



Ford Prefect
Members
-
Joined
-
Last visited
-
Da mein USB-Stick einen Fehler wirft (beim Boot wird ein defekter Sektor ausgegeben - läuft aber noch) habe ich mir für mein Gigabyte C246M-WU4 mal den hier bestellt: https://www.amazon.de/dp/B0CCVRCB8S?ref=ppx_yo2ov_dt_b_fed_asin_title Ich warte noch ein paar Wochen, bis eine 7.3.x rauskommt und werde dann wohl mal migrieren. Edit: weiß jemand ob man das Modul im BIOS aktivieren muss (dann müsste ich wohl mal Monitor und Tastatur anschließen - Aufwand ;-) )??
-
..oder man richtet auf Server A, B und xxx eine direkte, feste Weiterleitung nach Gmail ein. das klappt zuverlässiger als das Abholen durch Gmail. Die Identitäten von A, B, xxx kann man trotzdem in Gmail anlegen und Gmail erkennt die eingehenden Mails aus der Weiterleitung auch.
-
...die Idee ist nicht neu. Das Problem - Empfang ist eher kein Problem - ist, das der neue Zwischenserver beim Versand die/Deine Identitäten von/auf Server A oder B nutzen muss. Das macht er aber nicht, weil er über SMTP direkt zum Ziel geht und nicht den IMAP-Server A oder B nutzt. Das einzige System, das ich kenne und das sowas kann ist Google-Mail (GMAIL). Edit: oups, @_alo_ war schneller.
-
no need for that kind of walkthrough, really. unraid also supports exporting storage as "shares" via NFS or SMB...so simply export that array as a share and mount it via NFS or SMB from inside each VM...virtIO-drivers in the VM should help to speed-up the connection above physical network bandwidth (up to CPU/Bus-Bandwidth is possible here).
-
..dann stelle mal in den Einstellungen bei der IP-Adressvergabe auf "static" und vergib die IP und DNS passend selbst. Weiterhin "Bonding" auf "AUS". Wenn das nix hilft: Hast Du irgendwelche Stromspar-Einstellungen im Unifi oder im unraid BIOS (ASPM) für die Ethernet- und/oder für PCIe-Interfaces gemacht? Vielleicht hast Du Dich da nur verwirrend ausgedrückt, oder wie wird bei Dir das Netzwerk denn im konkreten Fall "getrennt" - eigentlich ist da kein Bedarf das Netzwerk zu trennen, schon garnicht im Betrieb? Edit: ...oder sind unraid host und Dein Client nicht im gleichen IP-Netzwerk? In Deinem Screenshot ist der DNS für unraid aber ident zum Gateway = Deinem Unifi. Wenn unraid oder der Docker nicht läuft aber Dein Router den Adguard als DNS haben will, wird kein I-Net funktionieren, solange Dein Router die IP zur Adresse nicht noch im Cache hat. Insbesondere dann doof, wenn Dein unraid nicht 24x7 oder zumindest synchron zum Router aktiv läuft.
-
sind jetzt nicht allzu viele Info zu sehen, aber wie viele Ethernet Schnittstellen hast Du denn aktiv im System und sind mit nem Switch verbunden (da Du Bridgng und Bonding aktiviert hast)? Man sieht auch, dass Du zwar die Einstellung für ip4 auf Automatic hast, aber auch eine statische Adresse zu sehen ist. Was hast Du für nen Router? Bei Automatic sollte der die IP4 vergeben...ansonsten stelle IPv4 Vergabe auf "Static" und vergebe eine ungenutzte ausserhalb des DHCP-Pools des Routers in den Einstellungen.
-
Netzwerk-Einstellungen sind Basis-Arbeit. Während dieser Prozedur brauchst Du die Daten ja nicht. Also statt Array mit Parity einen einsamen, weiteren USB-Stick oder kleine SSD als Array einbinden.
-
Dann hast Du was falsch gemacht, beim einrichten. Das Interface br0 hat immer VLID=1...weitere VLANs sind dann br0.xx, zb br0.30 für VLID = 30. ...Du musst den config-Ordner sichern und wiederherstellen. Wenn Du Probleme mit dem Netzwerk hast, kannst Du für einen Hard-Reset des Netzwerks da drin die network.cfg und network-rules.cfg löschen. Für solche Tests ist es evtl. auch geschickt, den Autostart von Docker und VM Service zu deaktivieren.
-
Die Frage ist jetzt, was Du erreichen willst. Wenn Du mit den Netzwerkeinstellungen spielst, musst Du Docker und VM-Dienste vorher deaktivieren. Ein Neustart von unraid, nach dem speichern der Änderungen kann nicht schaden. Wenn Deine Netzwerk-Konfig läuft, dann kannst Du Docker und VMs wieder aktivieren...und vor dem Start der einzelnen VMs und Docker die Netzwerk-Einstellung wieder rchtig anpassen, mit/ohne VLANs. Nein, wie kommst Du auf die Idee? Der Name hat netzwerktechnisch keine Bedeutung. klassisches Henne - Ei Problem...zentrale Dienste gehören nicht in einen Docker. Ich empfehle auf jeden Fall, dem unRaid Host ne fixe IP im Management VLAN zu geben.
-
Parity, egal ob RAID oder unRAID ist kein Backup. Ich glaube, Du hast noch nicht verstanden, wie das Array (mit/ohne Parity) und auch das Cache/Pool-Konzept in unraid funktioniert. zwei schlanke SSDs passen physisch schon in den Raum einer 3.5er HDD...wie viele SATA-Ports hat der Lenovo...nur den einen? Nein, aber Backups werden nicht auf dem gleichen Hobel aufbewahrt. EIne externe Festplatte - die bei wirklich, wirklich wichtigen Daten in ein Bankschliessfach wandert - tut es auch. Ich würde das mal angehen, wenn Du bei unraid bleiben willlst. Von hier aus schwer zu sagen, wie/warum Deine Daten verschwunden sind. Die unterschiedlichen Disk-Grössen und unterschiedlichen Interfaces, gerade wenn diese Technologien im Arra und Pools gemischt werden, kann auch zu Problemen führen. Ich würde die 8TB in ein USB-Gehäuse packen und für Backups nehmen. Da Du Redundanz willst, würde ich zwei identische Disks ins Array packen..für "kalte" Daten, die nicht ständig aktiv von einem Docker und d´VM genutzt werden. Für Docker und VMs und Cache dann die beiden M2 nehmen. Wenn Du da auch Redundanz willst, bei VM und Docker auf zwei identische in einem dedizierten Pool aufrüsten. Cache kann mMn auch erstmal eine SSD bleiben. my 2 cents.
-
OK, hmmm...WAS heisst denn genau "funktioniert nicht mehr"...ist der Hobel stehen geblieben? Wie ist das denn gemeint? Backups von unraid(-Daten) auf dem unraid selbst ist ja wie Streichhölzer neben dem Terpentin aufzubewahren. Unraid mit Parity im Array oder Raid im Pool sichert überhaupt nix, sondern sorgt nur für redundanz. Zum sichern macht man Backups, aber eben nicht auf dem glechen Hobel ablegen. Diese Kombination ist jetzt für gewünschte Redundanz nicht optimal, mit unterschiedlichen Grössen und auch Interfaces. EIne SATA HDD als Parity und dann ne M.2 SSD für Daten im Array ist wenig optimal. Die 8TB als Daten scheinst Du garnicht zu benötigen, wenn Du sie als Parity genutzt hast. Warum hast Du die angeschafft? Was benötigst Du überhaupt und wärst Du in der Lage am Setup was zu ändern (zB die 8TB zu verkaufen und 2xSATA SSD dafür zu holen)?
-
...schonmal roundcube webmail angeschaut?
-
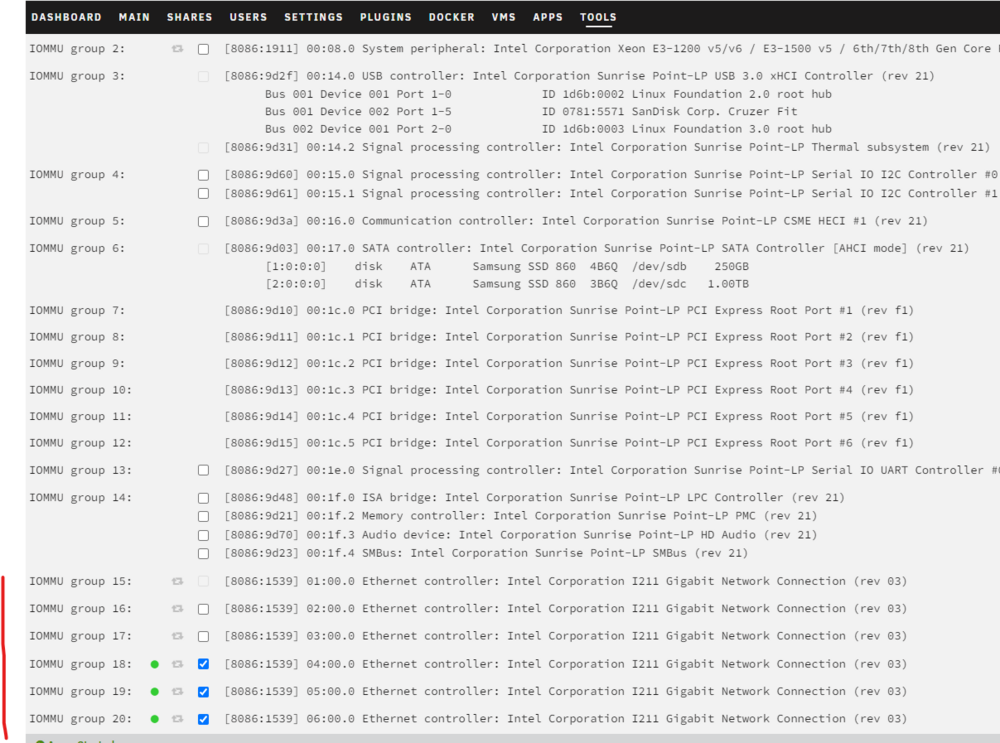
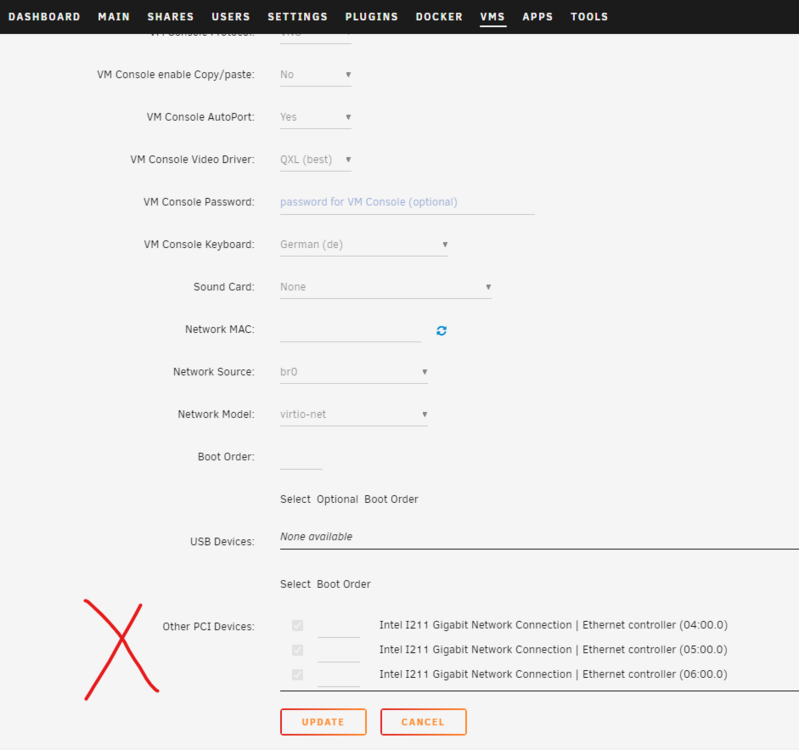
Genau. USB ist etwas spezieller, weil da - wenn peer IOMMU - der Controller durchgereicht werden muss....Ports durchreichen ist ein anderer Mechanismus. IOMMU "durchreichen" geht immer auf Ebene PCIe...also immer der ganze Controller...egal ob NIC, USB-Karte, dGPU, SATA... OK, das ist dann Pech. Hängt von der Hardware ab...die meisten Intel-Nics können es. Gibt hier sicherlich einige Beispiele...IOMMU geht quasi in den Settings (Tools -> SystemDevices ...da kannst Du die Geräte markierenn und nach einen Reboot sind sie aus dem unraid Host verschwunden und können dann in einer VM hinzugefügt werden). ZB bei mir: ich habe hier 3 von 6 NICs markiert ....und in meiner Router VM wieder aktiviert Nein und Nein..allein alle vNICs teilen sich die PCIe-Bandbreite des realen NIC...die andere Seite sieht einen NIC. Ohne dedizierten PCIe-baserten Controller auf Deinem System schwer.
-
Im Inneren des Switch sind die immer getagged. Port-Based bedeutet: das Pakete, welchen von extern auf den Port treffen und selbst untagged sind, mit der PVID getagged werden und mit dieser ID in den Switch gehen Das bei Paketen, welche über den Port den Switch verlassen die VLAN-Tags - je nach Konfig des Port nur die PVID - entfernt werden. Port based VLAN bedeutet hier, das alle VAN-tags entfernt werden. mit Port based VLAN wird der Switch quasi entsprechend der Aufteilung der PVIDs auf den Ports geteilt, wodurch im Inneren dann eben nur Ports mit gleicher ID untereinander kommunizieren können. ...die die eine VM. Der NIC wird quasi in die VM "eingebaut". Ich habe für diesen Zweck eine Intel-T4 eingebaut. Eine Alternative, um Ports quasi zu vervielfältigen wäre ein NIC, der SRV-IO unterstützt. Damit wird der NIC selbst virtualisert und man kann aus einem Port dann 8 unabhängige Ports machen, die einzeln genutzt werden können. Intel-Karten unterstützen das in der Regel. Das ist nur die IP, also L3...auf L2-Ebene, dem virtuellen Switch, sind VM und unraid-host immer noch verbunden. ...auch hier gilt das zuvor gesagte. Siehe dau: https://docs.unraid.net/unraid-os/manual/vm/vm-management/#configure-a-network-bridge Wenn Du VMs von unraid wirklich komplett, zuverlässig separieren willst, dann bleibt nur das Durchreichen des NICs an die VM per IOMMU. Wenn Du nicht genug Netzwerkkarten/Ports installieren kannst: mit SRV-IO auf dem NIC bekommt jeder V-NIC eine eigene IOMMU Gruppe und kann dann auch dediziert an eine VM durchgereicht werden. Nachteil: alles VMS/V-NICs müssen sich die Bandbreite der Karte teilen. Inzwischen sollte SRV-IO bei unraid "unter der Haube" verfügbar sein und eine Konfiguration (Kommanddozeile, GO-File) ohne vorherigen Kernel-Patch möglich sein. Siehe auch: https://forums.unraid.net/topic/103323-how-to-using-sr-iov-in-unraid-with-1gb10gb40gb-network-interface-cards-nics/
-
Wie meinst Du das genau...ohne VLANs oder hast Du am Switch VLANs aktiviert und die Ports mittels PVIDs "getagged". Es gibt für untagged VLANs kein Konzept...VLANs sind immer tagged...untagged/tagged ist die Unterscheidung am Ein-/Ausgangs-Port eines Switch ob die andere Seite auch VLANs "spricht" (tagged) oder nicht (untagged). Wenn Du keine VLANs nutzen willst, kannst Du die Hardware-Ports per IOMMU an die jeweilige VM durchreichen...dann sind sie für Unraid und die Docker unsichtbar. Das geht aber oft nicht bei on-board Ports, da die dann nicht allein in einer IOMMU-Group sind.



