

MrMister
-
Posts
9 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by MrMister
-
-
4 hours ago, JorgeB said:
One possible cause is running the RAM out of spec, see here and stick to the max officially supported speeds for your config.
Thank you. I've been running this cfg for a year now but I'm happy to try [using the official XMP setting, nothing fancy 4 x 16 GB @ 3200 MHz]
What is super annoying to me is that libvirt just stops working. I can't get to the VM tab, virsh list --all times out. I can't enable / disable via VM Manager or rc.d/rc.libvirt. Everything else is working (all containers, plugins etc.) -
Hi folks,
I've been having some issues with my server turning off sometimes and I got the Fix Common Problems notification
Your server has detected hardware errors. You should install mcelog via the NerdPack plugin, post your diagnostics and ask for assistance on the unRaid forums. The output of mcelog (if installed) has been loggedI did install mcelog and ran Diagonistics (attached here).
I'm not really sure what to look for here.
Running the latest Beta (Version: 6.9.0-beta35) on AMD (c state disbaled, nvidia driver instaled via new plugin).
I actually have some issues with VMs (complete Disk + GPU passthough with Windows Disk works) but e.g. new Linux VM with Seabios everyhting just freezes on the VMs tab, I need to reboot then. Not sure if i wanna mess with /etc/rc.d/rc.libvirt (status not giving me output).
Also Disk passthrough with Linux VM (from encrypted Linux drive) is also not working when I attach the GPU (VNC works fine).
Really grateful for any help / feedback on the detected hardware defect.Kind regards
-
14 hours ago, SnickySnacks said:
I don't know much about cache disks.
Obvious suggestion is to fix the error on the disk and then enable plugins/dockers/VMs one at a time until you can determine which one is causing the problem, I suppose.Thank you so much for your support!
As presumed one of the cache drives seemed to have been corrupted. What i did to fix it:
- grabbed everything that I could from the healthy drive to another ssd
- hit new configuration only kept parity and data, removing the cache drives- disabled docker and libvirt via settings
- started the array
- stopped the array
- removed the partitions of the cache drive (unassigned devices)
- added both cache drives again
- started the array
- formatted the cache drives
- copied the data from the other ssd
- enabled docker and libvirt again
--> et voila
now it also shows the correct size (raid 1, 9xx GB) again -
Quote
At the time those diagnostics were created, were any CPUs showing 100% load? If so, which ones?
As you can see in the bad photo i made from the wub UI, 21/24 threads were at 100%...
QuoteAlso, have you tried booting in safe mode and seeing if this occurs with no plugins/dockers/vms loaded?
I did, the issue is not occuring!
QuoteThere does seem to be some corruption on one of your disks:
The plot thickens!
I tried starting clearing the cache disc (downloads that weren't moved yet bc mover didn't get to run etc)
--> then the load starts to rise again!
sdj is one of the cache discs (total: 2 x 1 TB Crucial SSDs).
They were Raid1 before the upgrade! --
I remember that after the boot after the new build I forgot to plug in one of the PCI Sata Card(!) and started the array (1 array disc and 1 cache drice was missing) - as it emulated the drive from the array and the cache drive were raid 1 I thought lets give it a spin!
I then installed the card and before cache was roughly 1 TB now its showing 2 TB total capacity!
So I need to check if I can grab everything from the cache drive asap (all my appdata and vdisks), maybe externally connected to another machine.
Then remove the failing cache drive config wise and then add it again?
Thank you so far! -
26 minutes ago, madams2246 said:
I updated my Plex docker this morning like I have done many times in the past. After the update finished the Plex docker completely disappeared from the Unraid GUI. I am running Unraid version 6.3.5
Did you check via terminal if it's still there?
docker ps -aAnd if you can manually start it via docker start idofthecontainer
-
This should be in General support, right? Did it get moved here? oO
-
1 hour ago, SnickySnacks said:
Diagnostics, etc, but I recall seeing this issue being related to certain dockers before:
Thanks.! Just started reading the Topic.
BTW Currently running Unraid 6.7.2.
Diagnostics attached. (Couldn't do it before as the topic was under moderation or something like that)
Also ran Fix Common Problem, only thing appearing is that shares are using cache although they shoudn't.
I'm not running ant additional docker containers then before. Just made the switch from Intel to AMD about a week ago and this issue popped up.. -
Hi everyone,
I was a happy camper with my i5-8600k no issues besides a lack of cores for my usage.
So I upgraded to AMD 3900X, missing the integrated GPU but that's a different story:Since the upgrade to AMD I can watch the CPU load rise, without any indication I can make out. No processes hogging CPU, no abnormal disk writes and enough RAM (64 GB). So the server then becomes unresponsive. I'm not able for force stop the docker process, libvirtd does work.
So in the end I end up force stopping my machine via power button.
I already tried disabling C states and adding the kernel parameter (adjusted to 24 threads aka 0-23) as recommended by spaceinvaderone (starting around 9:50 min).
I'll attach the diagnostics within the next hour.
I was gone for 4 days and the load was at 1300 oO
This morning like 30 minutes after starting up I was at 127 already see screenshot with htop, top, iotop and vmstat.
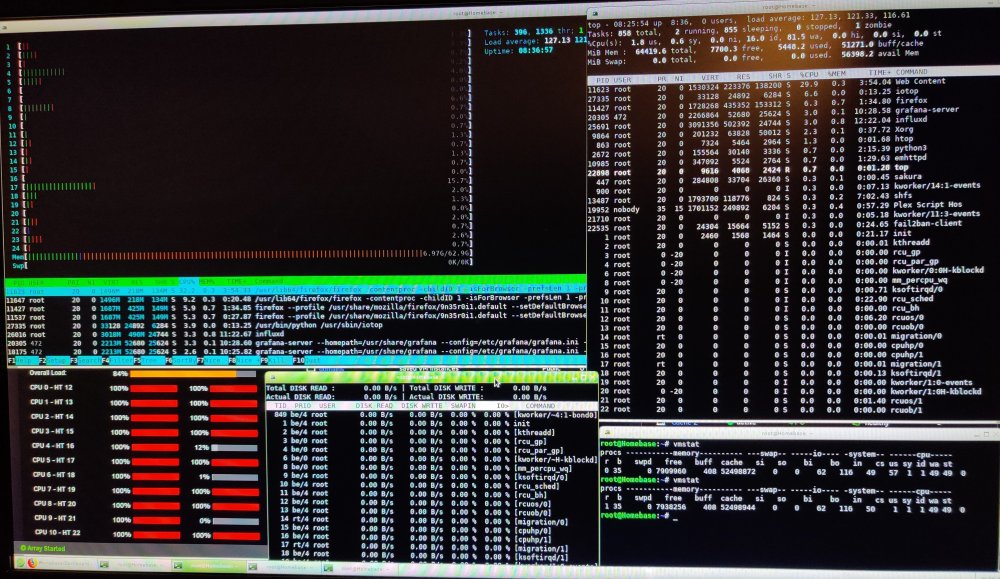
Running X570 Taichi with the latest BIOS (2.10 - 2019/9/17).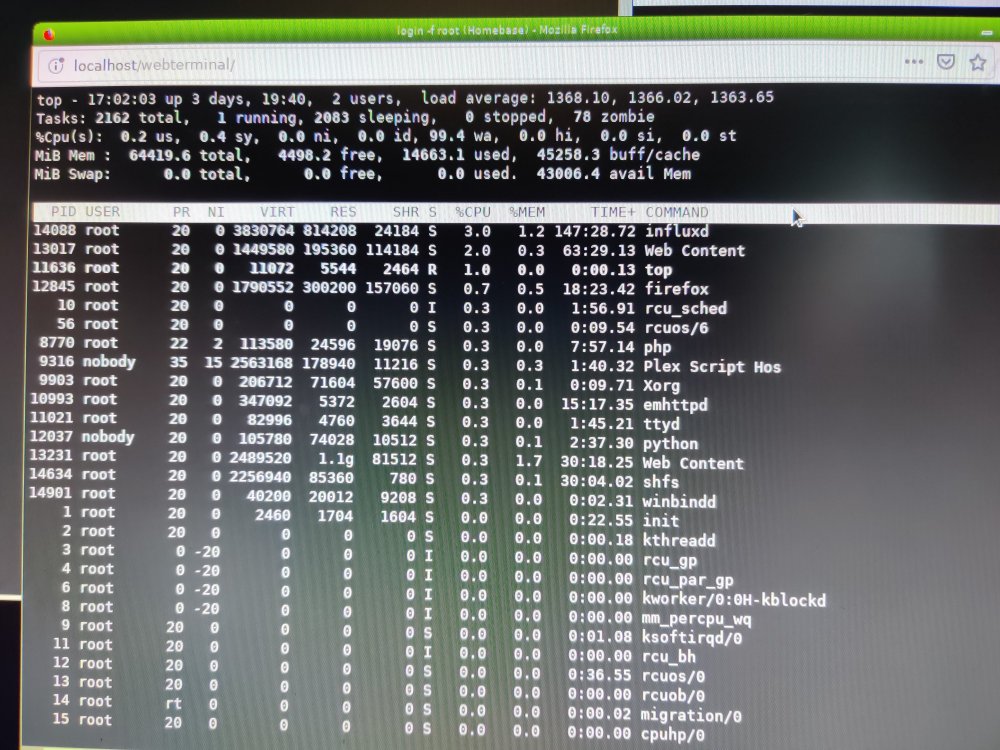


Machine Check Events detected on your server
in General Support
Posted
Does feel right. So many people are running 4 x 16 GB at 3600 MHz.
Turns out as soon as I use SeaBios libvirt crashes.