

DrMexSS
-
Posts
27 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by DrMexSS
-
-
Thank you Joe,
I am using the last version of the preclear script. However, I am using a tv as the monitor, and I don't see everything that is printed in the screen. There was a message saying something with the "> 2.2TB", but I wasn't able to read it.
Therefore, I understand that everything is OK.
Thank you very much.
-
Hi!
I have one question regarding the 4k alignment.
I am preclearing 2 drives in parallel (new drives) in a new computer. I have downloaded unraid and preclear. Boot from usb and entered to the console.
The drives:
Western Digital Green 4tb : wd40ezrx
Western Digital Red 4tb : wd40efrx
I have writen the following line in the console (one console per disk)
preclear_disk.sh -A -c 3 /dev/sdc
preclear_disk.sh -A -c 3 /dev/sdb
In both cases the preclearing is starting at sector 1 (not at sector 64)
Is there any problem?
Last year I precleared a 3tb western digital green drive in my current unraid ring and the preclear started at sector 64.
-
Quite interesting the following product from intel:
http://www.anandtech.com/show/6509/intel-launches-centerton-atom-s1200-family-first-atom-for-servers
atom for servers
From 1.6 GHz (6.1 W) to 2.13 GHz (10 W)
Pricing starts at $54
What do you think?
-
Thank you so much for the responses! you are the best.
I wanted to avoid the step of creating a new folder, because otherwise I have to change different programs that point to the original folders.
I will try the eroz solution.
Thanks again.
-
Hi,
I have a little doubt about mapping user shares.
My unraid box (Tower) has 7 disks. And I have 3 shares:
Tower/TV
Tower/Movies
Tower/MoviesHD
If I map each share , I achieve the following:
Tower/TV : mapped to X:
Tower/Movies: mapped to Y:
Tower/MoviesHD : mapped to Z:
So, so for example, if I click on X: I have the following structure:
X:/How I met your mother
X:/The Big Bang Theory
...etc
However, I want to have ONE disk with ALL the user shares. For example, lets call it W:. So, if I click on W: I want to have the following:
W:/TV
W:/Movies
W:/MoviesHD
How can I do that with Windows 7?
Thank you so much.
-
Thank you Johnm. I didn't know that. I'm learning a lot with you (regarding another post in which you gave me a lot of ideas for upgrading my ring)
I liked the rpc-612 because it has room for 13 hard disks. I see a lot of expansion slots in the upper side but I thought that it wouldn't be a problem. Just some tinkering.
However, looking it carefully, the ventilation flow of the hard-disk area is not very good.
I think I will have to build my case with wood, because I don't find the case that I want!

Thank you.
-
Hi!
I'm interested in the norco rpc-612 due to its low depth (450 mm), but it's impossible to find a place where I can buy it.
Is it a new cage?



-
ouuuu yeah! thank you for that big amount of info!
However, I think that a better option would be something like the norco DS-24D but cheaper and for less disks. Then connect that case to my lian-li by one or two SFF-8088 cables (I just learn this). I think that this option will give me more possibilities. Moreover, I would like a hard-disk case with less than 420 mm depth (the norco ds-24D is 480 mm). So, I will have to search for it. I think it will be difficult because the 420mm constraint is "hard".
Thank you for the info, I have learnt a lot.
-
Thank you for your replies!

Why don't combine both? Add a new lian li pc-v354 with: a power supply and hard disks connected to a SAS controler. Then install another SAS controller in the unraid case and connect both cases with just one cable.
Am I correct? Is it possible?
@technojunkie: The sas expander chassis are too expensive I think, and if I can do what I said above I will obtain the same performance. However, the possibility of having a 20 hdd unraid system is so tentative... aaaaahhhhhhh
-
Umm.... interesting. I didn't know about port multiplier. Thank you.
Thank you again for the link of the Sans Digital case. It's a good offer with the eSata pci card.
However, in any case I will have performance loss (during parity check or rebuilding) and this is something that I don't want.
So, I think that something like this could be an interesting option:
http://www.norcotek.com/SS-500.php
It's a box that has a couple of power connectors and one sata connection for each drive. I know that it is an inside box (convert 3 x 5.25" drive bay into 5 x 3.25" ). But my plan would be putting it outside and to buy a pci sata controler for my unraid system. There would be 1 power and 5 sata cables from my unraid case to the ss-500 box but I don't know how to reduce this number of cables without losing performance.
-
One of the top-topic of today is about my problem! great.
http://lime-technology.com/forum/index.php?topic=14620.0
There the user Johnm says:
Another more expensive option that is along your same theory is to turn the second case into an external drive bay.
you can use adapters like these http://www.pc-pitstop.com/sas_cables_adapters/ . a sas expander would work also if you had a lot of drives in case #2.
slightly cheaper http://www.addonics.com/products/multilane/connector.asp
you would then have 1 or 2 wires that just run from one box to another...
I was looking at this idea to convert a norco 4224 into a drive bay for another norco.
you might even be able to use some cheap sata to esata adapters if you only have a few drives. then run a few esata wires from one case to the second..
something like this maybe? http://www.monoprice.com/products/product.asp?c_id=104&cp_id=10407&cs_id=1040707&p_id=7638&seq=1&format=2
use a set of those OR an esata card in your unraid box and run them to the esata brackets on box #2? this is personally untested but should work... I had done this with a 4 port board once. http://www.addonics.com/products/io/ad4esasb.asp
just make sure all your connections are solid.
So maybe it's cheaper to buy an extra regular case just for hard disks and a PSU (to avoid extra cables from the first case)
-
Hi!
My actual ring is this:
Case: Lian-Li PC-V354 -> Space for 7 Hard Disks :: http://www.lian-li.com/v2/en/product/product06.php?pr_index=546&cl_index=1&sc_index=25&ss_index=63&g=f
Motherboard: Asus P5Q-VM :: http://www.asus.com/Motherboards/Intel_Socket_775/P5QVM/
----> 6 xSATA 3 Gb/s ports
----> 1 x PCIe 2.0 x16
----> 2 x PCIe x1
----> 1 x PCI
I have also installed a Intel/pro 1000 ethernet card in one of the PCI (I don't remember in which one now but I could change it if it's necessary). I installed this new NIC because the onboard NIC of the motherboard has the Realtek® 8111C chip and it has problems with unraid.
I bought that case because the server has to be in a place with height restrictions.
The problem:
I curently have 6 disks in my array (1parity +5 data) so all my sata ports are used. However, I want more space
. How can I add it without changing the case?I was thinking in buying:
-Pci card with more sata ports (or eSata ports)
-A external case with sata or eSata ports (Like the lian li EX-50 :: http://www.lian-li.com/v2/en/product/product06.php?pr_index=331&cl_index=12&sc_index=42&ss_index=115&g=f )
Will it work? Does the eSata ports work as sata ports? Same performance?
Do you recommend something different? (Another case, or approach...)
Thank you so much.
-
I had a unjumpered ears drive that I needed to align, so did the following
TO PROPERLY ALIGN AN UNJUMPERED EARS DRIVE ALREADY IN THE ARRAY
1 - Make sure the unRAID alignment setting is "4K aligned"
2 - Take a screenshot of the unRAID main page. Save it in a JPG or print it out.
3 - Stop the array
4 - Unassign the disk from the array
5 - Start the array (may need to check the checkbox to start the array) - THIS IS VERY IMPORTANT. Array must be started with disk missing.
6 - Stop the array
7 - From telnet prompt run the following commad. This clears the MBR and is necessary to change the partition alignment.
dd if=/dev/zero count=200 of=/dev/sdX
where sdX the is device. Look on unmenu, myMain or the unRAID devices page for the 3 letter device code (e.g., sda, sdb, ...)
8 - Reboot (click reboot buttong on unRAID GUI)
9 - Array should not start automatically. DO NOT START IT YET!
10 - Preclear (optional - if you precleared it when it was new and it is not giving trouble, no need to preclear it again)
11 - Verify that the unjumpered disk is assigned to its prior slot (e.g., if this was disk3, make sure the disk is again assigned to disk3)
12 - If not - go to the devices page and assign it to the devices page
13- Go to main page and compare it to the screenshot taken in step 2
14 - You should see unRAID saying that it will rebuild the disk. (You may need to click a checkbox to enable the start button)
15 - Start the array
16 - Disk will rebuild, let it finish
17 - Verify contents of rebuilt disk
However, when I rebooted the array started atuomatically (step 9). So I stopped the array and continued with the steps. Now it's rebuilding.
Why did my array started? Is it a symptom of something wrong? I followed carefully the steps.
UPDATE 7th Oct 2011: Now my system is much much faster! Copying a big file: Before: 15MB/s --- Now: 30 MB/s. The parity check speed was always great (90 MB/s).
Note: My system has 1parity+5 data disks (the parity and 3 data disks are 2TB EARS)
-
Thank you so much for your responses. This is such a great community!
I will do that. Maintain version 4.5.6, replace the failed disk with a new jumpered drive and prey for a good rebuilding.
In a next chapter I will do the upgrade.
Thank you so much.
-
thanks!
I will do what you suggest but I have a dubt: Should I first upgrade to version 4.7?
I see two possibilities:
A) Upgrade to 4.7. Then replace the disk5 with a new EARS (but with a jumper). Rebuild. Finally apply the procedure of putting a jumper in each other EARS drive following the steps of http://lime-technology.com/wiki/index.php?title=Advanced_Format_Drives
B) Replace disk5 with a new EARS (but with a jumper). Rebuild. Upgrade to 4.7. Finally apply the procedure of putting a jumper in each other EARS drive
Which one is the best?
Thank you.
-
Hi!
My situation before the problem:
Software: Unraid plus version 4.5.6.
Hardware: A system with 6 disks (1 parity 5 data)
Disks: Model - Temperature
Parity : WD20EARS - 38º
Disk 1 : ST31000528AS - 35º
Disk 2 : WD20EARS - 35º
Disk 3 : WD20EARS - 35º
Disk 4 : ST31000528AS - 35º
Disk 5 : WD20EARS - 36º
When I did the last software upgrade the newest version was 4.5.6 so I wasn't aware of the jumpered/unjumpered thing. Therefore, all the EARS drives are unjumpered (as I bought them) and I suppose that aligned at sector 63.
My parity check speed was about 90 MB/s
When copying a big file to the server the speed was about 15 MB/s
The problem:
Disk 5 (WD20EARS) has failed. The symptoms were greater temperatures than others disks (44º) and some read errors appeared (green ball and log said that). However, today, while doing a parity check, the system has stopped and the disk 5 has a beautiful red ball.
What I want:
-Repair the disk (repleace it with a new WD20EARS)
-Upgrade the system to unraid 4.7 or better.
-Put all the disks in 4k mode (64 sector)
The Question:
What are the correct order of steps?
What version of unraid should I use? 4.7 or the last v5 beta?
Thank you so much.
-
But I have run the test with the NOCORRECT option. The second time has NOT found any errors. I think everything is ok now.
In my opinion the error happened when Unraid rebuilt the disk the first time. I mean:
-Before opening the case, I run a parity check. -> No errors.
-I change the old disk with the new one.
-Unraid rebuilt the data (here there was 1 error because:)
-I run the test with NOCORRECTION option -> It found the error
-I unassigned the disk and precleared it.
-I put again the disk to the system. Unraid rebuilt again the data.
-I run the test with NOCORRECTION option -> It did not found any error.
So, the second rebuilt was done correctly and my data is safe.
p.d: Maybe I have been paranoid, it's just one bit!! (or byte?)
-
Well, it's solved.
After the rebuilding I run a NONCORRECT test and now I don't have any errors. I suppose that the error from the previous post is a bug. The system remembers that there WAS a sync error.
So, to sum up. The complete process I've followed is:
-I wanted to replace one disk with a bigger one
-I run a parity check (the regular one, with corrections)
-It found 0 errors.
-Stop the array
-Unassign the disk (disk 2 in my case)
-Power down
-Change the disk
Note, I forgot to run the preclear script on the new disk
-Power on
-Assign the new disk to the old slot
-Start the array :: Rebuilding
-When finish. Run the command
/root/mdcmd check NOCORRECT
You can see the progress in the web browser
-It found 1 error
-Stop the array
-Unassign the disk
-Start the array.
-Stop the array.
-Run the preclear.sh script over the disk (28 hours... bufff)
-Assign the disk to the slot
-Start the array. Rebuild.
-It finish. It shows 1 error. I assume it's the old one.
-Run the command.
/root/mdcmd check NOCORRECT
It shows NO error
-
I have done the following:
-Stop the array
-Unassign disk
-Start the array
-Stop the array
-run the preclear over the disk 2
Results: NO errors
================================================================== 1.9 = unRAID server Pre-Clear disk /dev/sdc = cycle 1 of 1, partition start on sector 63 = Disk Pre-Clear-Read completed DONE = Step 1 of 10 - Copying zeros to first 2048k bytes DONE = Step 2 of 10 - Copying zeros to remainder of disk to clear it DONE = Step 3 of 10 - Disk is now cleared from MBR onward. DONE = Step 4 of 10 - Clearing MBR bytes for partition 2,3 & 4 DONE = Step 5 of 10 - Clearing MBR code area DONE = Step 6 of 10 - Setting MBR signature bytes DONE = Step 7 of 10 - Setting partition 1 to precleared state DONE = Step 8 of 10 - Notifying kernel we changed the partitioning DONE = Step 9 of 10 - Creating the /dev/disk/by* entries DONE = Step 10 of 10 - Verifying if the MBR is cleared. DONE = Disk Post-Clear-Read completed DONE Disk Temperature: 32C, Elapsed Time: 27:10:05 ========================================================================1.9 == WDC WD20EARS-00MVWB0 WD-WMAZA3272095 == Disk /dev/sdc has been successfully precleared == with a starting sector of 63 ============================================================================ ** Changed attributes in files: /tmp/smart_start_sdc /tmp/smart_finish_sdc ATTRIBUTE NEW_VAL OLD_VAL FAILURE_THRESHOLD STATUS RAW_VALUE Temperature_Celsius = 118 121 0 ok 32 No SMART attributes are FAILING_NOW 0 sectors were pending re-allocation before the start of the preclear. 0 sectors were pending re-allocation after pre-read in cycle 1 of 1. 0 sectors were pending re-allocation after zero of disk in cycle 1 of 1. 0 sectors are pending re-allocation at the end of the preclear, the number of sectors pending re-allocation did not change. 0 sectors had been re-allocated before the start of the preclear. 0 sectors are re-allocated at the end of the preclear, the number of sectors re-allocated did not change.
-Then I assigned the disk again to the Disk 2 slot
-Start the array
The rebuilding process started.
- I did NOT run the "mdcmd check NOCORRECT" command but after the rebuilding I still have the 1 error. What I shoud do now? Normal parity test and forgive?
I have attached the new smartctl report of the disk 2
-
The test has finished, just one error.
I have attached the smart report.
Thank you
-
UPDATE: I have solved the problem. If you don't want to read everything I have summarized the steps in my 4th post in this thread.
Hi everyone,
I have doubts about my next step.
I have replace a disk of my system because I bought a bigger one. After doing that I run
/root/mdcmd check NOCORRECT
It's now running and it's founding errors... aaaaaaaaaahhhhhhhh
My system:
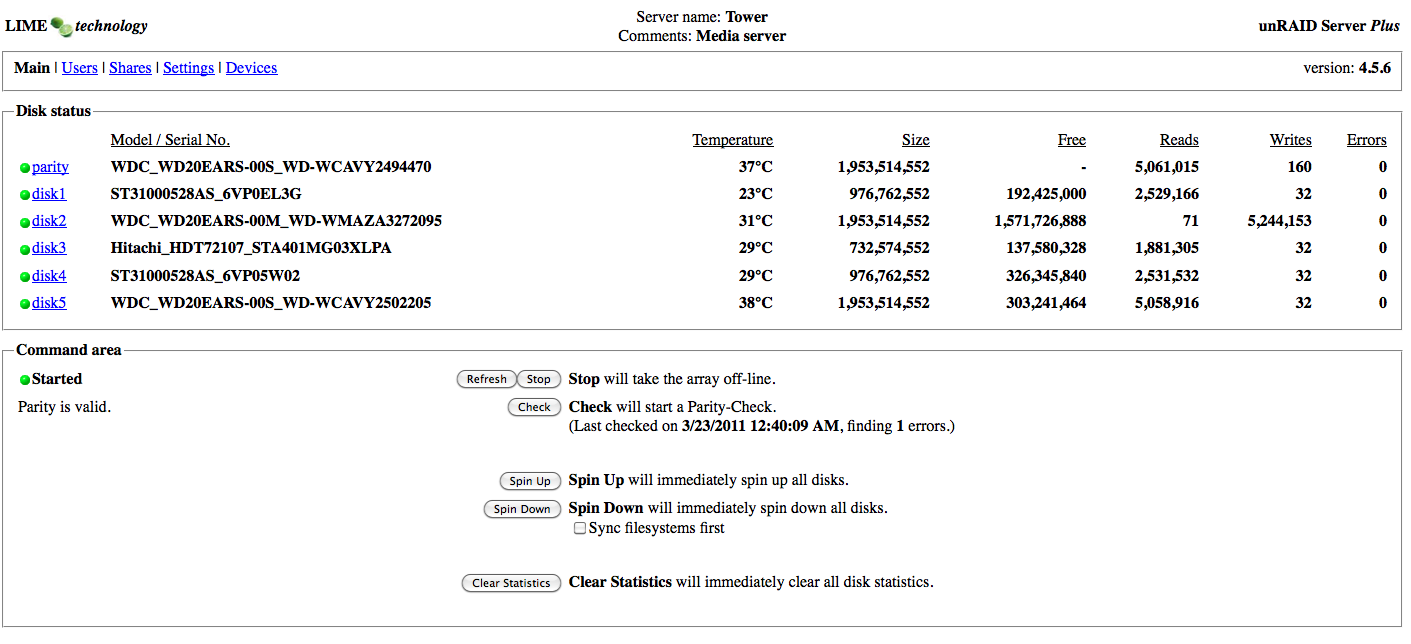
Unraid 4.5.6 - Plus key USB: Sandisk cruzer (16gb) Mobo: Asus P5Q-VM (asus) : Intel® G45 / ICH10 NIC: Intel pro/1000 CPU: Celeron S 430 (1x 1800 MHz) RAM: 2 GB Disks: Parity : Western Digital 2TB : WDC_WD20EARS-00S8B1_WD-WCAVY2494470 Disk 1: Seagate 1TB : ST31000528AS_6VP0EL3G Disk 2: Seagate 500 GB : ST3500830AS_9QG67DQX (THIS is the one I wanted to change) Disk 3: Hitachi 750 GB : Hitachi_HDT721075SLA380_STA401MG03XLPA Disk 4: Seagate 1 TB : ST31000528AS_6VP05W02 Disk 5: Western Digital 2TB : WDC_WD20EARS-00S8B1_WD-WCAVY2502205
I changed the disk2 with a new Western digital 2TB (WD20EARS)
The process I followed to change the disk was:
1º- Parity check.
2º- Power down, change the disk, power on
NOTE: I did NOT use the preclear.sh script !!!!!
3º- Devices tab > the new disk was assigned automatically to the missing slot.
4º- Start button, "I'm sure..."
The system did a rebuilding with zero errors.
Then, as I said, I run a non-correcting parity check :: /root/mdcmd check NOCORRECT
It hasn't finished yet. Here it is a capture of the process:

Syslog:
r 19 00:16:39 Tower login[1401]: ROOT LOGIN on `tty1' Mar 19 00:18:44 Tower kernel: mdcmd (39): check NOCORRECT Mar 19 00:18:44 Tower kernel: Mar 19 00:18:44 Tower kernel: md: recovery thread woken up ... Mar 19 00:18:44 Tower kernel: md: recovery thread checking parity... Mar 19 00:18:44 Tower kernel: md: using 1152k window, over a total of 1953514552 blocks. Mar 19 00:18:45 Tower kernel: md: parity incorrect: 26272
I have errors, (at least one). What do I have to do next?
This is my guess:
1- Stop the array.
2- Do a presclear.sh to the new disk2.
3- Assign again to the array
4- Start the array. It will start again the process of rebuilding.
Is it correct?
Thank you.
UPDATE : It has finished and it has just found that one error.
UPDATE : I have attached the smartctl info (command : SMARTCTL -a -d ata /dev/sdc | todos )
-
Sorry, I forgot it.
I have attached it now, but i will point out some lines
... Sep 8 17:55:31 Tower emhttp: shcmd (22): /etc/rc.d/rc.nfsd restart | logger\ Sep 8 18:03:33 Tower shfs0: duplicate object: /mnt/disk2/PelisHD/.DS_Store\ Sep 8 18:03:33 Tower shfs0: duplicate object: /mnt/disk3/PelisHD/.DS_Store\ Sep 8 18:04:31 Tower shfs0: duplicate object: /mnt/disk2/PelisHD/.DS_Store\ Sep 8 18:04:31 Tower shfs0: duplicate object: /mnt/disk3/PelisHD/.DS_Store\ Sep 8 18:04:36 Tower shfs0: duplicate object: /mnt/disk2/PelisHD/.DS_Store\ Sep 8 18:04:36 Tower shfs0: duplicate object: /mnt/disk3/PelisHD/.DS_Store\ Sep 8 18:45:50 Tower kernel: usb 4-2: new low speed USB device using uhci_hcd and address 2\ Sep 8 18:45:51 Tower kernel: usb 4-2: configuration #1 chosen from 1 choice\ Sep 8 18:45:51 Tower kernel: input: MLK Trust Deskset 15177 as /devices/pci0000:00/0000:00:1a.1/usb4/4-2/4-2:1.0/input/input3\ Sep 8 18:45:51 Tower kernel: sunplus 0003:04FC:05D8.0001: input,hidraw0: USB HID v1.00 Keyboard [MLK Trust Deskset 15177] on usb-0000:00:1a.1-2/input0\ Sep 8 18:45:51 Tower kernel: sunplus 0003:04FC:05D8.0002: fixing up Sunplus Wireless Desktop report descriptor\ Sep 8 18:45:51 Tower kernel: input: MLK Trust Deskset 15177 as /devices/pci0000:00/0000:00:1a.1/usb4/4-2/4-2:1.1/input/input4\ Sep 8 18:45:51 Tower kernel: sunplus 0003:04FC:05D8.0002: input,hiddev96,hidraw1: USB HID v1.00 Mouse [MLK Trust Deskset 15177] on usb-0000:00:1a.1-2/input1\ Sep 8 18:46:20 Tower login[1289]: ROOT LOGIN on `tty1'\ Sep 8 18:46:56 Tower kernel: ------------[ cut here ]------------\ Sep 8 18:46:56 Tower kernel: WARNING: at net/sched/sch_generic.c:226 dev_watchdog+0xf8/0x178()\ Sep 8 18:46:56 Tower kernel: Hardware name: P5Q-VM\ Sep 8 18:46:56 Tower kernel: NETDEV WATCHDOG: eth0 (r8169): transmit timed out\ Sep 8 18:46:56 Tower kernel: Modules linked in: md_mod ata_piix libata r8169\ Sep 8 18:46:56 Tower kernel: Pid: 0, comm: swapper Not tainted 2.6.29.1-unRAID #2\ Sep 8 18:46:56 Tower kernel: Call Trace:\ Sep 8 18:46:56 Tower kernel: [<c0120e07>] warn_slowpath+0x74/0x8a\ Sep 8 18:46:56 Tower kernel: [<c01190ed>] ? enqueue_task+0xd/0x18\ Sep 8 18:46:56 Tower kernel: [<c011c0fb>] ? try_to_wake_up+0x12b/0x136\ Sep 8 18:46:56 Tower kernel: [<c011c11d>] ? wake_up_state+0xa/0xc\ Sep 8 18:46:56 Tower kernel: [<c0129510>] ? signal_wake_up+0x23/0x31\ Sep 8 18:46:56 Tower kernel: [<c012968f>] ? complete_signal+0x171/0x178\ Sep 8 18:46:56 Tower kernel: [<c012992c>] ? send_signal+0x1ab/0x1c2\ Sep 8 18:46:56 Tower kernel: [<c01356dc>] ? getnstimeofday+0x51/0xdc\ Sep 8 18:46:56 Tower kernel: [<c022291b>] ? strlcpy+0x17/0x48\ Sep 8 18:46:56 Tower kernel: [<c02e9283>] dev_watchdog+0xf8/0x178\ Sep 8 18:46:56 Tower kernel: [<c0110039>] ? safe_smp_processor_id+0x39/0x84\ Sep 8 18:46:56 Tower kernel: [<c01285de>] ? update_process_times+0x49/0x4e\ Sep 8 18:46:56 Tower kernel: [<c01379cb>] ? tick_periodic+0x62/0x64\ Sep 8 18:46:56 Tower kernel: [<c02e918b>] ? dev_watchdog+0x0/0x178\ Sep 8 18:46:56 Tower kernel: [<c01281af>] run_timer_softirq+0x105/0x158\ Sep 8 18:46:56 Tower kernel: [<c0124a48>] __do_softirq+0x84/0x121\ Sep 8 18:46:56 Tower kernel: [<c0124b1a>] do_softirq+0x35/0x3a\ Sep 8 18:46:56 Tower kernel: [<c0124d97>] irq_exit+0x38/0x3a\ Sep 8 18:46:56 Tower kernel: [<c0104a69>] do_IRQ+0x67/0x7e\ Sep 8 18:46:56 Tower kernel: [<c01033a7>] common_interrupt+0x27/0x2c\ Sep 8 18:46:56 Tower kernel: [<c025a32e>] ? acpi_idle_enter_simple+0x11c/0x186\ Sep 8 18:46:56 Tower kernel: [<c02c1fcd>] cpuidle_idle_call+0x60/0x97\ Sep 8 18:46:56 Tower kernel: [<c01019dd>] cpu_idle+0x50/0x64\ Sep 8 18:46:56 Tower kernel: [<c0336813>] rest_init+0x53/0x55\ Sep 8 18:46:56 Tower kernel: ---[ end trace b36bc0f67b222a45 ]---\ Sep 8 18:46:56 Tower kernel: r8169: eth0: link up\ }
At 18:04:36 I was watching a movie normally.
But at 18:40 more or less, it stopped, so I plugged in a Keyboard to check.
-
Hi everybody, I have the same issue. Several weeks ago I posted the problem in the beta6 thread. I copy/paste it for the Hardware info:
-----------------------------------------------------------------------------------------
Sometimes, when I want to watch a movie it happens this:
1º- I power on the Tower
2º- I power the HTPC
3º- I select the movie using XBMC, which is pointing to smb://tower/PelisHD ---> User share.
4º- After 30-60 minutes of the movie, it stops. This is because the HTPC has lost the connection with Tower.
5º- I check the Tower with ANOTHER computer but the Tower doesn't respond. No http://tower, NO PING, nothing.
6º- Finally I go where the Tower is and I plug-in a keyboard (you can see in the syslog). I can access the disk, I can see in "ifconfig" that Tower has an IP, and... finally, when I type "top".... the pc that i use in 5º starts to receive the answer of the ping.
7º- Now I can return to my HTPC and continue watching the movie without interruptions.
I attach the syslog where is easy to find when I start to type in the Tower (Sep 8 18:45:50 Tower kernel: usb 4-2: new low speed USB device using uhci_hcd and address 2)
My configuration is this:
---
Unraid 4.5 beta6 - Plus key
USB: Sandisk cruzer (16gb)
Mobo: Asus P5Q-VM (asus)
Intel® G45 / ICH10
Realtek® 8111C PCI-E Gigabit LAN controllers, featuring AI Net2
CPU: Celeron S 430 (1x 1800 MHz)
RAM: 2 GB
HDD: 4 disks >> parity and disk1: Seagate ST31000528AS (1TB), others: 1 Hitachi 750 GB and 1 seagate 500GB
The router is a apple Time Capsule with DHCP, but I always give the IP: 10.0.1.2 to Tower (MAC reservation).
CAT6 cable.
---
-------------------------------------------------------------------------
Joe L. gave me this answer:
See this answer for some things to try (basically, they moved the "IRQ" the network card was assigned to one less used) : http://graag.blogspot.com/2007/12/netdev-watchdog-eth0-transmit-timed-out.html It is a apparently a bug with the driver for some realtek chipsets. Worst case, install a different network card.But finally I will change the NIC, I will try the Intel PRO/1000 or something like this. Anyone suggest another one?
-
Wow!!!
:)Thank you so much! That's what a call a good answer! I will try that trick!
Thank you again.

Gaming on a NAS? You better believe it!
in Unraid Blog and Uncast Show Discussion
Posted
Hello Jonp,
Were you able to do more testing about how much power does the GPU take when the VM are off?
Thank you.