the "cool" factor. Don't get me wrong, I still think it's a mighty fine solution (I've played around with it myself), but it takes a lot more configuration/know-how to get it working. Like you said, it doesn't have docker by default, so you either have to create a VM and/or LXC, install docker and go from there. Personally I've played around with Jellyfin on Proxmox...I did it in a VM, I did it with docker in a VM, as well as an LXC and while it was fun, it wasn't no where near as simple as Unraid, where it's click install, change a few parameters and go. I also see a lot of discussion around the "free" options out there. No offence, but these "free" options aren't new. They've been around just as long, if not longer than Unraid and guess what, people still chose Unraid. Why?, because it fits it target market...."home users." Easy to upgrade storage, similar easy to follow implementations for VMs and docker, a helpful/friendly community, plenty of good resources to help you along (ie: Spaceinvader One),etc... There's more to Unraid then just the software and it's why people chose Unraid over the others. People will pay for convenience, it's not always about getting stuff for free. Does Unraid have every feature that the other solutions have...no, but it doesn't need to and IMHO most of them don't really matter in a home environment anyways. Furthermore, there seems to be a lot of entitled individuals. I feel bad for software developers, because people want their stuff, they want them to make changes, add new features, etc... and oh btw, please do it for free, or charge someone else for it, thank you... I've seen a lot of arm chair business people here offering suggestions to just do what the others do; go make a business version, go sell hardware, etc... No offence, but those things sound way simpler than what it actually takes. Not to mention there's no guarantee that it will pay off in the long run and has the potential to put you in a worse situation compared to where you were before. For example, lets say they do offer a business solution and price it accordingly. Since they (business/enterprise customers) will essentially be the one's funding Unraid's development in this case, they will be the ones driving the decisions when it comes to new features, support, etc....it won't be us home users using it for free. I want Lime Tech to focus on Unraid. I don't want them to focus of other avenues that can potentially make things worse in the long run because they have too much going on. Just focus on what they do best and that's Unraid. We can go back an forth all day long. At the end of the day, if you are that unhappy then please just move on (not you MrCrispy, just speaking generally hehe). While I can understand the reasoning behind the dissatisfaction, but to be honest, none of the naysayers have given Lime Tech a chance to prove themselves with this change. Sure we can talk about what "other" companies have done in the past, but in all honesty I don't care about "other" companies, all I care about is what Lime Tech does. Just because others have done terrible things, that doesn't mean every company will. It's ok to be skeptical, but you can be open minded as well. Give them a chance, don't just wish for them to shutdown and close up shop. I mean they've already listened and are offering a solution to those who want security updates/fixes for a period of time after the fact. Furthermore they've also upped the starter from 4 to 6 devices, so they are listening....yet people are still unhappy. Which leads me to believe there will be a group of entitled individuals who will never be happy no matter what they do.6 points
-
Schalte einfach den Rechner aus ... dann bist du bei 0 W in Summe. Jetzt mal ernsthaft, das kann man ja nicht mehr ernst nehmen, sorry ... ich hoffe mal du misst zumindest mit einem sehr genauen Messgerät und lässt die Rechner auch mal 24 Stunden laufen um halbwegs vernünftige Ergebnisse zu bekommen ... Wobei so ein Messgerät wahrscheinlich 20 Jahre Plex Idle Stromkostenverbrauch bereits konsolidieren ... Strom sparen in allen Ehren und ja, wer den "Cent nicht ehrt .. ist des Talers nicht wert ..." aber hey ... verschwende nicht deine und anderer Lebenszeit mit solchen Anfragen.5 points
-
Unraid plugin that enables you to adjust your Unraid system's power profile to enhance performance or improve energy efficiency. Additionally, it fine-tunes the TCP stack settings and network interface card (NIC) interrupt affinities to optimize network performance. Please note: This plugin is not compatible with other plugins that alter the same settings.5 points
-
I must say that the new update box, getting the updates notes and known issues before updating (or needing to check them here) is an nice touch!5 points
-
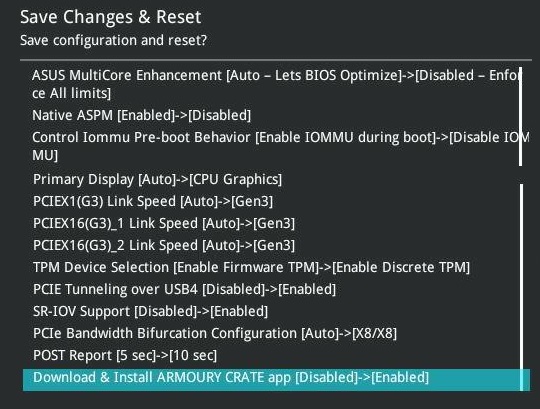
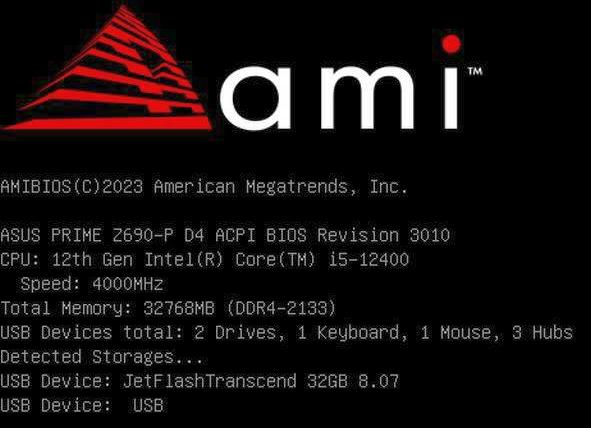
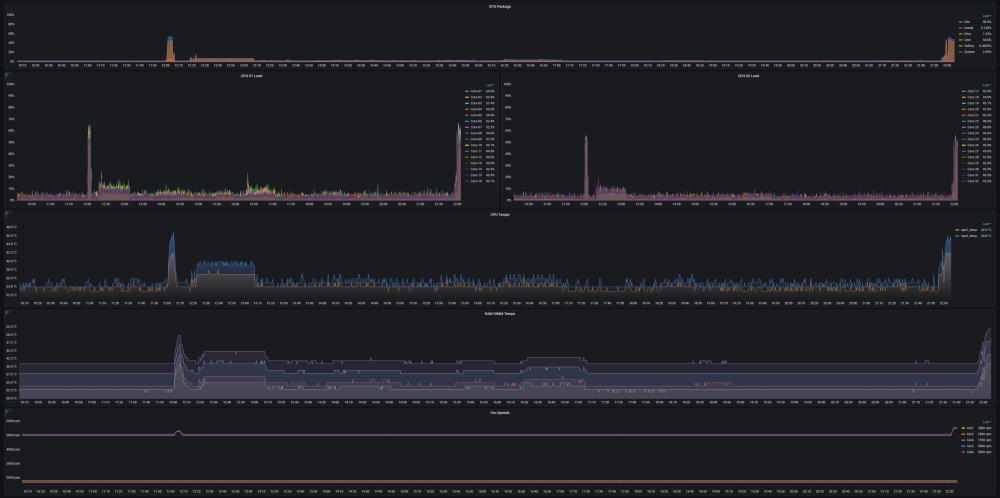
Und es geht wieder los: DataCollector mißt mal wieder Mist 😄 Im Rahmen meiner Messungen des Gigabyte B760M DS3H DDR4 kam des öfteren die Frage nach den Z690 Mainboards auf, weil es diese auch mit 8x SATA gibt. Okay, ein Z690 mit 8x SATA habe ich nicht, deshalb muß nun mein ASUS Prime Z690-P D4-CSM (90MB18P0-M0EAYC) dafür herhalten. Auch hier als Vorbemerkung: ich habe dieses Mainboard NICHT für unraid erworben und deshalb enthält es Komponenten, die den Stromverbrauch wohl etwas erhöhen könnten (wenn man sie nicht abschaltet). Aber da ich es nun einmal hier habe und gerade wach bin nehme ich das mal für eine Messung. Aktuell geht es erst einmal um den Stromverbrauch/C-States des Boards idle/in Minimalbestückung. Hardware und Beschaltung: - ASUS Prime Z690-P D4-CSM (90MB18P0-M0EAYC) (BIOS/UEFI: 2023-12-28 v3010) (BIOS auf Default und dann die unten im Bild 1 erkennbaren Abweichungen eingestellt). Ich habe versucht alles an zusätzlichen Geraffel, welches für unraid eigentlich nicht benötigt wird, zu deaktivieren. Da das Mainboard auf CSM getrimmt ist, hatte ich Probleme den unraid USB Stick (welcher von mir auf UEFI ausgelegt ist) zu starten. Ich wollte ihn aber so wenig wie möglich ändern (ich weiß, daß ich nur das EFI Verzeichnis umbenennen müßte) und das Mainboard hatte ich sowieso mit dem Hintergedanken an Legacy Zusatzkontroller unter Windows ausgewählt und stehe nun einmal d'rauf, daß die Zusatzkontroller schon beim Booten ihren Status auf den Bildschirm anzeigen können. Das hilft bei einer Fehlerdiagnose. Bei UEFI wird das meist unterdrückt. Und nur so nebenbei: Das Mainboard ist sehr pingelig, was Bootsticks angeht. Ich habe fast 1 Stunde gebraucht unraid da überhaupt booten zu können, da viele Optionen, wie da Abschalten von SecureBoot ausgeblendet/gar nicht möglich sind. Und das war auf nur eine einmalige Sache. Danach weigert sich das Board immer wieder den Stick zu booten. Hab sogar das BIOS auf V3205 von März2024 aktualisiert. Ich bekomme den Stick dort nicht erneut gebootet. !! (Man beachte: ich habe aus Stromspargründen im BIOS die CPU und PCH Geschwindigkeit auf PCIE 3.0 reduziert! Somit laufen auch die ggf. später eingesteckten Komponenten (auch NVME SSDs) mit PCIE 3.0) !! - Intel i5-12400 boxed (incl. Intel boxed CPU Kühler) - 2x 16GB DDR4-3200 Mushkin Essentials (MES4U320NF16) - kein SATA - interne Netzwerkkarte (Realtek RTL8125) 1GBLan Link aktiv - PCIe 5.0 x16: leer - PCIe 4.0 x16 (x4): leer - 1. PCIe 3.0 x16 (x4): leer - 2. PCIe 3.0 x16 (x4): leer - PCIe 3.0 x1: leer - M.2 NVME Slot neben CPU: leer - M.2 NVME Slot mitte: leer - M.2 NVME Slot am Boardrand: leer - M.2 Key-E: leer - Leicke ULL 156W Netzteil 12V 13A 5,5 * 2,5mm - Inter-Tech Mini-ITX PSU 160W, Wandlerplatine (88882188) 12V Input - USB Bootstick: Transcend Jetflash 600 32GB - USB 2.0 Y-Steckadapter Delock 41824: USB_SanDisk_3.2 Gen1 32GB als einzige Disk im Array (weil sich unraid sowieso ja nur mit Array vollständig nutzen läßt). Array mit Autostart, damit es immer gleich ist und ich nach einem Reboot für die Tests nicht erst ins WebGUI zum Starten gehen muß. Unraid hat alle Systemshares automatisch auf die USB Stick gelegt (weil ich ja keinen Pool/Cache-SSD eingebunden habe) und damit den USB Stick schon mit 28GB von den vorhandenen nominal 32GB belegt. Software: unraid 6.12.4 stable (weil ich keine Lust habe mich nur für diese Tests mit manuellen ASPM Einstellungen rumzuschlagen. Ich weiss da immer noch nicht so ganz, was ich da wirklich tue und will nicht durch Hardwareveränderungen wieder die passenden 'setpci' parameter rausfummeln.) Community App nerdtools + powertop-2.15-x86_64-1.txz Dynamix Cache Dirs Dynamix File Manager Dynamix System Temperature Unassigned Devices Unassigned Devices Plus Unassigned Devices Preclear im Go File: powertop --auto-tune alle tunables stehen auf "Good" WebGUI und Terminal geschlossen, idle, der Bildschirmschoner hat den angeschlossenen HDMI Ausgang schwarz geschaltet (das spart hier noch mal rund 1W, deshalb warte ich mindestens diesen 'Bildschirmschoner' ab). Messungen wieder mit AVM DECT200 Funksteckdose. Messung 1: nur die nackte (oben genannte) Konfiguration - knapp unter 10W (Siehe Bild 3) und die C-States gehen auch weitgehend auf bis zu 10 runter. Und auch hier wieder der Hinweis: diese nackte Messung dient nur der Vergleichbarkeit. Sobald da irgendein PCIe Device reingesteckt wird oder ein SATA Device mit seiner Firmware auf den SATA Kontroller einhämmert (also ein brauchbarer PC zusammengebaut wird) können diese Werte hoch gehen! Bild 1: BIOS Änderungen gegenüber "Optimized": Bild 2: Bootscreen Bild 3: Messungen ile und nackt:
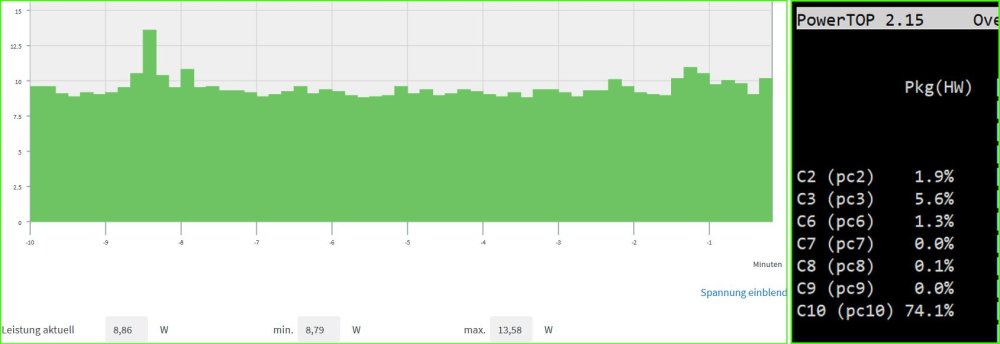 4 points
4 points -
After another 1.5hrs of searching I finally managed to stumble across some more info, from user "frr" on superuser https://superuser.com/questions/570110/how-to-make-the-linux-framebuffer-console-narrower It really is as simple as adding video=<hres>x<vres>@<refresh> to the sysconfig! e.g. video=1600x1000@60 Leaving this hoping to help someone else in future as this took me forever! Unraid version 6.12.9.
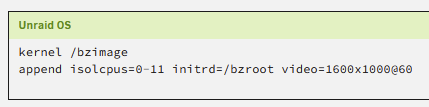 4 points
4 points -
Every plugin, no exceptions, are checked for security issues. This doesn't mean that there isn't going to be security flaws caused by libraries utilized, but you do know that any random plugin is not going to go ahead and outright delete your media etc. Every single plugin available via Apps gets installed on my production server, with no exceptions, and a code audit is done on what is actually present instead of what may be showing on GitHub. Every single update to every plugin I am notified about (within 2 hours), and with plugins which are not maintained by a contractor of Limetech is then code audited again. Every update. And with only a few exceptions, this happens on an actual production server not on a test server. If something ever fails the checks, then everything else gets dropped (including the 9-5 job) to handle the issue. Whether that means simply getting the application out of apps temporarily and asking the maintainer / author "WTF? You can't do this", or notifying everyone with it installed via FCP about any issue, or preventing the Auto Update plugin from installing any update to the plugin, or even taken more drastic measures, provisions are in place to protect the user.. Closed source applications, whether they are plugins or containers, may be frowned upon, but are not necessarily disallowed. With plugins, the standard for open-source vs closed-source is more strict, but it is not 100% a requirement that only open source be present.4 points
-
IMPORTANT NOTICE if you're receiving the following error for the controlr plugin please uninstall the plugin / then reinstall i had to change the location of the plg file and it causes this issue
 4 points
4 points -
This vulnerability is only "triggered" when connecting to an ssh server running on a system with the vulnerable lib. Most containers do not have an ssh server, and only in extremely rare cases you would know about (e.g. a git server container) would that ssh server actually be exposed for someone to connect to. So no.4 points
-
Agree with what I've been doing for the last 5 years or not. I'm good with everyone's opinion and can understand both sides of the argument. But, know that like everything else in CA, these things get tested to death to ensure that they are completely harmless, and functionality isn't impeded, and watch like a hawk every posting to ensure that nothing has gone awry. CA is a passion project. Last year's tribute to the bat if you chose to continue with the homage didn't affect anything (unless you were unable to do a handstand). This year, even if you didn't "revert" to the author dictated images upon installations the author's images would appear in the docker tab, and in all cases it's a simple one click to restore that's clearly communicated. My personal opinion regarding this stuff is that it shows that I actually do care about CA, it's security, and this community. I'm not the type of person (probably few are) who could survive long in a coding factory fashioned after a sweatshop. (Pretty sure that no one else in a space invader one interview inadvertently dropped a dick joke that made it through the sensors) But, everyone did miss the biggest joke of all. While every app had a randomly selected photo (changed every 2 hours), right on the home page (Spotlight section), the "unbalanced" app had a specific picture pinned to it for the duration of the day. While Tom et al did give a go ahead for this, any and all blame / anger / misgivings should get thrown my way. I am glad however that my original idea / planning for this year I did ultimately decide against. It was going to leverage a coding change which is being put into place for a different legitimate reason, but after looking at how the end result turned out I figured it would completely mess everyone up. Either way, as far as I'm concerned, debate about yesterday's event should now be over. What's done is done and let's all get back to business.4 points
-
Life is too short to not have some kind of sense of humor. I approved this little "prank" so come one, let me have it!4 points
-
I know it's April 1, but please, PLEASE, in the future restrain yourselves from trying to come up with a funny hack for MY SERVER SOFTWARE. Write a funny blog post. Make a crazy product announcement. Whatever. But never, EVER, mess with the CRITICAL software that we depend on. Would you enjoy waking up to find that your all your phone's contacts were renamed, "just for fun"? Or all your Windows icons? Well, just imagine my joy late last night when I got the monthly "these things should be updated" email from my server, logged in, and saw RANDOM FACES instead of app icons. Was there a hack on the Docker servers? On Unraid? What the heck was happening? Oh, yeah, sit there and chuckle at your great cleverness. Or don't. This isn't a toy, this isn't some unimportant little side-app. This is server software, and it should be immune to these kinds of too-clever-by-half "pranks". Find another way to prove to the world you have whimsy.4 points
-
Reposting here from my original in General Support: I know it's April 1, but please, PLEASE, in the future restrain yourselves from trying to come up with a funny hack for MY SERVER SOFTWARE. Write a funny blog post. Make a crazy product announcement. Whatever. But never, EVER, mess with the CRITICAL software that we depend on. Would you enjoy waking up to find that your all your phone's contacts were renamed, "just for fun"? Or all your Windows icons? Well, just imagine my joy late last night when I got the monthly "these things should be updated" email from my server, logged in, and saw RANDOM FACES instead of app icons. Was there a hack on the Docker servers? On Unraid? What the heck was happening? Oh, yeah, sit there and chuckle at your great cleverness. Or don't. This isn't a toy, this isn't some unimportant little side-app. This is server software, and it should be immune to these kinds of too-clever-by-half "pranks". Find another way to prove to the world you have whimsy. ---- One of the things that REALLY bothers me about this is that they added NEW CODE to make this happen. At some point, somewhere, code was added to the system that enabled this. It looks like it was in the Community Apps plugin, but still that's code that is running on our UnRaid instances. As a professional software developer (yeah, appeal to authority, I know), this is deeply disturbing. This was essentially a "hidden feature" that nobody knew was being installed on our servers. Adding "joke" code is a bad idea in general. Adding it to a server can lead to potential security vulnerabilities. Pretty much ANY new code can lead to vulnerabilities through unintended consequences, so adding something like this rubs me the wrong way on so many levels.4 points
-
just a quick script you can run in your terminal to output containerIds and corresponding xz version. anything below 5.6.0 should be fine: for containerId in $(docker ps -q); do echo $containerId && docker exec -it $containerId sh -c 'xz --version'; done4 points
-
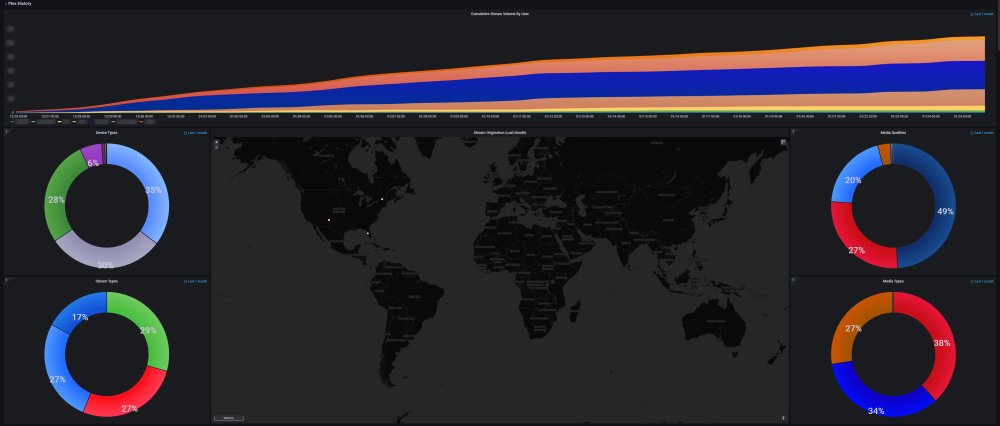
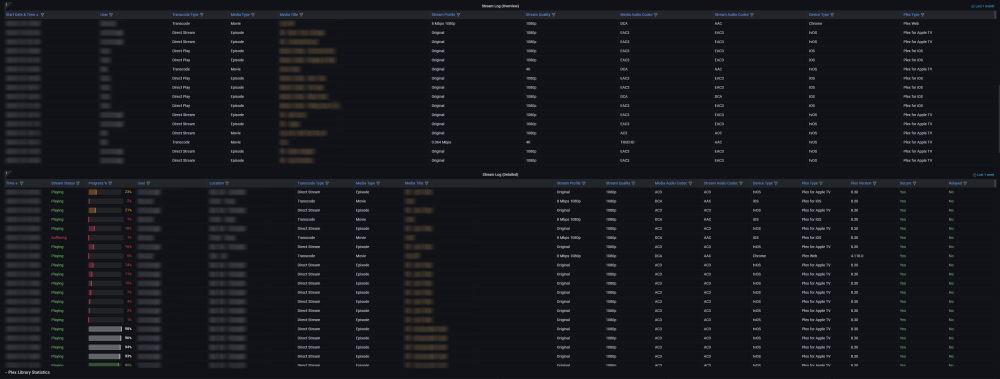
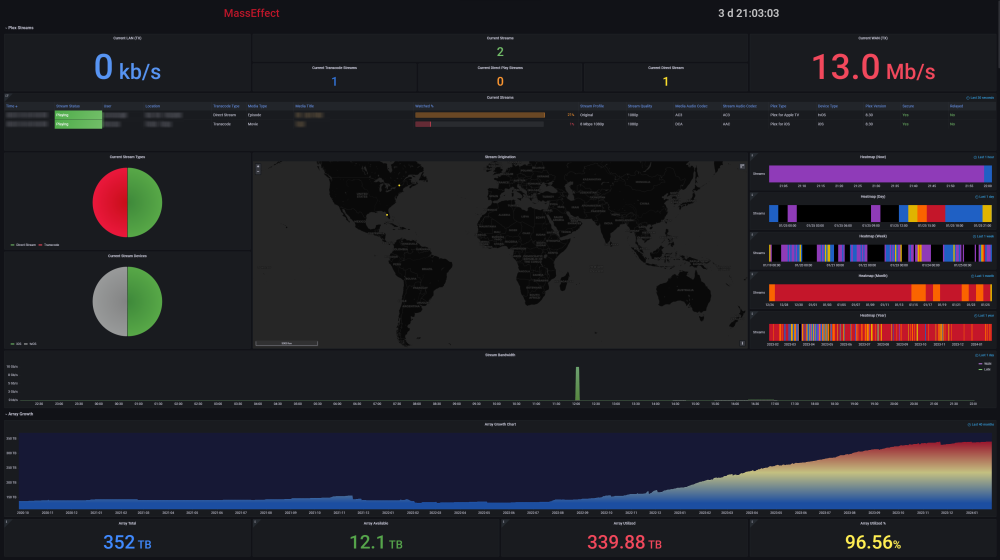
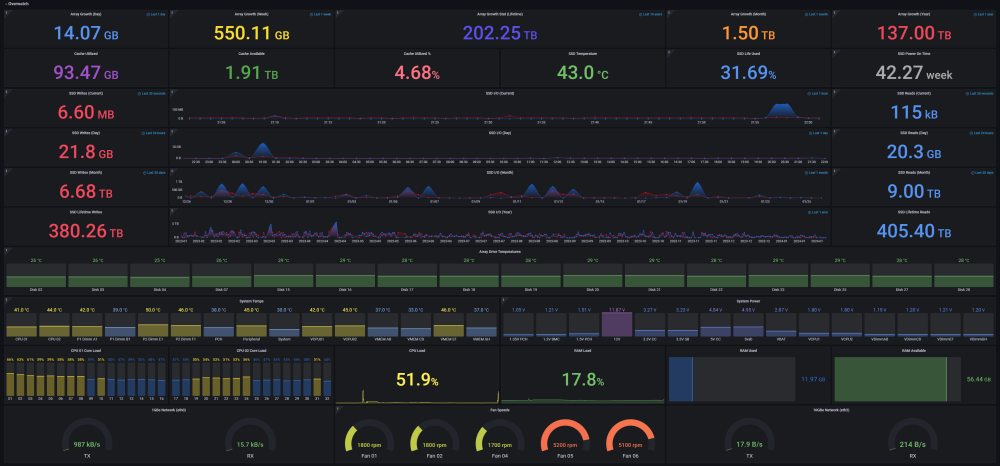
DEVELOPER UPDATE - OFFICIAL RELEASE - Ultimate UNRAID Dashboard 1.7 Today is the release of the Ultimate UNRAID Dashboard version 1.7! Much has changed since the last official release of UUD 1.6. Various plugins and dependencies have been abandoned/deprecated, multiple unRAID OS updates have occurred, and my personal needs for the UUD have evolved over time. Nevertheless, I am very excited to share the new features, use cases, and updated design/architecture of this latest release with all of you. I feel it is the most refined and fine-tuned version yet, and I use it every single day. It is simply a pure joy to have in my life and I really love having all of this information at my fingertips. Please learn from this latest release and use it as a launch pad to create YOUR own Ultimate Dashboard. Without further delay, I bring to you the UUD 1.7! Screenshots (Click for Hi-Res): Deprecated: unRAID API The unRAID API was abandoned/deprecated by its developer after the release of UUD 1.6 It also contained a perpetual memory leak that was never patched All unRAID API panels have been removed from UUD 1.7 If another alternative is developed in the future, I will consider adding it to a future version of the UUD Variable for Future API Data Source Remains I also left this in for people who still wish to use the unRAID API (understanding the known risks) New Dependencies: None New Features: Plex Streams All Real-Time Plex Panels Have Been Moved to the Top of the UUD Provides a Overall Snapshot of Server/Media Use New/Reworked Panels Current LAN (Home Network) Numeric Transmit (TX) Bandwidth Current WAN (Internet) Numeric Transmit (TX) Bandwidth Current Transcode Streams Current Direct Play Streams Current Direct Streams Current Streams Provides a Detailed Real-Time Log of All Current Streams (Last 30 Seconds) Current Stream Types Current Stream Devices Historical Stream Heatmap Now (Last 1 Hour) Current Day (Last 24 Hours) Last Week (Last 7 Days) Last Month (Last 30 Days) Last Year (Last 365 Days) Current Stream Origination Detailed Stream Origination Map View via Geolocation by IP Address Stream Bandwidth Current WAN (Internet) / LAN (Home Network) Transmit (TX) Numeric Bandwidth Array Growth Array Growth Chart Detailed Heatmap Graph of Array Growth Over Time (Timeline Adjustable)\ Array Total Array Available Array Utilized Array Utilized % Overwatch "Cache Central" Completely redesigned array and cache overview section with net new panels with an increased focus on cache health, including real-time/historical disk statistics. Array Growth Day (Last 24 Hours) Array Growth Week (Last 7 Days) Array Growth Month (Last 30 Days) Array Growth Year (Last 365 Days) Array Growth Lifetime (Last X Number of Years - Adjustable) Cache Utilized Cache Available Cache Utilized % SSD Temperature SSD Life Used (Total) SSD Power On Time SSD Writes Current (Last 30 Seconds) SSD Writes Day (Last 24 Hours) SSD Writes Month (Last 30 Days) SSD Writes Lifetime (Total) SSD Reads Current (Last 30 Seconds) SSD Reads Day (Last 24 Hours) SSD Reads Month (Last 30 Days) SSD Reads Lifetime (Total) SSD I/O Current (Last Hour of Reads/Writes to Cache) SSD I/O Day (Last Day of Reads/Writes to Cache) SSD I/O Month (Last Month of Reads/Writes to Cache) SSD I/O Year (Last Year of Reads/Writes to Cache) Plex History Moved Plex Historical History to Its Own Section New Panel: Cumulative Stream Volume by User Graph Showing Cumulative Stream Volume (Last Month) Stacked by User (Timeline & Number of Users Adjustable) Device Types Historical Pie Chart of Stream Devices with Hover Over Key (Last 1 Month) Stream Types Historical Pie Chart of Stream Types (Direct Stream, Transcode, etc..) With Hover Over Key (Last 1 Month) Media Qualities Historical Pie Chart of Media Qualities (4K, 1080P, etc..) With Hover Over Key (Last 1 Month) Media Types Historical Pie Chart of Media Types (Movies, Shows, etc..) With Hover Over Key (Last 1 Month) Detailed Historical Stream Origination Map View via Geolocation by IP Address (Last 30 Days - Timeline Adjustable) Plex Stream Logs Standalone Panels Showing Detailed Plex Stream Logs Stream Log (Overview) Depicts an abbreviated log of all streams based on stream start times over the last 1 month Provides a Quick and Dirty List of What is Being Streamed By User Over Time Stream Log (Detailed) Depicts a full detailed log of all streams sorted by time over the last 1 week (Timeline Adjustable) Provides and in-depth look of all stream activity every 1 minute Can be used to track server issues/buffering/paused streams/abuse Historical UUD Panels All other historical panels (except for API) remain and have been improved/modified as needed for Grafana updates and bug-fixes Notes: unRAID OS UUD 1.7 was developed and tested on unRAID 6.11.4 It should be compatible with 6.12.X Please let me know if you run into any issues in this area Varken Even though Varken is no longer in development by its developer (from what I last heard), I am still using the latest Varken release for the UUD. I have seen zero issues with it and it is stable. Unless this becomes unavailable as a docker from Community Apps, it will remain along with all of the Plex functionality via Tautulli. Please refer to the first few posts in this thread to download, installation instructions and release note history. Direct Downland Link: Ultimate UNRAID Dashboard 1.7 Download (JSON) Install Instructions Are In Post #1 of This Thread: There are a few people out there who have made great documentation and videos on how to install the UUD if you need a detailed tutorial (for those that are new). These are not official, but may help you. A quick web search of "UUD" or "Ultimate UNRAID Dashboard" should give you what you need. Example Install Instructions (Not Official): Video Tutorial Playlist (4 Video Playlist) Based on UUD 1.5 Text Instructions Based on UUD 1.5 https://liltrublmakr.github.io/Ultimate-UNRAID-Dashboard/1.5.0/install15/ Someone Else's Alternate Docker Compose (Not Required) Method (Not Official): https://github.com/goodmase/Ultimate-Unraid-Dashboard-Guid Reddit Discussion (One of Several): I hope you all enjoy! ~ Thanks, falconexe (Community Developer) @SpencerJ
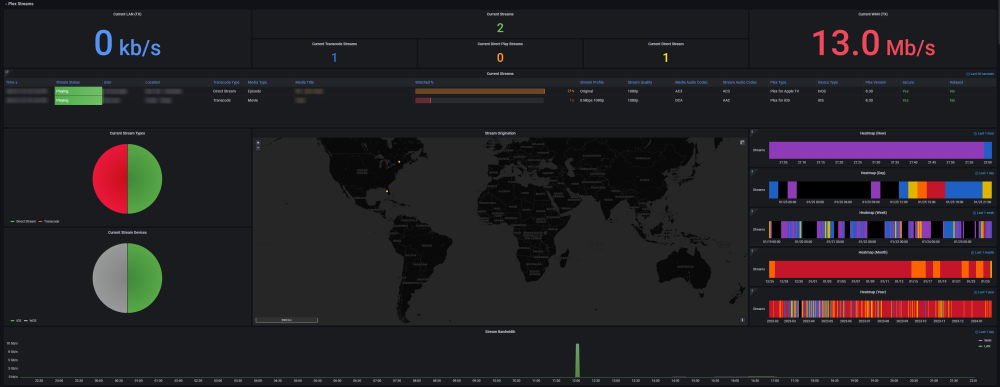

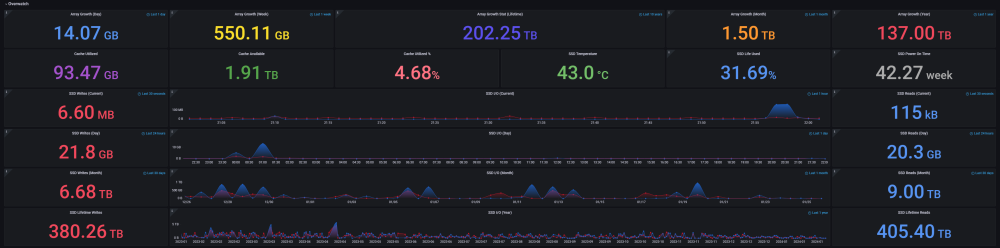
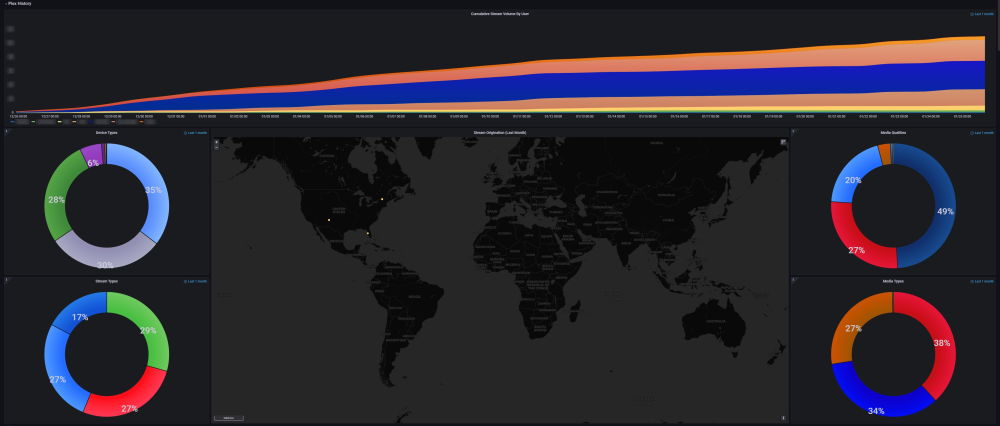
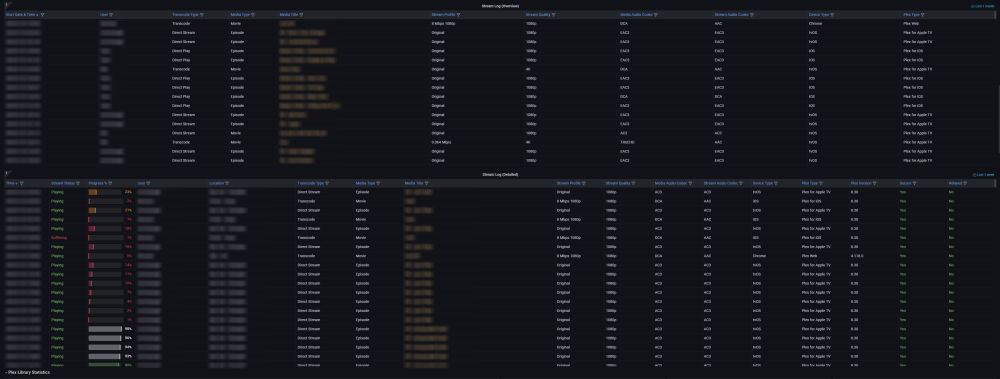
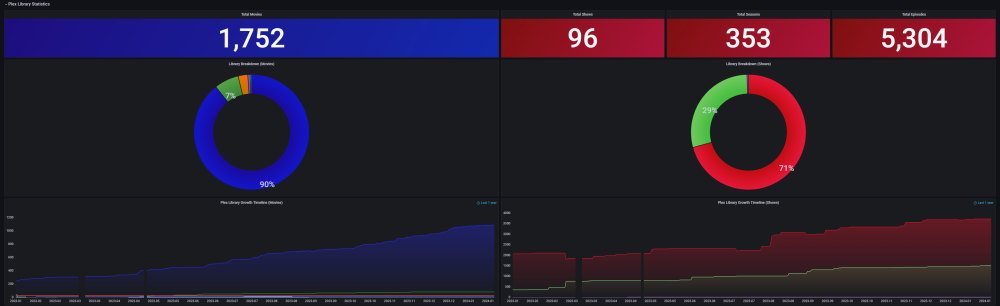
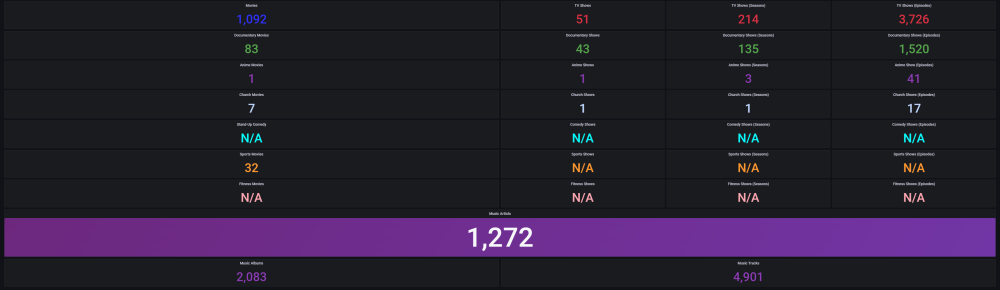

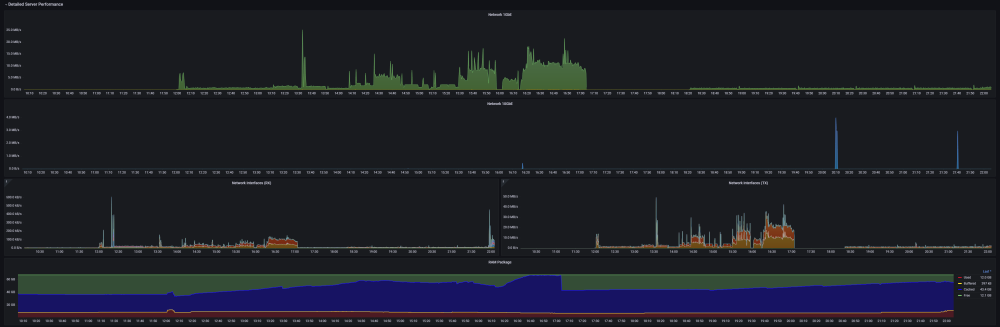
 4 points
4 points -
Some of the image i have built MAY have the affected versions installed, i am currently running a build of the base image to perform the 'Resolution' (see link) and i will then kick off builds of subsequent images. For reference here is the ASA for Arch Linux (base os), pay attention to the 'Impact', also keep in mind unless there is code calling xz then xz will not be running and therefore the risk is reduced, however i am keen to get all images updated:- https://security.archlinux.org/ASA-202403-1 EDIT - Further investigation into the way xz interacts with the system, it looks like in order for the exploit to be used you would need to have systemd operational (not the case with any of my images) and OpenSSH installed (not the case with any of my images), so in my opinion the risk is low here, but as I mentioned above I am keen to get all images updated, so please be patient as this can take a while and its Easter time so my time is restricted.4 points
-
There wont be one, at least not one with dates on it and as someone else said ether in this thread or another just recently, with good reason. If there was a time-frame for stuff, people would complain just as much if the dates was not correct. But here is what we know so far at least: 6.13 -ZFS part2 -Will be the last version of Unraid 6 7.x -ZFS expand zpool -Multiply Unraid-Arrays -Everything will be a pool, multiply unraid-pools, zfs-pools, btrfs-pools -Mover updated so you can use mover from pool to pool -Requirement for Unraid-array to start, lifted -VM Snapshot and VM cloning -WebGUI seach, with multilingual support -IntelARC support Future ideas: -Hardware database: will my hardware work with Unraid? Database with users config, if they work or what you need to do for it to work. Users can choose to upload their setup anonymously -My Friends Network: expanding of UnraidConnect. Backup files encrypted/unencrypted to other Unraid servers -Responsive webgui -UnraidAPI4 points
-
We know that Dynamix File Manager is expected to be built-in for the 6.13 release4 points
-
Ich hätte als Threadersteller die Lösung dem Problemlöser (ich777) zugesprochen anstatt sich selbst. Gibt ja auch ein Ranking hier im Forum.4 points
-
I just wanted to post an update about my progress with 1.5.5. It was a busy weekend but I did get a chance to work on it. I ran into an issue that I'm trying to figure out but I think I'll be able to get it out before week's end.3 points
-
Da hast du den Fehler... USB hat im Array und Pool nichts zu suchen und führt regelmäßig zu genau diesen Problemen3 points
-
Hab ich das richtig gesehen? Das Ding kostet € 400 - € 500.- ? Hell wozu??? 🤪 Nimm ein Fractal Design Define 7 - das kostet nur ca. € 160.- und kann "bis zu" 14 Laufwerke aufnehmen. https://geizhals.at/fractal-design-define-7-black-fd-c-def7a-01-a2239761.html?hloc=de3 points
-
Wir nutzen Keepass in der Firma. Das Browser Plugin funktioniert nicht von denen.. Dies und die langsame Performence des Servers bewegte uns nun nach glaube 5-10 Jahren oder so, zu einem andern PMGR zu wechseln. Ich kann Bitwarden (Vaultwarden) empfehlen.3 points
-
No. The whole purpose of the parity swap procedure is to replace a parity drive with a larger one and then rebuild the contents of the emulated drive onto the old parity drive that is replacing the disabled drive. It works in two phases which have to both run to completion without interruption if you do not want to have to restart again from the beginning. the first phase will copy the contents of the old parity drive onto the new (larger) parity drive. During this phase the array is never available.. when that completes the standard rebuild process starts running to rebuild the emulated drive onto the old parity drive. If you were doing this process in Normal mode the array is available but with reduced performance (as is standard with rebuilding). If running in Maintenance mode the array will become available only when the rebuild completes and you restart the array in normal mode.3 points
-
Ich meinte damit, dass Du opnsense offensichtlich virtualisierung willst. DAS ist ein no-go...zum rumspielen ganz ok, aber nicht für produktiv genutzte Netze. Ebenso die Frage nach dem Skill-Level...eine echte Firewall ist schon was anderes als ein Netz hinter NAT zu verstecken. Überlege Dir ob Du das brauchst und ob Du selbst Deine Zeit reinstecken musst (welche dann nicht für Dein Business zur Verfügung steht). My 2cents3 points
-
zum Beispiel, oder Smart TV App, oder oder oder ... Nein und gar nicht so ... wenn dann in einer VM mit einer dedizierten GPU ... und dann ja, BT, CEC (Bastelarbeit), ... das wäre wahrscheinlich aktuell die beste Option ...3 points
-
@anknv@Aer@rubicon@ippikiookami (and those I forgot 😅) I just pushed a new version that should fix issues with InvokeAI. They removed almost all parameters when launching the UI so the file "parameters.txt" is no longer used and will be renamed. Instead, a default config.yaml file will be placed in the "03-invokeai" folder, you can modify it to suit your preferences. I had a very short time to test, I hope I didn't leave too many bugs 🤞 Fixes I made for auto1111 path and Kohya are now also in the latest version.3 points
-
Hallo, danke an die Beiträge hier im Thread, das richtige CPU Pinning hat bei mir das ruckeln im HTPC abgestellt mit der Wiedergabe über MPC-HC / MADVR. Gruß Andi3 points
-
3 points
-
@TheCyberQuake Update the Repository: entry with "rommapp/romm:3.1.0-rc.1" - thank you @zurdi15!!3 points
-
Please update to 6.12.10-rc.1. It should fix this issue. It's available on "Next".3 points
-
dang I missed it, can we get a do over today?3 points
-
I'll just finish out by saying that April 1 is an opportunity, NOT an obligation. There are plenty of people to be pranked who are not your paid customers running your mission critical software on OUR hardware. Especially a prank that appears, at first glance, to indicate that something has gone seriously wrong with that software or the backing infrastructure. The tech world seems to take April 1 as some sort of "global challenge day". But it's not. it has turned into a day I dread, because every company/site wants to prove how clever and "fun" they are - yet often prove the opposite. Prank your friends. Prank your family. Prank your co-workers. But in the future, please leave my server out of it.3 points
-
I mean sure, humor is great. There's a time and a place. The time is definitely April 1st. The place? I'm not sure that should be on mission critical servers (or any servers) that people and businesses trust and rely on. Especially when they have paid for the infrastructure that runs it.3 points
-
I'm waiting on the upstream update, if it doesn't happen by the end of this week then I shall have to compile it myself and include in the build Sent from my 22021211RG using Tapatalk3 points
-
Thanks, we're looking into it3 points
-
It's an April Fools thing, and incredibly inappropriate to put onto our servers.3 points
-
lol... got me for about 10 seconds!... good one!3 points
-
Der Fehler konnte im BUG Thread zwischenzeitlich reproduziert werden und wird sicherlich bald behoben. Danke an alle die geholfen haben. Den Thread mariere ich als gelöst. Frohe Feiertage euch allen. 🐰3 points
-
Because many users want this plugin, I have forked the template to allow the Apps Tab to install it (and for FCP to not complain about it being installed). I am unlocking this thread because whether or not the author has decided to go with a different direction on his OS needs, this is still the support thread for this plugin, and the plugin itself is unchanged. Note that there is ZERO support for this plugin from the author (and myself), and please feel free to fork this plugin yourself if you have the capability to support and maintain it. I personally do not agree with the fundamental nature of what this plugin does so I will not be maintaining it.3 points
-
I agree there's a use case for ZFS. That use caae is e.g like you said, high speed storage for video editing. And its no coincidence that this is exactly the use case for the big youtube channels who have terabytes of new video, massive builds, and promote Unraid. I believe when LTT did their first Unraid video it was a huge boost in sales. This use case is diametrically opposite to what home users need. And ironically, a real enterprise would also never use Unraid because its inherently insecure, they have no use for things like community apps, and they have a hundred other options to run ZFS or even better file systems like ceph etc. So Unraid's biggest promoters on social media, with a very niche set of demands that are irrelevant to the majority of the userbase, end up driving the feature set, because they directly influence sales, much more than you or me. And the other undeniable fact is LT is a smalll company with very limited resources. Its fine to say that 'it isn't taking away the ability' but it IS taking away developer time and resources which is far more important. There are a ton of features that can and should be improved before ZFS.3 points
-
I don't think Unraid is widely used in the commercial space. From it's inception, it has been designed and built to target the home market. Unraid first and foremost is a NAS. Business/enterprise customers looking for a NAS want very fast, robust, tried and true solutions and unfortunately, Unraid doesn't meet that criteria currently. Unraid's default storage scheme is good for ease of expansion, that still provides redundancy, but it's no speed demon. They've added caching to help with writes to the array, but when it comes to reads it's still slow. That being said, by adding ZFS Unraid is closing the gap. Whether or not that's enough to make it an option for businesses, remains to be seen. The other big factor in all of this is that a lot of business/enterprise customer's typically want support contracts and to be honest, I don't know if Lime Tech really wants to go down that path atm. Maybe if they grow enough to support it, but business/enterprise customers are different animals entirely compared to home users. The needs, wants and expectations from businesses are very different than home users. So I'd say for now, Unraid will still remain largely a solution targeted at home users, but who knows, that could change down the road. Yes and no, As I've said in my post above, I do understand the frustrations and skepticism, however, Lime Tech did in fact take some of that feedback and implemented some changes before the actual licensing terms changed (ie: increasing starter from 4 to 6 devices, and offering support updates to those who do not wish to renew the update licensing each year). Yet there wasn't even an acknowledgement of any kind from some of these people to at least say "ok Lime Tech is taking feedback into consideration and trying to alleviate customer concerns." I fully understand and I do not blame them one bit if they still feel skeptical and unsure, but to constantly be overly negative no matter what Lime Tech does to help alleviate concerns is just complaining plain and simple. Edited to make points a little clearer.3 points
-
No native Docker-Compose option 🥲3 points
-
Parity im Unraid Array wird nur bei folgenden Situationen geweckt: 1. Schreiben ins Array (lesend und schreibend) 2. Parity Check (grundsätzlich lesend) 3. Plattentausch (grundsätzlich lesend, außer Parity Platte selbst dann schreibend) 4. Defekter/emulierter Platte (abhängig von Aktivität im Array, lesend und schreibend) Nachtrag 5. Hinzufügen einer neuen Platte (nicht precleared, schreibend) Das wars.2 points
-
Steht im Thread. Lesen. Nicht alles x-mal fragen. Aber weil ich heute gute Laune habe geb ich Dir einen Spezialtip. Steht unter anderem auch auf exakt Seite 12 dieses Threads, sprich dieser Seite!!! PS: Ja das soll böse klingen. Es ist nicht akzeptabel alle Infos hier in dem Thread 10 mal zu wiederholen weil einige nicht gewillt sind zu lesen. Dadurch wird der Thread maximal unübersichtlich.2 points
-
I've put some time into troubleshooting UD to see if there is something in the way UD is mounting remote shares. There doesn't seem to be anything that UD does or can do to cause this problem. I'm not one to play the blame game, but as we get into this I believe we are going to find it's related to a change in Samba or a Kernel change causing this. In our beta testing for one of the recent releases, we found an issue with CIFS mounts where 'df' would not report size, used, and free space on a CIFS mount point. When UD sees a CIFS mount with zero space, it disables the mount so UI browsing and other operations could not be performed. UD assumes there is a problem with the mount. It ended up being related to a 'stat' change in the Kernel failing on the CIFS mount. As has been said, this is related to remote mounts through UD. It does not affect the NAS file sharing functionality through SMB. I understand that this is an important functionality for many users and for the moment, downgrading to 6.12.8 is the answer. We will release a new version of Unraid as soon as we have an answer.2 points