


KuniD
-
Posts
60 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by KuniD
-
-
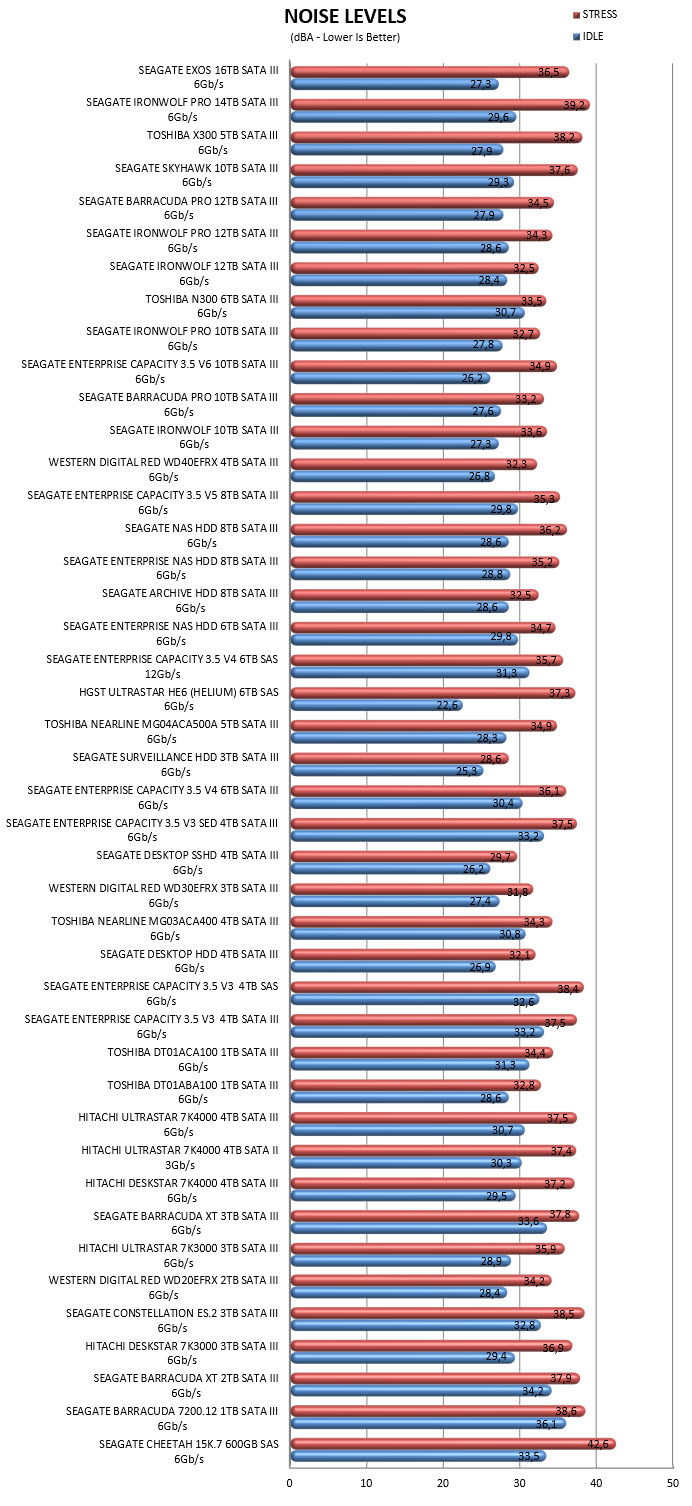
So I've been operating 6 x Seagate Archive 8Tb drives for the last 6 or so years. For the most part they're still ticking along although the first has just failed (awful whirring sound), so I'm looking to replace the drive.
I'm thinking now is a sensible time to start slowly transitioning the setup to larger volume drives, so will be starting with a parity swap out.
While I was initially focused on the Seagate Ironwolf Pro and Western Digital Red Pro lineups, I noticed the Seagate EXOS X16 16Tb is on Amazon for a rather surreal £262;
https://www.amazon.co.uk/Seagate-ST16000NM001G-EXOS-X16-Internal/dp/B07SPFPKF4/
Considering most the Ironwolf Pro and Red Pro 16Tb drives are £400-500 this seems like quite a bargain.
My Unraid box (in a Fractal Design R5 case) is on the floor next to my desk. I have lived with the whir of the 6x Seagate Archive 8Tb drives without complaint, but am worried that these enterprise/data centre drives may be a lot louder.
I can see a lot of comments only saying their very loud, on the other hand I came across this article (see bottom of page) which seems to suggest in a comparison that they're not too bad;
Does anyone have any experience of these drives in close proximity regular use?
Only other thing putting me off the Amazon link is that it mentions its an OEM drive / US sourced and the reviews seem to indicate Seagate won't honour the warranty. I suppose its a trade off on that much storage per £ vs much higher with a warranty.
-
ok thanks !
-
Hi all,
After 5 years of running my unraid box I'm pretty sure I'm encountering my first drive failure (I can hear the drive struggling lol).
Before I power things down, etc, I thought I'd pull the diagnostics and share here for any insights - have to admit I'm not very good at deciphering these !
Essentially I woke this morning to hear a new sound (a louder whirring sound, like a fan failing), and saw unraid had a "Disk 4 in error state" message. The drive has been disabled and I can't access any of the SMART reports, but I'm guessing if I can hear it its a lost cause.
I have some questions regarding replacing the drive and rebuilding the array (apologies they are likely to be super basic/obvious, just never been through this process before). Right now I have 6x Seagate 8Tb drives, 1 parity, 5 storage. Firstly, I presume I can remove the failed drive for now, then when I receive a replacement drive the array will rebuild? Secondly, as 5 years has elapsed since building this setup, I want to get a larger drive (Ironwolf Pro 12Tb), so presume I'll need to follow this process (https://wiki.unraid.net/The_parity_swap_procedure) and make the 12tb drive the new parity? I'm a bit confused on whether the failed drive also needs to be present but disabled in this scenario, or unplugged and removed is ok
Appreciate any advice and thanks in advance
-
Selling a brand new, in box/unopened AMD Ryzen 5900X 12 Core / 24 thread processor. It's excess to needs as I have gone with a 5950X instead and only purchased this stupidly in a mad fit to secure a chip.
£490 including next day delivery with DPD. If delivered bank transfer preferred or cash on collection (London, willing to meet half way within reason)
UK only
-
On 12/18/2020 at 12:39 AM, jonathanm said:
Easy first test, use a plain surge protector instead of the UPS and see how it behaves.
Gut feeling says PSU, since normally PSU's can handle a remarkable amount of input voltage fluctuation without sagging the output, at least if they are running with a decent amount of reserve overhead. To have a system be that touchy leads me to think that the PSU or the motherboard power circuits are misbehaving. There is a decent amount of smoothing and filtering done on the motherboard as well, so that's a possible candidate besides the UPS and PSU.
On 12/18/2020 at 11:21 AM, Ford Prefect said:...during spin-up, the load for these HDDS can easily double up-to triple that amount.
But that still would leave you under the max margin of your PSU.
How old is the PSU (as they can deteriorate over time and loose approx 10% of their nominal maximum).
Confirm that P4/P8/EPS power sockets are still well connected to the MB and GPUs.
Thank you both - following your replies I decided to get more organised and wrote up a series of elimination tests to isolate what the problem was. In the end I confirmed it was indeed the PSU. I ruled out GPU's ,cabling, CMOS battery, UPS v mains, etc. I borrowed an old Antec PSU from a friend and it ran the system fine without issue.
If you can believe it I had 8 days left on my 5 year warranty from Super Flower. I have RMA'd it and am awaiting a replacement.
-
Hi all, would appreciate your input on the following problem.
I have been having hardware stability issues for a while and am struggling to pin down the cause. The issues usually materialise as:
1) Random reboots
2) Random reboots, that then get stuck in a constant cycle of trying to power on but failing to do so besides a brief flicker of fans/lights. I need to either (a) trip my UPS to battery mode (turning off then on wall switch) or (b) kill the switch on the PSU for a minute or so then turn back on to stop this.
3) Reboot triggered by loading a game in Windows bare metal (i.e. Star Wars Squadrons)
4) In some Windows 10 VM's I have noticed screen artefacts
On the last point this could be a software issue as it only happens in Windows 10 VM's, not bare metal or MacOS / PopOS VMs.
On point 3 I have removed my GTX 970, but still experienced random reboots running on just a GT 710.
I have also left Memtest running in the past without issue.
I thought I'd also test how my server behaves when I turn the wall socket off for my UPS. Even though doing so leads to my UPS going into battery mode, it still triggers a reboot of the server. This surprised me as my UPS is a 1500VA line interactive / pure sine wave, with nothing else connected to it besides the server.
I'm thinking the issue may be either the UPS or my PSU. I'm wondering whether I have a config issue on the UPS or if I'm overloading my PSU / have a faulty PSU. I have put my specs below, including a rough calculation for power usage
UPS: APC Spart-UPS 1500VA (SMT1500IC)
PSU: Superflower Leadex 80 Plus Platinum 750w
Motherboard: Asus X99-Deluxe (?w)
CPU: Intel Xeon E5-2678v3 (12C/24T @ 2.5GHz, 120w TDP)
RAM: 8x 8Gb Hynix DDR-2133 ECC (5w per stick?)
GPU 1: Asus GTX 970 STRIX OC 4Gb (148w TDP)
GPU 2: Asus GT 710 2Gb (19w TDP)
NVMe: 2x Samsung Evo 970 1Tb (one via PCIE add in board. 5w under load each?)
SATA: 6x Seagate Archive 8Tb (ST8000AS0002, 7.5w at load each), 1x Samsung 850 1Tb (5w?)
Fans: 4x 140mm fans (4w each?)
USB devices: Logitech webcam, Jabra conference mic, sometimes an iPhone, Bluetooth dongle, sometimes recharging keyboard
Estimating 400-450w load? Would have thought a 750w platinum PSU from Superflower should be able to handle this.
-
On 12/6/2020 at 5:19 PM, david279 said:
@KuniD You can do this in recovery in catalina using disk utility. Use the restore button on your NVME disk in recovery and just select your current start up drive and it will copy everything over. This does not work in Big Sur due to all sorts of changes, I had to use CCC to do it in Big Sur.
Hi David,
Following Spaceinvader One's new Big Sur video I have just set up a new VM. Would you mind sharing the steps you took using CCC to migrate Big Sur to the NVMe? Thanks
-
20 minutes ago, david279 said:
Just Catalina disk should work.
Superfast -all done! Thanks !
-
3 hours ago, david279 said:
@KuniD You can do this in recovery in catalina using disk utility. Use the restore button on your NVME disk in recovery and just select your current start up drive and it will copy everything over. This does not work in Big Sur due to all sorts of changes, I had to use CCC to do it in Big Sur.
thanks, will give the recovery method a try.
Should I select the “Catalina” disk or “Catalina - Data”?
-
Hi all,
I have setup a Catalina VM, using a vdisk with GPU and USB passthrough. I now want to migrate the vdisk boot drive to use a 1Tb NVMe. I have successfully passed through the controller and can see the drive available within MacOS.
Where I am lost is what I need to do next; what needs to be setup, cloned, reconfigured, etc. I may be being blind but having had a search here and on Google I haven't come across any guidance for migrating an existing MacOS vdisk
Any guidance would be appreciated!
-
1 hour ago, mSedek said:
Please post your xml
<?xml version='1.0' encoding='UTF-8'?> <domain type='kvm'> <name>MacinaboxHighSierra</name> <uuid></uuid> <description>MacOS High Sierra</description> <metadata> <vmtemplate xmlns="unraid" name="Windows 10" icon="default.png" os="HighSierra"/> </metadata> <memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>8</vcpu> <cputune> <vcpupin vcpu='0' cpuset='0'/> <vcpupin vcpu='1' cpuset='12'/> <vcpupin vcpu='2' cpuset='1'/> <vcpupin vcpu='3' cpuset='13'/> <vcpupin vcpu='4' cpuset='2'/> <vcpupin vcpu='5' cpuset='14'/> <vcpupin vcpu='6' cpuset='3'/> <vcpupin vcpu='7' cpuset='15'/> </cputune> <os> <type arch='x86_64' machine='pc-q35-3.1'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd</loader> <nvram>/etc/libvirt/qemu/nvram/d1862346-b4b2-4398-b17c-f6e6a82a023a_VARS-pure-efi.fd</nvram> </os> <features> <acpi/> <apic/> </features> <cpu mode='host-passthrough' check='none'> <topology sockets='1' cores='4' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='utc'> <timer name='rtc' tickpolicy='catchup'/> <timer name='pit' tickpolicy='delay'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='writeback'/> <source file='/mnt/user/domains/MacinaboxHighSierra/Clover.qcow2'/> <target dev='hdc' bus='sata'/> <boot order='1'/> <address type='drive' controller='0' bus='0' target='0' unit='2'/> </disk> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/MacinaboxHighSierra/HighSierra-install.img'/> <target dev='hdd' bus='sata'/> <address type='drive' controller='0' bus='0' target='0' unit='3'/> </disk> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/domains/MacinaboxHighSierra/macos_disk.img'/> <target dev='hde' bus='sata'/> <address type='drive' controller='0' bus='0' target='0' unit='4'/> </disk> <controller type='pci' index='0' model='pcie-root'/> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x8'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x9'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0xb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x3'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0x13'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0xa'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/> </controller> <controller type='pci' index='6' model='pcie-to-pci-bridge'> <model name='pcie-pci-bridge'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </controller> <controller type='virtio-serial' index='0'> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <controller type='sata' index='0'> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='usb' index='0' model='ich9-ehci1'> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <interface type='bridge'> <mac address='52:54:00:14:a8:f6'/> <source bridge='br0'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> </serial> <console type='pty'> <target type='serial' port='0'/> </console> <channel type='unix'> <target type='virtio' name='org.qemu.guest_agent.0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <address type='usb' bus='0' port='1'/> </input> <input type='mouse' bus='ps2'/> <input type='keyboard' bus='ps2'/> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0' multifunction='on'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x1'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x0b05'/> <product id='0x180a'/> </source> <address type='usb' bus='0' port='2'/> </hostdev> <memballoon model='none'/> </devices> </domain>
-
Thanks for this great docker and guide. First time setting up a VM so please excuse the basic questions;
i have setup a High Sierra VM as I have a Nvidia GTX970, but can I pass this through if I only have the one GPU? I have followed the guidance from one of your other videos on adding the associates sound card and changing the XML to mention multifunction. When I start the VM from the servers GUI I get a black screen. Appreciate I have taken the GPU away from Unraid but was expecting MacOS to appear. Any tips or guidance appreciated
-
Ok I have ordered a multimeter, will check voltage at wall and from output of UPS and report back.
-
On 2/5/2020 at 11:18 PM, Benson said:
251v should trigger the high threshold voltage transfer, I suppose it is typo.
When interactive type UPS not on battery, it equivalent direct connect to mains.
Pls try, one by one
- disconnect the USB cable between Unraid and UPS.
- disconnect mains on UPS, does server success boot if power by UPS.
Further update, relates to your second suggestion:
I tried to boot the server up again with power connected via the UPS this evening and it successfully booted.
I checked the screen on the APC at this time and it was showing input and output voltage at 249.
Everything was operating as expected for about 7hrs, when I noticed I could no longer remote into the server. I went to take a look and found that the monitor was off and keyboard/mouse didn't wake the system, but server was on with no activity lights flashing. The screen on the APC now read input 249v, output 221v.
I turned off the mains power socket leading to the APC, forcing it into battery mode. As soon as I did that the server came back to life and the monitor came on, showing that the system was rebooting, post/bios screen etc
not sure if the output voltage dropping is an indicator of a problem or if the problem is setup elsewhere
-
Hi Benson,
Not a typo, here's a photo from the front of the UPS:
If the input being 251v is causing the issue, and the UPS is acting as a pass through when not on battery, what's confusing me is that the server boots as expected when directly connected to the same mains socket that is feeding the UPS.
Thanks for your suggestions, I have tried disconnecting the USB between UPS and Unraid, no change.
I'll try your second suggestion later today.
-
Hi all, hoping someone can help. I purchased an APC Smart-UPS (SMT1500IC), to help my Unraid server shutdown safely in an outage.
First time using a UPS, I followed the basic setup steps as described in the box, but I’m seeing some really strange behaviour. The server is the only device connected to the UPS.
I booted the server up and entered the Bios. I was about to select the boot device manually when the server suddenly died and then kept trying to turn on and off in a loop constantly. I had to kill the switch on the PSU to stop the loop.
After flicking the PSU back on I tried to turn it back on but no joy, so I unplugged the power cable coming from the PSU and reconnected a standard power cable from the mains socket. This time the server POSTed, although it showed a "Chassis Intrude! Please Check Your System Fatal Error" message.
I powered down and reconnected the power cable coming from the UPS. This time the server would power up (I can hear the drives spinning up), but the activity light didn’t flash nor did the POST screen appear.
I powered down and swapped to mains power, at which point it boots up as expected.
I’m probably missing something obvious, but something clearly isn’t sitting right between my PSU and the UPS. Any guidance anyone could give would be appreciated !
PSU: SuperFlower Leadex Titanium 750w
UPS: APC Smart-UPS SMT1500IC (showing input 251v, output 223v)
-
Will give it a go

-
So I'm planning to test the Unifi Network Video Recorder Docker.
The cameras will be Unifi G3's, which have a 4mpixel sensor / max 1080p @ 30fps. I'll probably experiment with recording motion only vs 24/7 and reduced fps (10?).
What about if I use an SSD cache (potentially give it its own 1tb cache drive) then write to the SMR drive at the usual time overnight? As I'm not recording constantly perhaps this would put less strain on the config?
Can't imagine playback would be an issue from the SMR drives as they clearly handle Plex, etc well
-
I have 6 of these setup in a 40tb array with a single parity.
I'm looking to setup 2-3 IP cameras for home security, does anyone see an issue with using the SMR drives and unRAID in general for an NVR use case?
-
Drive number 6...
================================================================== 1.15b = unRAID server Pre-Clear disk /dev/sdg = cycle 3 of 3, partition start on sector 1 = = Step 1 of 10 - Copying zeros to first 2048k bytes DONE = Step 2 of 10 - Copying zeros to remainder of disk to clear it DONE = Step 3 of 10 - Disk is now cleared from MBR onward. DONE = Step 4 of 10 - Clearing MBR bytes for partition 2,3 & 4 DONE = Step 5 of 10 - Clearing MBR code area DONE = Step 6 of 10 - Setting MBR signature bytes DONE = Step 7 of 10 - Setting partition 1 to precleared state DONE = Step 8 of 10 - Notifying kernel we changed the partitioning DONE = Step 9 of 10 - Creating the /dev/disk/by* entries DONE = Step 10 of 10 - Verifying if the MBR is cleared. DONE = Disk Post-Clear-Read completed DONE Disk Temperature: 31C, Elapsed Time: 139:47:27 ========================================================================1.15b == ST8000AS0002-1NA17Z XXXXXXXX == Disk /dev/sdg has been successfully precleared == with a starting sector of 1 ============================================================================ ** Changed attributes in files: /tmp/smart_start_sdg /tmp/smart_finish_sdg ATTRIBUTE NEW_VAL OLD_VAL FAILURE_THRESHOLD STATUS RAW_VALUE Raw_Read_Error_Rate = 102 117 6 ok 3736704 Seek_Error_Rate = 76 64 30 ok 42251182 Spin_Retry_Count = 100 100 97 near_thresh 0 End-to-End_Error = 100 100 99 near_thresh 0 Airflow_Temperature_Cel = 69 75 45 In_the_past 31 Temperature_Celsius = 31 25 0 ok 31 Hardware_ECC_Recovered = 102 117 0 ok 3736704 No SMART attributes are FAILING_NOW 0 sectors were pending re-allocation before the start of the preclear. 0 sectors were pending re-allocation after pre-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 1 of 3. 0 sectors were pending re-allocation after post-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 2 of 3. 0 sectors were pending re-allocation after post-read in cycle 2 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 3 of 3. 0 sectors are pending re-allocation at the end of the preclear, the number of sectors pending re-allocation did not change. 0 sectors had been re-allocated before the start of the preclear. 0 sectors are re-allocated at the end of the preclear, the number of sectors re-allocated did not change.
And long SMART results
=== START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED See vendor-specific Attribute list for marginal Attributes. General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 0) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 1) minutes. Extended self-test routine recommended polling time: ( 961) minutes. Conveyance self-test routine recommended polling time: ( 2) minutes. SCT capabilities: (0x30a5) SCT Status supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 119 099 006 Pre-fail Always - 205822928 3 Spin_Up_Time 0x0003 092 092 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 9 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 076 060 030 Pre-fail Always - 47334209 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 371 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 9 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 071 043 045 Old_age Always In_the_past 29 (0 10 32 23 0) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 5 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 461 194 Temperature_Celsius 0x0022 029 057 000 Old_age Always - 29 (0 9 0 0 0) 195 Hardware_ECC_Recovered 0x001a 119 099 000 Old_age Always - 205822928 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 1795296329978 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 58085129483 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 64307117065 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 355 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
If all is well this'll take me to 40Tb parity protected, think I'll pause at this point ;-)
-
LAN_NETWORK is the CIDR notation of the ip range you are using. So for instance, if your home network is 192.168.0.0 to 192.168.0.8 (or whatever), you will put 192.168.0.0 followed by the subnet. So in the end, you would end up with something like 192.168.0.0/24 (assuming your subnet is 255.255.255.0), and that is what you would put in for LAN_NETWORK. Your gateway address is most probably on 192.168.0.1 (something like that), so you don't use that.
Thanks Jimmy, that did the trick.
-
Hi all, I'm not having a lot of luck getting the WebGUI to load (getting ERR_CONNECTION_TIMED_OUT), sure I'm doing something very obvious incorrectly.
I installed the docker and set config to:
/mnt/cache/appdata/
And data to:
/mnt/user/downloads/
I set my PIA username and password and set VPN_PROV to pia, besides that left everything else as default. I'm unsure what LAN_NETWORK should be pointing to, should it be my default gateway?
I have uninstalled/reinstalled the docker, cleared my appdata directory completely, in case something was clogging it up, not sure if I have mis configured or something is blocking it. I haven't made any changes to my router.
What's the best way for me to debug? Have to admit I'm still grappling with the basics here with unRAID and Linux!
-
Archive drive no. 4 (sdf) pre-clear results:
================================================================== 1.15b = unRAID server Pre-Clear disk /dev/sdf = cycle 3 of 3, partition start on sector 1 = = Step 1 of 10 - Copying zeros to first 2048k bytes DONE = Step 2 of 10 - Copying zeros to remainder of disk to clear it DONE = Step 3 of 10 - Disk is now cleared from MBR onward. DONE = Step 4 of 10 - Clearing MBR bytes for partition 2,3 & 4 DONE = Step 5 of 10 - Clearing MBR code area DONE = Step 6 of 10 - Setting MBR signature bytes DONE = Step 7 of 10 - Setting partition 1 to precleared state DONE = Step 8 of 10 - Notifying kernel we changed the partitioning DONE = Step 9 of 10 - Creating the /dev/disk/by* entries DONE = Step 10 of 10 - Verifying if the MBR is cleared. DONE = Disk Post-Clear-Read completed DONE Disk Temperature: 29C, Elapsed Time: 134:20:09 ========================================================================1.15b == ST8000AS0002-XXXXX XXXXXXXXX == Disk /dev/sdf has been successfully precleared == with a starting sector of 1 ============================================================================ ** Changed attributes in files: /tmp/smart_start_sdf /tmp/smart_finish_sdf ATTRIBUTE NEW_VAL OLD_VAL FAILURE_THRESHOLD STATUS RAW_VALUE Raw_Read_Error_Rate = 118 119 6 ok 201104656 Seek_Error_Rate = 78 76 30 ok 81325946 Spin_Retry_Count = 100 100 97 near_thresh 0 End-to-End_Error = 100 100 99 near_thresh 0 Airflow_Temperature_Cel = 71 72 45 ok 29 Temperature_Celsius = 29 28 0 ok 29 Hardware_ECC_Recovered = 118 119 0 ok 201104656 No SMART attributes are FAILING_NOW 0 sectors were pending re-allocation before the start of the preclear. 0 sectors were pending re-allocation after pre-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 1 of 3. 0 sectors were pending re-allocation after post-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 2 of 3. 0 sectors were pending re-allocation after post-read in cycle 2 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 3 of 3. 0 sectors are pending re-allocation at the end of the preclear, the number of sectors pending re-allocation did not change. 0 sectors had been re-allocated before the start of the preclear. 0 sectors are re-allocated at the end of the preclear, the number of sectors re-allocated did not change.
Here's the long SMART result for the above drive
=== START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 0) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 1) minutes. Extended self-test routine recommended polling time: ( 951) minutes. Conveyance self-test routine recommended polling time: ( 2) minutes. SCT capabilities: (0x30a5) SCT Status supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 117 099 006 Pre-fail Always - 144272752 3 Spin_Up_Time 0x0003 090 090 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 13 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 079 060 030 Pre-fail Always - 86332858 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 860 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 13 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 072 063 045 Old_age Always - 28 (Min/Max 21/32) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 17 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 50 194 Temperature_Celsius 0x0022 028 040 000 Old_age Always - 28 (0 21 0 0 0) 195 Hardware_ECC_Recovered 0x001a 117 099 000 Old_age Always - 144272752 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 66743791780146 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 93768319256 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 128604004367 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 856 - # 2 Extended offline Completed without error 00% 543 - # 3 Extended offline Aborted by host 90% 528 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
Archive drive no. 5 (sdf) pre-clear results:
================================================================== 1.15b = unRAID server Pre-Clear disk /dev/sdg = cycle 3 of 3, partition start on sector 1 = = Step 1 of 10 - Copying zeros to first 2048k bytes DONE = Step 2 of 10 - Copying zeros to remainder of disk to clear it DONE = Step 3 of 10 - Disk is now cleared from MBR onward. DONE = Step 4 of 10 - Clearing MBR bytes for partition 2,3 & 4 DONE = Step 5 of 10 - Clearing MBR code area DONE = Step 6 of 10 - Setting MBR signature bytes DONE = Step 7 of 10 - Setting partition 1 to precleared state DONE = Step 8 of 10 - Notifying kernel we changed the partitioning DONE = Step 9 of 10 - Creating the /dev/disk/by* entries DONE = Step 10 of 10 - Verifying if the MBR is cleared. DONE = Disk Post-Clear-Read completed DONE Disk Temperature: 33C, Elapsed Time: 135:32:29 ========================================================================1.15b == ST8000AS0002-XXXXX XXXXXXXXX == Disk /dev/sdg has been successfully precleared == with a starting sector of 1 ============================================================================ ** Changed attributes in files: /tmp/smart_start_sdg /tmp/smart_finish_sdg ATTRIBUTE NEW_VAL OLD_VAL FAILURE_THRESHOLD STATUS RAW_VALUE Raw_Read_Error_Rate = 103 100 6 ok 5306480 Seek_Error_Rate = 75 100 30 ok 38391244 Spin_Retry_Count = 100 100 97 near_thresh 0 End-to-End_Error = 100 100 99 near_thresh 0 Airflow_Temperature_Cel = 67 70 45 near_thresh 33 Temperature_Celsius = 33 30 0 ok 33 Hardware_ECC_Recovered = 103 100 0 ok 5306480 No SMART attributes are FAILING_NOW 0 sectors were pending re-allocation before the start of the preclear. 0 sectors were pending re-allocation after pre-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 1 of 3. 0 sectors were pending re-allocation after post-read in cycle 1 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 2 of 3. 0 sectors were pending re-allocation after post-read in cycle 2 of 3. 0 sectors were pending re-allocation after zero of disk in cycle 3 of 3. 0 sectors are pending re-allocation at the end of the preclear, the number of sectors pending re-allocation did not change. 0 sectors had been re-allocated before the start of the preclear. 0 sectors are re-allocated at the end of the preclear, the number of sectors re-allocated did not change.
Here's the long SMART result for the above drive
SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: ( 0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: ( 0) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: ( 1) minutes. Extended self-test routine recommended polling time: ( 957) minutes. Conveyance self-test routine recommended polling time: ( 2) minutes. SCT capabilities: (0x30a5) SCT Status supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 119 099 006 Pre-fail Always - 202585176 3 Spin_Up_Time 0x0003 099 099 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 1 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 076 060 030 Pre-fail Always - 43445070 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 163 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 1 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 069 065 045 Old_age Always - 31 (Min/Max 22/35) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 4 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 29 194 Temperature_Celsius 0x0022 031 040 000 Old_age Always - 31 (0 22 0 0 0) 195 Hardware_ECC_Recovered 0x001a 119 099 000 Old_age Always - 202585176 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 96052648607899 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 46884159680 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 64301985610 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 159 - SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
Just about to start pre-clear on drive number 6...
-
... This'll be 8Tb Archive drive no 6!
Have you seen Daniel's mod to the R5 that allows you to install 18 drives?
... only 12 more 8TB drives to go to fill it up
Just read up on it, wow who knew you could cram that many in ;-)
Unfortunately I've got a huge tower cooler on my Xeon, so I won't able to hang any off the top.
Additional four at the bottom could happen though... !
Preclear (pre-read) drive sounds like a clock ticking
in Storage Devices and Controllers
Posted · Edited by KuniD
I'm preparing for a parity swap, so I've begun by running preclear on a new Western Digital Red Pro 16Tb drive.
It is currently 70% the way through the first pre-read phase (15 hours to this point overnight). I noticed the drive seems to be making a ticking noise once a second, almost like a wall clock ticking. I've read that WD drives can tick every 5 seconds but wasn't sure if this was the same thing. I ran a SMART test prior to starting the preclear and nothing came up during that step. Not sure if I'm over reacting.. !
Thanks