

Guzzi
-
Posts
219 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Guzzi
-
-
If you really want to go with the old drives , I'd suggest you first test smart values for all drives, throw away the drives that fail or show many errors and then run preclear on the error free ones. Finally you should have a set of drives that should be good to go.
-
I can confirm issues with sleep states of the drives. The states are even different between dashboard tab and main tab. Are they using different methods to get the drives state?
-
I have the same issue, running on a Pentium G4600 - also waiting for a solution...
-
Thanks for your explanations! So I'll have to live with the "N/A" temps obviously
") - and yes, I think it is not an issue in from operational view. I am really happy to be able to do that fancontrol, so again many thanks for your plugin!
- and yes, I think it is not an issue in from operational view. I am really happy to be able to do that fancontrol, so again many thanks for your plugin!
-
 1
1
-
-
5 hours ago, dmacias said:
Any webGui hdd temp readings are taken directly from the unRAID ini files. I don't poll the hdds again. I use what's already available. The fancontrol script does poll the hdds but with the exclusion of hdds in standby. The problem is that some drives spin up when polled by smartctl so your drives may never sleep. My Seagate and Toshiba drives all spin up when polled with smartctl. My Western Digital do not.
Ah, I remember, that in the past there was a discussion, that some drives DO spinup. I use WD drives since decades, so I never had that issue.
So do I understand correct:
1.) display of the temperature can't be fixed anyway within the plugin, because it is using what unraid provides - only Tom could add an option to provide temp info for standby drives. I think I asked for this some time ago, so this probably won't happen any time soon.
2.) Fancontrol script ignores any device in standby - so what does it do, when ALL drives are down? Will it set the fans to minimum? Am I right, that this could lead to a too high temperature, e.g. when hdd fans are switched off due to the fact, that fancontrol script does not know about the hdd temperatures anymore?
I think it is not a biggie, because making sure, that fans at least run at a minimum speed should be able to avoid that.
Releated question: How tdo you get temperature from drives not in the array, e.h. an unassigned drive? Do you poll those separately? (Can't test myself right now, because I have only array drives currently)
-
hi dmacias, first thanks a lot for this plugin, a real value add for those of us running x11 boards :-).
I have one question: I use the fancontrol to control the fans for hdd cooling. Now, if all hdds are spun down, it shows temp "N/A".
Is this intended? Or could we also show the temperature when the discs are down.
I can get the temperature from all my disks when they're down on the command line:
for i in $(ls /dev/sd[a-z] 2> /dev/null); do smartctl -a $i |grep Temp;done
Would it make sense to use this at least as a fall back to determine the temps, when all are spun down?
Thanks for all your work!
-
On 22.9.2016 at 10:28 PM, Guzzi said:
Hi bonienl, I know you're busy with latest GUI update implementation, just wanted to ask, if this could get either more testing or updated (maybe with an option) to the repo. Works fine for me, so I am personally fine with it, just have to overwrite it whenever I boot.
@johnnie.black, as you were interested too, would you like to test it? Simply rename attached file of OP to autofan and copy it into /usr/local/emhttp/plugins/dynamix.system.autofan/scripts and restart the tool (e.g. update a setting in the GUI will restart it using the updated script).
Hi bonienl,
seems the former attachment is gone during forum migration - still would like to ask you to add the exclusion of SSDs within the autofan script.
The relevant change is here:
# Obtain the ID of your flash drive (your flash drive is named "UnRaid" right?) flash=/dev/`ls -l /dev/disk/by-label| grep UNRAID | cut -d/ -f3 | cut -c 1-3` # Obtain the SSDs of your system ssds=/dev/`ls -l /dev/disk/by-id| grep SSD | grep -v part | cut -d/ -f3 | cut -c 1-3` # Count the number of drives in your array (ignoring the flash drive we identified) # NUM_OF_DRIVES=$(ls /dev/[hs]d? | grep -v "$flash" | wc -l) NUM_OF_DRIVES=$(ls /dev/[hs]d? | grep -v "$flash" | grep -v "$ssds" | wc -l) # Identify the drives in your array so we can test their temperature COUNT=1 # for d in $(ls /dev/[hs]d? | grep -v "$flash"); do for d in $(ls /dev/[hs]d? | grep -v "$flash" | grep -v "$ssds"); do HD[$COUNT]=$d #echo HDD=${HD[$COUNT]} # Uncomment for debugging COUNT=$[$COUNT+1] done function_get_highest_hd_temp() { [...]instead of hardcoded grep of 'SSD' this could also be replaced by a GUI editable search expression or regex...
-
Nice one - would drastically reduce the time data on cache drive is unprotected (if cache is not mirrored) :-)
-
I can confirm that I got S3 sleep working with both IBM 1015/1115 and SI3132 (that is with older AMD based motherboard).
However, to my experience it is mostly depending on the motherboard and BIOS - I am also looking for a newer e.g. Skylake board that would still support proper S3 with unraid (and fancontrol!), but it seems, it is a try and error process... so if anybody has made positive or negative experiences it would be nice to read it here.
-
@johnnie.black, as you were interested too, would you like to test it? Simply rename attached file of OP to autofan and copy it into /usr/local/emhttp/plugins/dynamix.system.autofan/scripts and restart the tool (e.g. update a setting in the GUI will restart it using the updated script).
I upgraded my board and unfortunately autofan doesn't work anymore, so can't test.
... is it the X11SSM-F that doesn't support autofan anymore? (Asking, because I thought about upgrading to that board too)
-
It has been a while since I looked into the "autofan" plugin.
When time permits I see what I can do (maybe it is as easy as you suggest) or perhaps gfjardim may jump in, a great deal of work came from him!
... I have had a look myself and did some tests, so I will post a modified autofan script.
What it does is:
- detecting the SSD drives in the system
- exclude the SSD drives from the highest-temp-calculation
You might want to add an on-off-switch to allow the user to enable/disable this part.
Tested on my own system and it worked fine; however, I use 'SSD' to identify SSD-drives within the /dev/disk/by-id hive - and I am not sure, if this will work for all brands (works with sandisk SSD fine here).
I also tested, that the script works, if there is multiple SSDs in the system - they would all get excluded (if they can be detected propertly).
Note:
If the detection is not reliable enough, an alternative implementation would be to set the $ssds variable manually in the config, letting the user select the devices to exclude.
Hi bonienl, I know you're busy with latest GUI update implementation, just wanted to ask, if this could get either more testing or updated (maybe with an option) to the repo. Works fine for me, so I am personally fine with it, just have to overwrite it whenever I boot.
@johnnie.black, as you were interested too, would you like to test it? Simply rename attached file of OP to autofan and copy it into /usr/local/emhttp/plugins/dynamix.system.autofan/scripts and restart the tool (e.g. update a setting in the GUI will restart it using the updated script).
-
It has been a while since I looked into the "autofan" plugin.
When time permits I see what I can do (maybe it is as easy as you suggest) or perhaps gfjardim may jump in, a great deal of work came from him!
... I have had a look myself and did some tests, so I will post a modified autofan script.
What it does is:
- detecting the SSD drives in the system
- exclude the SSD drives from the highest-temp-calculation
You might want to add an on-off-switch to allow the user to enable/disable this part.
Tested on my own system and it worked fine; however, I use 'SSD' to identify SSD-drives within the /dev/disk/by-id hive - and I am not sure, if this will work for all brands (works with sandisk SSD fine here).
I also tested, that the script works, if there is multiple SSDs in the system - they would all get excluded (if they can be detected propertly).
Note:
If the detection is not reliable enough, an alternative implementation would be to set the $ssds variable manually in the config, letting the user select the devices to exclude.
-
I'm doing some testing with Oracle F80 flash accelerator as a cache device, and have a question regarding the Dynamix System Autofan plugin:
Is it possible to exclude specific drives from the plugin's calculations?
The ssd's attached to the F80's hba have a 74C operating ceiling, and average 50C under load even with 120x38mm delta fan @ 3500rpm. I would like to leave the plugin default (35-45C) in place for 3.5" HDDs, but the SSD temps on the F80 are maxing out the fans currently.
Thanks!
AFAIK it's not possible at the moment, I would also like to request this, as anytime I do longer writes to my cache SSD it goes 50C+ making all fans speed up unnecessarily.
+1 from my side - same situation: using a SSD as cache drive which usually operates with higher temps than the HDs, thus when things are using the cache drive, fans are spinning up to full speed, which is not necessary.
Simplest solution for this would be to add a setting, that allows to exclude certain drives from the calculation of the max drive temp.
The script already excludes the flash drive:
# Obtain the ID of your flash drive (your flash drive is named "UnRaid" right?) flash=/dev/`ls -l /dev/disk/by-label| grep UNRAID | cut -d/ -f3 | cut -c 1-3` # Count the number of drives in your array (ignoring the flash drive we identified) NUM_OF_DRIVES=$(ls /dev/[hs]d? | grep -v "$flash" | wc -l)
So might not be too hard to add a setting for exclusion for other drives too!?
-
-
My mSATA cache drive will run hot enough to trigger the warning notification when transferring a lot of files to and from it. Obviously an mSATA SSD is going to run hotter than a traditional HDD and it's not really a problem, but the notifications are annoying.
Is there any way to disable (or change) the temp warnings and notifications for ONLY the cache drive and leave the other drives alone?
This is not possible yet!
I have made a change though, which allows to set the temperature threshold values for each individual disk, and overrule the global settings.
Hi bonienl,
I'd very much appreciate, if the fancontrol plugin could also have either individual settings or the possibility to ignore the cache disk - same reason as above: the cache disk is a SSD and quickly reports high temperature, resulting in the fans going to full speed, though the hard disks are still in the low temp region. THanks for all your work!
-
Tha issue only applies to xfs - not to reiserfs. I reported that before and answer was, that xfs formatted disks are smaller due to more overhead. However, I'd prefer to show them as "1TB" instead of "1000GB" too - to make it clear, I am talking about the same physical drives - only the filesystem matters.
-
Thanks for the hint - indeed, that is a cheap and obviously better solution than the sil3132 based cards.
-
2 Port Controllers
SIL 3132 PCIe gen1 1x (250MB/s)
2 x 80MB/s
Thanks Johnnie, that explains my pcheck limitation on my boxes - as I have 2xLSI2008, 6 onboard plus this PCIe card.
It seems, there is no better alternative for PCIex1/2-port available, right? (Don't have a 3rd slot for 3rd LSI card available either...)
-
I believe the issue is not the driver or the controller itself, but for some reason the way a parity check works in Unraid does not go well with this card.
[...]
Maybe Tom can update us and tell us if some progress was made.
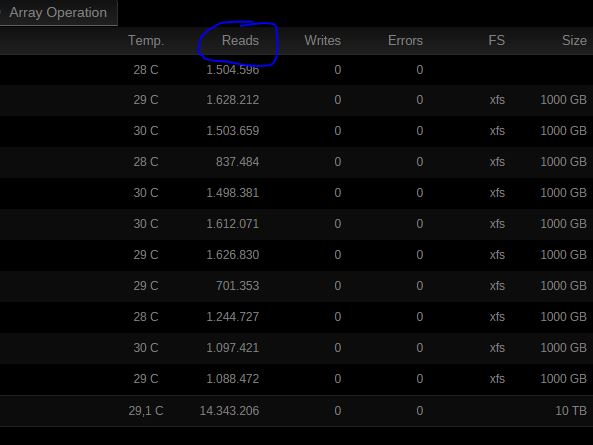
What I noticed and posted already some time ago is, that the read counts in UnRaid GUI are not counting up the same on parity checks. With V5.x, the counts ("Reads" in GUI) had been very close to be the same for all disks, which seems "logical" (assuming, nothing else accesse the disks except the parity check). With V6 they have big differences. Didn't get an answer from Tom yet, how and where those counts are taken in the software - maybe that could give a hint why and where the speed degradation is caused.
-
Timeout: No Response from localhost
Yeah, I was worried about that. The removal of the "if" condition suggested by Guzzi has the side effect of the script taking too long to run.
I'll have to think about how to fix it.
That's probably caused by harddisks, that do not support reading temps when spun down !?
Maybe have a look at how it is solved in myMain - there I do get temps even when HDs are spun down, but seems, that those scripts do handle also other brands of disks that do not support temps when spun down ...
-
Under workgroup settings, it shows a win10 laptop as elected master. While this machine has the "highet" win version, the eletion is incorrect, as there is a domain controller on the net, that should be elected as master browser !??
-
One final observation for Tom or anyone else, in the example below the parity drive is on the motherboard controller and all 8 data drives on the SAS2LP, first did a parity sync and then a parity check, as far as I understand both operations simultaneously read all disks on the SAS2LP and nothing more, but the read numbers for most drives during the parity check are a lot higher, is there any difference in the way a check works that could explain this issue?


What I see there is what I noticed myself: The read counts are a lot different - e.g. 75k vs. 103k. I knwo they are not always "exactly" the same, but with my build on unraid 5 they were usually very close (unless there was any trouble with a respective disk).
@Tom: from were does unraid get those counts? Does it make sense to activate debug logging of the sas2lp driver to see, if there is something strange happening causing re-reads - which could of course slow down performance and reduce overall throughput? Obviously, we do NOT end in read errors - as noone so far reported that reads really do fail ...
-
Short description of what I "see":
- A parity check does not constantly run at full i/o speed (which is approx 1500mb/s total), but instad runs a lot at approx 500 mb/sec with peak happening to 1500 -> this results in a totally reduced overall speed
This symptom is very similar to one I was having earlier, by any chance do you have any Samsung disks model HD203WI or HD153WI?
If so see here:
http://lime-technology.com/forum/index.php?topic=42384.0
No, no Samsung disks, they're all WD (of different sizes) - and I had hight parity check speeds under unraid 5 with the same disks.
-
Output of my 2 (1015 reflashed) cards - and I am a "affected user", but not using marvell adapters:
02:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03) Subsystem: LSI Logic / Symbios Logic Device 3020 Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 18 Region 0: I/O ports at ee00 [size=256] Region 1: Memory at f04c0000 (64-bit, non-prefetchable) [size=16K] Region 3: Memory at f0080000 (64-bit, non-prefetchable) [size=256K] [virtual] Expansion ROM at f0000000 [disabled] [size=512K] Capabilities: [50] Power Management version 3 Flags: PMEClk- DSI- D1+ D2+ AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] Express (v2) Endpoint, MSI 00 DevCap: MaxPayload 4096 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ DevCtl: Report errors: Correctable+ Non-Fatal+ Fatal+ Unsupported+ RlxdOrd+ ExtTag- PhantFunc- AuxPwr- NoSnoop+ FLReset- MaxPayload 128 bytes, MaxReadReq 512 bytes DevSta: CorrErr+ UncorrErr- FatalErr- UnsuppReq+ AuxPwr- TransPend- LnkCap: Port #0, Speed 5GT/s, Width x8, ASPM L0s, Latency L0 <64ns, L1 <1us ClockPM- Surprise- LLActRep- BwNot- LnkCtl: ASPM Disabled; RCB 64 bytes Disabled- Retrain- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 5GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range BC, TimeoutDis+, LTR-, OBFF Not Supported DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis-, LTR-, OBFF Disabled LnkCtl2: Target Link Speed: 5GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance De-emphasis: -6dB LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete-, EqualizationPhase1- EqualizationPhase2-, EqualizationPhase3-, LinkEqualizationRequest- Capabilities: [d0] Vital Product Data Unknown small resource type 00, will not decode more. Capabilities: [a8] MSI: Enable- Count=1/1 Maskable- 64bit+ Address: 0000000000000000 Data: 0000 Capabilities: [c0] MSI-X: Enable+ Count=15 Masked- Vector table: BAR=1 offset=00002000 PBA: BAR=1 offset=00003800 Capabilities: [100 v1] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+ CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+ AERCap: First Error Pointer: 00, GenCap+ CGenEn- ChkCap+ ChkEn- Capabilities: [138 v1] Power Budgeting <?> Capabilities: [150 v1] Single Root I/O Virtualization (SR-IOV) IOVCap: Migration-, Interrupt Message Number: 000 IOVCtl: Enable- Migration- Interrupt- MSE- ARIHierarchy- IOVSta: Migration- Initial VFs: 16, Total VFs: 16, Number of VFs: 16, Function Dependency Link: 00 VF offset: 1, stride: 1, Device ID: 0072 Supported Page Size: 00000553, System Page Size: 00000001 Region 0: Memory at 00000000f04c4000 (64-bit, non-prefetchable) Region 2: Memory at 00000000f00c0000 (64-bit, non-prefetchable) VF Migration: offset: 00000000, BIR: 0 Capabilities: [190 v1] Alternative Routing-ID Interpretation (ARI) ARICap: MFVC- ACS-, Next Function: 0 ARICtl: MFVC- ACS-, Function Group: 0 Kernel driver in use: mpt2sas Kernel modules: mpt2sas 03:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03) Subsystem: LSI Logic / Symbios Logic Device 3020 Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 16 Region 0: I/O ports at de00 [size=256] Region 1: Memory at f0ac0000 (64-bit, non-prefetchable) [size=16K] Region 3: Memory at f0680000 (64-bit, non-prefetchable) [size=256K] [virtual] Expansion ROM at f0600000 [disabled] [size=512K] Capabilities: [50] Power Management version 3 Flags: PMEClk- DSI- D1+ D2+ AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] Express (v2) Endpoint, MSI 00 DevCap: MaxPayload 4096 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ DevCtl: Report errors: Correctable+ Non-Fatal+ Fatal+ Unsupported+ RlxdOrd+ ExtTag- PhantFunc- AuxPwr- NoSnoop+ FLReset- MaxPayload 128 bytes, MaxReadReq 512 bytes DevSta: CorrErr+ UncorrErr- FatalErr- UnsuppReq+ AuxPwr- TransPend- LnkCap: Port #0, Speed 5GT/s, Width x8, ASPM L0s, Latency L0 <64ns, L1 <1us ClockPM- Surprise- LLActRep- BwNot- LnkCtl: ASPM Disabled; RCB 64 bytes Disabled- Retrain- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 5GT/s, Width x4, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range BC, TimeoutDis+, LTR-, OBFF Not Supported DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis-, LTR-, OBFF Disabled LnkCtl2: Target Link Speed: 5GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance De-emphasis: -6dB LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete-, EqualizationPhase1- EqualizationPhase2-, EqualizationPhase3-, LinkEqualizationRequest- Capabilities: [d0] Vital Product Data Unknown small resource type 00, will not decode more. Capabilities: [a8] MSI: Enable- Count=1/1 Maskable- 64bit+ Address: 0000000000000000 Data: 0000 Capabilities: [c0] MSI-X: Enable+ Count=15 Masked- Vector table: BAR=1 offset=00002000 PBA: BAR=1 offset=00003800 Capabilities: [100 v1] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+ CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+ AERCap: First Error Pointer: 00, GenCap+ CGenEn- ChkCap+ ChkEn- Capabilities: [138 v1] Power Budgeting <?> Capabilities: [150 v1] Single Root I/O Virtualization (SR-IOV) IOVCap: Migration-, Interrupt Message Number: 000 IOVCtl: Enable- Migration- Interrupt- MSE- ARIHierarchy- IOVSta: Migration- Initial VFs: 16, Total VFs: 16, Number of VFs: 16, Function Dependency Link: 00 VF offset: 1, stride: 1, Device ID: 0072 Supported Page Size: 00000553, System Page Size: 00000001 Region 0: Memory at 00000000f0ac4000 (64-bit, non-prefetchable) Region 2: Memory at 00000000f06c0000 (64-bit, non-prefetchable) VF Migration: offset: 00000000, BIR: 0 Capabilities: [190 v1] Alternative Routing-ID Interpretation (ARI) ARICap: MFVC- ACS-, Next Function: 0 ARICtl: MFVC- ACS-, Function Group: 0 Kernel driver in use: mpt2sas Kernel modules: mpt2sas
Short description of what I "see":
- A parity check does not constantly run at full i/o speed (which is approx 1500mb/s total), but instad runs a lot at approx 500 mb/sec with peak happening to 1500 -> this results in a totally reduced overall speed
- unraid GUI reports a lot more "reads" in the disk page and they are not close to be the same for all disks - this was the case when I did run unrai5 (with the same hardware and disks) - I remember, that the reads (and write, when doing a rebuild) where closed to be the same on the affected disks (depending on their size of course!)
Because of the latter, I thought it might be interesting if there is anything hapening on the driver level and debug output might be interesting. @Tom: from where do you get the "readcounts" within the unraid driver?


Mix of varying quality/age drives how do I choose what to use
in General Support
Posted
And as mentioned by others - do never ever use bad drives - it is not worth the trouble you'll get - so if smart reports issues, you should really dispose those drives.