

indy5
-
Posts
109 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by indy5
-
-
Still seeing the same results after a reboot. Do you want to see an updated Diagnostics file?
-
I am experiencing the same issue as described above. Diagnostics are attached.
-
xfs_repair ended with:
..Sorry, could not find valid secondary superblock Exiting now.
-
Good day Unraid Community,
For, for a bit of background that may have led to my current situation. I have been running a stable system for many years, gone through many drive upgrades, hardware replacements, etc. This past weekend I moved my entire system into a new case, installed a new drive controller (Adaptec 71605). After completing this process, everything was working properly, all drives detected, array started successfully.
At some point after things were working, after a reboot, one of my drives went Unmountable.
I started the array in maintenance mode, tried running xfs_repair via UI. The repair ran overnight and ended with a message that a Secondary Superblock could not be found.
I am not sure what else to do at this point and I want to make sure that I don't disturb anything, if there's a chance I can save the data.
I appreciate any help. Diagnostics are attached.
-
13 minutes ago, limetech said:
yeah, I see a problem, sorry next -rc should fix it 🙄
👍
-
On 1/23/2019 at 1:44 PM, limetech said:
Following this:
We added that firmware for the next -rc release.
Note: There may be other missing firmware you may run across depending on what device you're using. The problem is that the Linux world doesn't much like firmware - firmware files are referred to as 'blobs' which means they are just binary data files, which means they are not built from source.
There is a kernel firmware repo but in our experience different manufacturers are slow to submit their firmware (looking at you again Realtek). For example, why didn't those guys at plugable submit this firmware to be included upstream? Then they wouldn't have had to write that article explaining how to make it work. Oh well...
I have upgraded to RC2 and am still having issues with this device.
Jan 25 09:26:35 kernel: bluetooth hci0: Direct firmware load for brcm/BCM20702A1-0a5c-21e8.hcd failed with error -2 Jan 25 09:26:35 kernel: Bluetooth: hci0: BCM: Patch brcm/BCM20702A1-0a5c-21e8.hcd not found -
Please let me know if you want to see the full syslog, but here is what I am seeing in mine
Jan 22 20:41:54 kernel: Bluetooth: hci0: BCM20702A Jan 22 20:41:54 kernel: Bluetooth: hci0: BCM20702A1 (001.002.014) build 0000 Jan 22 20:41:54 kernel: bluetooth hci0: Direct firmware load for brcm/BCM20702A1-0a5c-21e8.hcd failed with error -2 Jan 22 20:41:54 kernel: Bluetooth: hci0: BCM: Patch brcm/BCM20702A1-0a5c-21e8.hcd not found -
Great news! Thanks very much
-
+1
Also very interested in this to pass device onto Homeassistant Docker.
-
4 hours ago, jonathanm said:
Passing through an entire USB controller instead of the individual device should work.
I will give this approach a try, thanks!
Out of curiosity, how does passing through the controller vs the specific USB device prevent the issue that I have seen?
Thanks for your help
-
I wanted to poll the group on what people are doing passing through USB devices to this container, more specifically the Aeon Labs ZW090 Z Stick. When testing out this installation in the past, I had issues where the USB port for the device would switch after a reboot of the Unraid server (ie ttyACM0 to ttyACM1). This of course, breaks HA's configuration and requires a change to the config files for the device to function again.
Is there any kind of more permanent solution to this case? Is there a way, to force the USB device to always use the same port? I have HA running on a raspberry pi2 at the moment and things are working fine (other than having to use a separate physical device). I would much rather run this app on my Unraid server.
I appreciate the feedback and other's experiences.
-
I got it working! see my other post https://community.home-assistant.io/t/wall-mounted-dashboard/1896/578?u=drjeff
I have followed your guide from the link, but now I am getting only this message in the docker log.
Switch to inspect mode.
I have altered the path mappings to my own appdata folder that I use for all of my other dockers.
Any thoughts?
Thanks!
-
Have a look at this dockerfile: https://hub.docker.com/r/marijngiesen/hadashboard/ This one is working.
What paths did you set up for the config files?
-
Has there been any progress on this container? I have been unable to get it started and receive the following in the docker log. I appreciate any help.
Traceback (most recent call last): File "/usr/src/app/hapush/hapush.py", line 347, in <module> main() File "/usr/src/app/hapush/hapush.py", line 298, in main config = ConfigObj(config_file, file_error=True) File "/usr/local/lib/python3.4/dist-packages/configobj.py", line 1229, in __init__ self._load(infile, configspec) File "/usr/local/lib/python3.4/dist-packages/configobj.py", line 1240, in _load raise IOError('Config file not found: "%s".' % self.filename) OSError: Config file not found: "/hapush/hapush.cfg". -
Thanks, this worked perfectly!
I'm getting this error when trying to update Plex Docker as well as CouchPotato
Any thoughts?
You will need to delete your docker image file and recreate it along with your containers. Your appdata for each should be fine, but the containers themselves need to be redownloaded into a complete new docker image file.
-
I'm getting this error when trying to update Plex Docker as well as CouchPotato
Any thoughts?
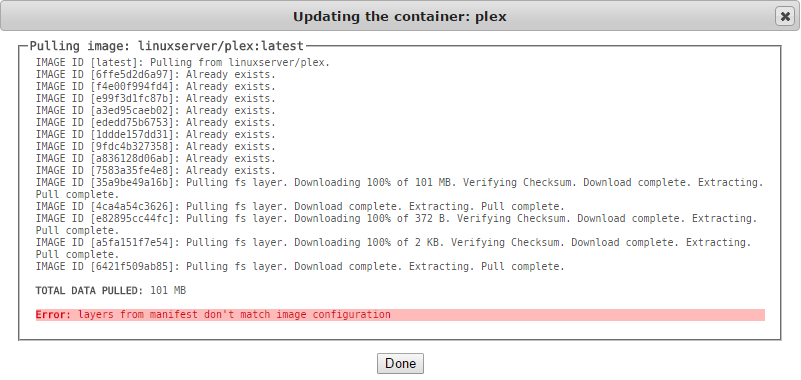
-
Any news on the latest updated version testing?
Looking forward to this as well.
-
Any reason why my Emby plugin for kodi keeps asking me for a password when I start kodi? Password is blank, I just hit enter and away it goes.
Same here, logon attempt just keeps spinning and spinning. I am able to connect via app.emby.media and manage my server, just not locally. All services seem to be up and running however.
-
After the upgrade i have noticed that the temperature of my disks have gone up by atleast 5°C. From under 30, to around 35.
First after i started the array, and let the disks spin down, the green status dots turn grey and temerature turns to a *. But if i do a smartctl -i -n standby /dev/sdb the disk is shown as active/idle. Then after a couple of minutes the dots are still grey, but showing temperature for all disks.
When i manually set the disk to standby with hdparm -Y /dev/sdb the disk temperature is shown as an *.
If i spin down all disks on the button in webgui, all disk temperatures are gone and * are showing. Even on my 4 cache disks that are hosting VMs and they are still green. And when i read from a disk that are spun down. It turns green, but doesnt show temperature. Even now if i do a smartctl -i -n standby /dev/sdb the disk is still shown as active/idle. And not standby
Attaching log files.
JoWe
Same here. I have never received notifications about high disk temperatures, until this update. Now I am seeing all of my drives running "hot" and getting frequent warnings.
-
All of a sudden starting getting the following in my log file - this happens with any drive that spins down - any idea on what to look for?
Mar 13 21:27:04 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:27:04 Tower kernel: mdcmd (74): spindown 8
Here is a force spindown command
Mar 13 21:40:28 Tower emhttp: Spinning down all drives... Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: mdcmd: write: No such device or address Mar 13 21:40:28 Tower emhttp: shcmd (7072): /usr/sbin/hdparm -y /dev/sdd &> /dev/null Mar 13 21:40:28 Tower kernel: mdcmd (76): spindown 0 Mar 13 21:40:28 Tower kernel: mdcmd (77): spindown 1 Mar 13 21:40:28 Tower kernel: mdcmd (78): spindown 2 Mar 13 21:40:28 Tower kernel: mdcmd (79): spindown 3 Mar 13 21:40:28 Tower kernel: mdcmd (80): spindown 4 Mar 13 21:40:28 Tower kernel: mdcmd (81): spindown 5 Mar 13 21:40:28 Tower kernel: mdcmd (82): spindown 6 Mar 13 21:40:28 Tower kernel: mdcmd (83): spindown 7 Mar 13 21:40:28 Tower kernel: mdcmd (84): spindown 8 Mar 13 21:40:28 Tower kernel: mdcmd (85): spindown 9 Mar 13 21:40:28 Tower kernel: mdcmd (86): spindown 10 Mar 13 21:40:28 Tower kernel: mdcmd (87): spindown 11 Mar 13 21:40:28 Tower kernel: mdcmd (88): spindown 12 Mar 13 21:40:28 Tower kernel: mdcmd (89): spindown 13 Mar 13 21:40:28 Tower kernel: mdcmd (90): spindown 14 Mar 13 21:40:28 Tower kernel: mdcmd (91): spindown 15 Mar 13 21:40:28 Tower kernel: mdcmd (92): spindown 16 Mar 13 21:40:29 Tower emhttp: shcmd (7073): /usr/sbin/hdparm -y /dev/sdc &> /dev/null
Thanks
Myk
I am receiving these as well when all disks are spun down
Same here.. loads of them..
I am having the same issue. What type of drive controller card are you using here?
-
Had this docker working without a problem for some time. Remote access worked a treat. Since updating earlier today to the new container, remote access hasn't worked (confirmed by friends outside my network), and on restart the remote access tab will not connect. Server's connection hasn't changed - only change was the update to the Plex container.
Anything changed? Settings I need to update? Variables I'm using:
PUID: 99
PGID: 100
VERSION: plexpass
Thanks!
Edited to add: Restarted a few more times and the remote access connects. Friends can see contents of my server, browse, etc. But nothing plays outside the network. I added a /transcode path in case that had anything to do with it, but didn't seem to help.
Having the same issue. I can post the plex log, but I believe this is where things are going wrong.
Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - Starting a transcode session 3g2tn2irlh4zpvi at offset -1.0 (stopped=1) Sep 24, 2015 22:31:54 [0x2ba506401700] WARN - WARNING: Couldn't create directory /transcode/plex-transcode-3g2tn2irlh4zpvi-129a71fa-dbd9-4b49-b729-af719709f128 Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - [universal] Using local file path instead of URL: /media/TV/Scandal (2012)/Season 5/Scandal.(2012).S05E01.Heavy Is the Head.HDTV-720p.mkv Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - Job running: XDG_CACHE_HOME='/config/Library/Application Support/Plex Media Server/Cache/' XDG_DATA_HOME='/usr/lib/plexmediaserver/Resources/' '/usr/lib/plexmediaserver/Resources/Plex New Transcoder' '-noaccurate_seek' '-i' '/media/TV/Scandal (2012)/Season 5/Scandal.(2012).S05E01.Heavy Is the Head.HDTV-720p.mkv' '-map' '0:0' '-codec:0' 'copy' '-bsf:0' 'h264_mp4toannexb,h264_plex' '-map' '0:1' '-codec:1' 'aac' '-strict:1' 'experimental' '-cutoff:1' '15000' '-channel_layout:1' 'stereo' '-b:1' '258k' '-f' 'matroska' '-avoid_negative_ts' 'disabled' '-map_metadata' '-1' '-' '-start_at_zero' '-copyts' '-y' '-nostats' '-loglevel' 'quiet' '-loglevel_plex' 'error' '-progressurl' 'http://127.0.0.1:32400/video/:/transcode/session/3g2tn2irlh4zpvi/progress'
Thanks for this, would jump on to our IRC Channel to help out with debugging this ?
Just wanted to report that the update from last night has resolved the transcoding issue. Playback is working properly now.
Thanks!
-
Had this docker working without a problem for some time. Remote access worked a treat. Since updating earlier today to the new container, remote access hasn't worked (confirmed by friends outside my network), and on restart the remote access tab will not connect. Server's connection hasn't changed - only change was the update to the Plex container.
Anything changed? Settings I need to update? Variables I'm using:
PUID: 99
PGID: 100
VERSION: plexpass
Thanks!
Edited to add: Restarted a few more times and the remote access connects. Friends can see contents of my server, browse, etc. But nothing plays outside the network. I added a /transcode path in case that had anything to do with it, but didn't seem to help.
Having the same issue. I can post the plex log, but I believe this is where things are going wrong.
Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - Starting a transcode session 3g2tn2irlh4zpvi at offset -1.0 (stopped=1) Sep 24, 2015 22:31:54 [0x2ba506401700] WARN - WARNING: Couldn't create directory /transcode/plex-transcode-3g2tn2irlh4zpvi-129a71fa-dbd9-4b49-b729-af719709f128 Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - [universal] Using local file path instead of URL: /media/TV/Scandal (2012)/Season 5/Scandal.(2012).S05E01.Heavy Is the Head.HDTV-720p.mkv Sep 24, 2015 22:31:54 [0x2ba506401700] DEBUG - Job running: XDG_CACHE_HOME='/config/Library/Application Support/Plex Media Server/Cache/' XDG_DATA_HOME='/usr/lib/plexmediaserver/Resources/' '/usr/lib/plexmediaserver/Resources/Plex New Transcoder' '-noaccurate_seek' '-i' '/media/TV/Scandal (2012)/Season 5/Scandal.(2012).S05E01.Heavy Is the Head.HDTV-720p.mkv' '-map' '0:0' '-codec:0' 'copy' '-bsf:0' 'h264_mp4toannexb,h264_plex' '-map' '0:1' '-codec:1' 'aac' '-strict:1' 'experimental' '-cutoff:1' '15000' '-channel_layout:1' 'stereo' '-b:1' '258k' '-f' 'matroska' '-avoid_negative_ts' 'disabled' '-map_metadata' '-1' '-' '-start_at_zero' '-copyts' '-y' '-nostats' '-loglevel' 'quiet' '-loglevel_plex' 'error' '-progressurl' 'http://127.0.0.1:32400/video/:/transcode/session/3g2tn2irlh4zpvi/progress'
-
So, I am using this docker to move data off an old 1.5tb drive that I will decommission.
Previously, I have followed this post to move data, zero out the drive, and then remove the disk from the config.
http://lime-technology.com/forum/index.php?topic=37431.0
My question is this: If I move the data off this old drive and spread out to the rest of the array, would I still need to zero out the drive when the data is moved? Using this docker is updating parity, correct? If so, once the copy is done can I just follow the usual steps to remove the disk from my config?
Thanks!
-
Yea... only change it on the docker WebGUI interface.
Basically docker is doing magic for you. The container is perfectly working on port 8085 and the docker software handles translating between what port you put and the port its actually running on.
Thanks for the assistance. Hopefully I was able to help test out the new build for you


provisioning myserver plugin never responds
in Connect Plugin Support
Posted
I just tried it again this morning and the provisioning completed successfully. Thanks for the update!