

DTMHibbert
-
Posts
34 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by DTMHibbert
-
-
On 4/7/2023 at 1:19 PM, Emneth Design said:
Many thanks - if it works that should help quite a few folk.
Did this work? im suffering from really slow performance as well - browsing smb shares is horrific and im sure transferring files has taken a hit to. - maybe since i updated to 6.12 rc 1/2/3
-
i had CA backup and Restore start at 5am - but have since removed it due to it not being supported on 6.12 RC2 ... could this have been the cause?
-
No - been up and running for a few years now adding disks as i go
-
Great so will that fix whatever was wrong?
Also in the system log looking closer at the errors it seems the other drives are being reported too (see below)
Mar 26 05:01:12 Zeus kernel: XFS (md2p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md3p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md4p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md5p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md6p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md7p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md8p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1 Mar 26 05:01:12 Zeus kernel: XFS (md9p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 26 05:01:12 Zeus kernel: CPU: 0 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1The only thing changing it seems is the (md"x"p1) - so im assuming i just run the previous command on all reported disks?
Any idea why whatever has happened, happened?
Thanks
-
ok that the command worked with /dev/md1p1 and it spit out the following
root@Zeus:~# xfs_repair -v /dev/md1p1 Phase 1 - find and verify superblock... - block cache size set to 1886968 entries Phase 2 - using internal log - zero log... zero_log: head block 1216181 tail block 1216181 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... XFS_REPAIR Summary Mon Apr 3 16:03:09 2023 Phase Start End Duration Phase 1: 04/03 16:03:08 04/03 16:03:08 Phase 2: 04/03 16:03:08 04/03 16:03:09 1 second Phase 3: 04/03 16:03:09 04/03 16:03:09 Phase 4: 04/03 16:03:09 04/03 16:03:09 Phase 5: 04/03 16:03:09 04/03 16:03:09 Phase 6: 04/03 16:03:09 04/03 16:03:09 Phase 7: 04/03 16:03:09 04/03 16:03:09 Total run time: 1 second doneWhat next?
Thanks for your help as well
-
This is what im getting as a result
xfs_repair -v /dev/md1 /dev/md1: No such file or directory /dev/md1: No such file or directory fatal error -- couldn't initialize XFS libraryAnything else i can do?
What has actually happened? is there anything i have done wrong, something bad with the drive?
Sorry for all the questions just trying to understand.
Thanks -
HI All,
So im seeing some potentially worry error in the syslog. Today, i randomly ran a Fix Common Problems which alerted me to the fact that my syslog was at 100% hadnt noticed before hand and the server seems to running perfectly fine. I checked the log and im seeing the following errors;
Mar 25 05:01:13 Zeus kernel: XFS (md1p1): Internal error xfs_acl_from_disk at line 43 of file fs/xfs/xfs_acl.c. Caller xfs_get_acl+0x125/0x169 [xfs] Mar 25 05:01:13 Zeus kernel: CPU: 5 PID: 18676 Comm: shfs Not tainted 6.1.20-Unraid #1These errors seems to occur every day at the same time give or take a few seconds (5am in the morning) - This is roughly the time i had the plugin CA Backup and Restore to start its daily backup. Which i have since noticed that is now deprecated so i have of course removed this from my system. Could that be the culprit for these errors?
Ultimatley do i have anything to worry about? I have looked up the error on google which points me to a bunch of articles about running checks/ scans in maintance mode?
I'll restart the server soon but currently just finishing a parity scan. I have attached the diagnotics as well in case that helps.
Thanks All
")
-
2 hours ago, JorgeB said:
Feb 23 17:09:11 Zeus root: Installing atop-2.2 package...Try uninstalling this, it's a known issue.
Will give this a shot and see how it runs, thanks
-
HI All,
Hoping for some help, recently i've noticed that my Log file is filling up and reaching 100% - which then in turn essentially crashes the system im not able to reach the dashboard or any dockers.
Currently i have a reminder set for every 15 days to perform a clean restart of the Server but i obviously don't want to do this forever.
Can someone take a look through my diagnostics files and see if they can spot anything which might be causing this.
Thanks
")
-
On 1/27/2022 at 4:27 PM, willnnotdan said:
@BigWebstas @DTMHibbertis there anything in your Unraid Server logs? Are you able to control VMs? Has it ever worked?
Nope, nothing in the docker logs or system logs of Unraid. i have never had this work. i had it installed a while back it didn't work so i uninstalled it, trying again now but still cannot get it to work. - Just doesn't respond to stopping/ starting dockers/ VM's
-
On 12/24/2021 at 8:28 AM, BigWebstas said:
I cant get the webui to toggle any of the docker containers or vms nothing shows up in the log unless i try to toggle them via mqtt
> [email protected] start > cross-env NUXT_HOST=0.0.0.0 NODE_ENV=production node server/index.js WARN mode option is deprecated. You can safely remove it from nuxt.config Connected to mqtt broker READY Server listening on http://0.0.0.0:80 Received MQTT Topic: homeassistant/zuse/binhex-prowlarr/dockerState and Message: stopped assigning ID: MQTT-R-kxk4ov41 Part of MQTT-R-kxk4ov41 failed.
I am running Version: 6.10.0-rc2, is there another spot for log details other than just clicking on the container and selecting log?
I'm also struggling from the same error, whenever i try to turn off/on a docker container from either webUI or homeassistant.
-
Sorry, what i mean is when i look at the log file, from the unraid dashboard (picture attached) there is no time/ date of when specific actions took place.
In the image attached there is an error highlighted in red - it would useful to see what time/ date this was so i could narrow down what possibly caused it.
it would be also helpful to see when certain files were started uploading to see how long they took to upload.
Thanks
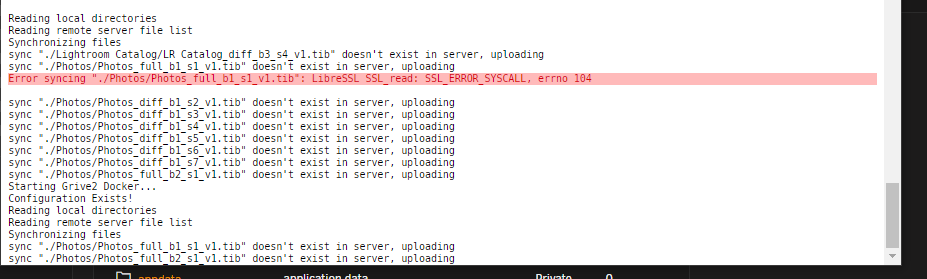
-
Is it possible to include date and time is the logs for this?
-
Yesterday i recieved a notification during a parity check that Disk 5 had 22 read errors. The pariety check completed without any errors however.
i have since ran Extended Smart tests on all drives and all pass without errors. However last night i recieved a notification to say the health of my array failed due to read errors on Disk 5.
How serious is this? I have attached my diagnostics file, if anyone could help that would be great.
-
Not sure if i found anything of great importance but ive been digging around the diagnotics download and if i look in the share folder at the effected shares where this behaivor is happening the .cfg file just contains
# This share has default settings. # Share exists on cache,disk1,2,3,4,5,6,7where by if i look at shares that arent effected by this behaivor they look more like config files... for example
# Generated settings: shareComment="..." shareInclude="" shareExclude="" shareUseCache="yes" shareCOW="auto" shareAllocator="highwater" shareSplitLevel="" shareFloor="0" shareExport="e" shareFruit="no" shareCaseSensitive="auto" shareSecurity="public" shareReadList="" shareWriteList="" shareVolsizelimit="" shareExportNFS="-" shareExportNFSFsid="0" shareSecurityNFS="public" shareHostListNFS="" shareExportAFP="-" shareSecurityAFP="public" shareReadListAFP="" shareWriteListAFP="" shareVolsizelimitAFP="" shareVoldbpathAFP="" # Share exists on disk5dont know if this is worth looking into?
-
2 hours ago, Frank1940 said:
Let's try another experiment. First, fix the permissions. Then, open up a Windows Explorer window to your media share (as shown below) and drag-and-drop a file from a folder on your Windows computer to the share in the Explorer window. (Media is the share and Family DVD Videos is a folder in that share.)
so i tried as you suggested,
Before
root@Zeus:~# ls -alh /mnt/user total 56K drwxrwxrwx+ 1 nobody users 58 Jun 12 23:39 ./ drwxr-xr-x 13 root root 260 Jun 11 09:14 ../ drwxrwxrwx 1 nobody users 132 Jun 12 23:38 media/After
root@Zeus:~# ls -alh /mnt/user total 52K drwxrwxrwx+ 1 nobody users 68 Jun 12 23:39 ./ drwxr-xr-x 13 root root 260 Jun 11 09:14 ../ drwxrwx---+ 1 nobody users 22 Jun 12 23:38 media/and this is the permissions inside the media share of the folder i dropped the file into.
root@Zeus:~# ls -alh /mnt/user/media total 40K drwxrwx---+ 1 nobody users 22 Jun 12 23:38 ./ drwxrwxrwx+ 1 nobody users 68 Jun 12 23:39 ../ drwxrwxrwx+ 1 nobody users 26 Jun 12 23:41 Test\ Folder/I dropped the file into the Test Folder, which is inside the media share - as shown the permissions look ok barring the "+" however if i navigate direct to that folder from windows explorer i can see my file - if i try accessing via the media share first i cant.
Thanks for you help so far in trying to diagnose this - im thinking of upgrading to 6.9.0 in case ive ran into some wierd glitch that updating might solve, what do you think?
my other thought is that seen as though i created another share which seems to work perfectly - can i create another share copy all my folders/ files from one to another then delete the old share...
-
Yea, this was using windows explorer copying a file from desktop to the share which is mapped as a network drive "Z"
one thing to mention which i dont know if this matters is i use a rootshare (SpaceInavders Video) this is currently set as so under SMB settings
[rootshare] path = /mnt/user comment = browseable = yes # Public writeable = yes vfs objects =note its currently set to public as im trying to diagnose this issue.
-
All dockers/ plugins seem to work just fine, at least not spotted any misbehaving just yet.
I've just been doing somemore checking on this and my media share no longer has the "+" in the permissions
root@Zeus:~# ls -alh /mnt/user total 56K drwxrwxrwx 1 nobody users 132 Jun 12 15:27 media/just tried to copy a file to the share and the permissions changed immediatley to
root@Zeus:~# ls -alh /mnt/user total 52K drwxrwx---+ 1 nobody users 108 Jun 12 16:53 media/ -
ls -alh /mnt/user
root@Zeus:~# ls -alh /mnt/user total 52K drwxrwxrwx+ 1 nobody users 68 Jun 12 10:51 ./ drwxr-xr-x 13 root root 260 Jun 11 09:14 ../ drwxrwxrwx 1 nobody users 82 Jun 11 09:49 Downloads/ drwxrwx---+ 1 nobody users 4.0K Feb 20 21:45 Nextcloud/ drwxrwxrwx 1 nobody users 402 Jun 10 21:58 appdata/ drwxrwxrwx 1 nobody users 34 Jun 4 08:16 applications/ drwxrwxrwx+ 1 nobody users 74 Jun 11 09:49 backups/ drwxrwxrwx 1 nobody users 6 Jun 10 22:25 books/ drwxrwxrwx 1 nobody users 19 Jun 11 09:47 documents/ drwxrwxrwx 1 nobody users 14 May 22 08:16 domains/ drwxrwxrwx 1 nobody users 6 Jun 11 09:21 games/ drwxrwxrwx 1 nobody users 19 Jan 17 2019 icons/ drwxrwxrwx 1 nobody users 80 Jun 11 09:49 isos/ drwxrwx---+ 1 nobody users 0 Jun 12 15:27 media/ drwxrwxrwx 1 nobody users 26 May 24 15:21 system/ drwxrwxrwx 1 nobody users 6 Jan 17 2019 tautulli/ drwxrwxrwx+ 1 nobody users 6 Jun 11 14:44 test/ drwxrwxrwx+ 1 nobody users 90 Jan 17 2019 zeus\ backups/ls -alh /mnt/cache
root@Zeus:~# ls -alh /mnt/cache total 16K drwxrwxrwx+ 1 nobody users 68 Jun 12 10:51 ./ drwxr-xr-x 13 root root 260 Jun 11 09:14 ../ drwxrwxrwx 1 nobody users 82 Jun 11 09:49 Downloads/ drwxrwxrwx 1 nobody users 402 Jun 10 21:58 appdata/ drwxrwxrwx 1 nobody users 14 May 22 08:16 domains/ drwxrwx---+ 1 nobody users 0 Jun 12 15:27 media/ drwxrwxrwx 1 nobody users 26 May 24 15:21 system/the permissions are wrong in a shares that use cache - one of which is media
root@Zeus:~# ls -alh /mnt/user/media total 40K drwxrwx---+ 1 nobody users 0 Jun 12 15:27 ./ drwxrwxrwx+ 1 nobody users 68 Jun 12 10:51 ../ drwxrwxrwx 1 nobody users 48 Jun 4 12:40 4K\ Movies/ drwxrwxrwx 1 nobody users 20K Jun 1 09:18 Movies/ drwxrwxrwx 1 nobody users 10 Feb 1 2019 Music/ drwxrwxrwx 1 nobody users 136 Apr 5 15:04 Photographs/ drwxrwxrwx 1 nobody users 99 May 23 03:03 TV\ Shows/ drwxrwxrwx 1 nobody users 10 Apr 5 16:34 Test\ Photos/All shares are setup in the usual way using share tab, directories within the shares are unusually setup by using my windows machine.
-
Hi All - hope someone can help me with the following issue.
The permissions on someone of shares seems to be changing automatically - it only seems to affect shares that use the Cache drive, however i created a new "test" share which uses the cache drive and that seems to be working perfectly.
The problem i have is when i copy/ move a file from my windows 10 machine it seems to copy just fine however whenever i try and access that share again i get the message "Windows cannot access \\Zeus\rootshare\media". - if i run the "Docker safe new perms" it does fix the problem and i can gain access to the share again until i copy/ move another file the share and the process repeats. Strangely this process also happens if i right click the share folder in windows and select properties.
I've noticed when i run ls -lah when im able to to write to the share the permissions are "drwxrwxrwx+ 1 nobody users 0 Jun 12 10:26 media/" and when i get the error on windows and check ls -lah again the permissions chage to "drwxrwx---+ 1 nobody users 0 Jun 12 10:45 media/"
I've attached my diagnostics if that helps.
Thanks all
-
No just using VNC, I tried searching for updated VNC drivers if such a thing exist, I’m completely new to Linux so I really dont know much.
As as I can’t find anyone else with the same issue I suppose it’s something I’m doing wrong but I followed all guides I can find
-
Can anyone offer any advice here... do I need to upload any logs files?
-
Does the same go for the windows setup with only one mapped share the (rootshare) is using Krusader and copying between disk shares the only option?
Thanks
-
Hi all,
So i have a "Media" share that is set to not use the cache, however it seems under some types of operation the share is using the cache drive.
When downloading movies via Radarr, everything works perfectly - downloaded to "downloads" share which is on the cache then Radarr moves to the "media" share on the array. however is i just download a movie manually without radarr i need to manually move to the array once i cleaned up the movie title/ folder name etc etc.
For this i used to use Krusader however i noticed that when i did movies would be copied to a Media folder on the cache drive. i then this weekend spotted a video from SpaceInvaderOne, or Gridrunner on these forums in which he setup a rootshare - so i thought i would give this ago and still no joy.
What did work is when i had each share mapped as a drive in windows and i copied from one to another however this has obvious drawbacks (speed being the main one)
i have tried setting the share to use cache then set it back to no.
Thanks for any advice guys.

Has my USB flash Drive Died?
in General Support
Posted
Hi All,
Hopefully someone can help, i just recieved this notification via Discord from my server. (Image Attached)
Check my System Log and can see lots of the following errors...
May 15 21:21:09 Zeus kernel: critical medium error, dev sda, sector 3571842 op 0x0:(READ) flags 0x84700 phys_seg 28 prio class 2 May 15 21:21:46 Zeus kernel: fat_get_cluster: 1498 callbacks suppressed May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start 233e3e70) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start 233e3e70) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start 233e3e70) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start b9b677b7) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start b9b677b7) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start b9b677b7) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start cdf9b71d) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start cdf9b71d) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start cdf9b71d) May 15 21:21:46 Zeus kernel: FAT-fs (sda1): error, fat_get_cluster: invalid start cluster (i_pos 0, start 9994e31f)I'm guessing i need to replace with another usb drive but how? I've downloaded a backup via the Main>Flash page. can i just copy the contents of this zip file to another usb drive?
Thanks