

T3nchu
-
Posts
24 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by T3nchu
-
-
Think I got it figured out. I replaced the PCI cards. Upgrade to 6.7.2. Reassignment my drives and check parity correct. It started a parity check and flag the error drive. After replacing the drive restart the server, it started to rebuild my replaced drive. Once this is done, i will work on my other V5 UNRAID server with new parts.
-
I currently have a fail drive but the config is valid. Is that ok for my to update to V6 and rebuild the drive?
-
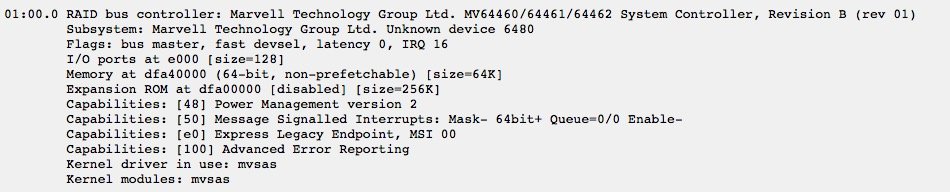
I have 4.7 UNRAID with RAID bus controller: Marvell Technology Group Ltd. MV64460/64461/64462 System Controller, Revision B (rev 01). I know there are issue with this card type. I keep getting a fail drive randomly. Initially, I would rebuild the drive and sometimes it would be months before it fail again. Recently, I can't seems to rebuild the drive anymore. It would initiate rebuild then fail. The drive I put is precleared. How do I go about and save my system? I purchased a LSI 9207-8i card, but the system is not recognizing it (according to the company I purchase the card from, it is in IT mode). Any help would be greatly appreciated.
-
hi, did you get lxml to install on your Unraid 5?
-
Anyone know why i keep getting the following repeating log?
Oct 24 15:12:19 tower2 rpc.statd[1237]: No canonical hostname found for 192.168.1.105
Oct 24 15:12:19 tower2 rpc.statd[1237]: STAT_FAIL to tower2 for SM_MON of 192.168.1.105
Oct 24 15:12:19 tower2 kernel: lockd: cannot monitor TheBeast.local
-
NVM I found the email. Just need to reply with my second USB Flash GUID.
-
Hi,
I brought 2 Pro keys 2/26/14 but only used one. How do I go about and getting my second pro key?
-
getting the msg every 10 mins. check the IP address which is not attached to any computer??? Very odd!
-
Power supply info: http://lime-technology.com/forum/index.php?topic=12219.0
That's where I got the information and went with http://www.newegg.com/Product/Product.aspx?Item=N82E16817139006.
Thanks.
-
According to this drawingWhat model PSU? Some 700W PSU are not suitable to power 14 drives.
Really? That would be cool if that's the problem. I was able to mount all the drive that's connected to the PCI card individually and do SMART test on them. All seems fine. My PSU is the following http://www.newegg.com/Product/Product.aspx?Item=N82E16817341018, OCZ ModXStream Pro 700W Modular High Performance.
http://www.ocztechnology.com/res_old/manuals/psu/OCZMXSP500-700.pdf
of the cabling of that power supply, all the SATA and MOLEX connectors are on the 12V2 rail.
According to this drawing, it is a 25 Amp rail.
http://www.ocztechnology.com/images/awards/mxsp_wattage_charts.jpg
That same rail is shared by the PCIe power connectors (but odds are you are not using those connectors)
Even with all green drives, at 2 amps each, that's 28 amps, over the limit for the one 12V2 rail, and that is not counting the power draw for fans.
Since it seems you have a number of non-green drives, you are well over the limit of that supply. (figure on closer to 3 amps per non-green drive when spinning up) If, for example you have 7 non-green and 7-green that is still (7*3)+(7*2)= 35 Amps, plus a few more amps for the fans. You need 38 to 40 amps of capacity for the disks alone. It is why most multi-rail power supplies are not suitable for large arrays of disks.
Thanks for the info. Now I know why I am having intermittent share drive dropping and server going off line. Think I might have find my problem. Never occur to me the PSU spec Amp is more important than the Watts

So I went ahead and order the http://www.newegg.com/Product/Product.aspx?Item=N82E16817139006. Can I just add my old drives back and do a initconfig and rebuild the parity and be good to go with whatever data I have in those drives?
Thanks for your help.
-
Would u recommend http://www.newegg.com/Product/Product.aspx?Item=N82E16817139020 or http://www.newegg.com/Product/Product.aspx?Item=N82E16817139006. 750W might be an overkill for my max 15 drives server, but might be good if I look to expand further down the road
 . Currently, I do have mixed drives, 7200 and Green in my server. I use http://www.newegg.com/Product/Product.aspx?Item=N82E16817994028 for the 3-5 drive configuration. Drive temp goes to mid 40's on the 7200 and 30's with the green drive when they spin up. It use to go up to 50 with the 7200 but I had added some more fans in the box since to get the temperature down.
. Currently, I do have mixed drives, 7200 and Green in my server. I use http://www.newegg.com/Product/Product.aspx?Item=N82E16817994028 for the 3-5 drive configuration. Drive temp goes to mid 40's on the 7200 and 30's with the green drive when they spin up. It use to go up to 50 with the 7200 but I had added some more fans in the box since to get the temperature down. -
What model PSU? Some 700W PSU are not suitable to power 14 drives.
Really? That would be cool if that's the problem. I was able to mount all the drive that's connected to the PCI card individually and do SMART test on them. All seems fine. My PSU is the following http://www.newegg.com/Product/Product.aspx?Item=N82E16817341018, OCZ ModXStream Pro 700W Modular High Performance.
-
Is there anyway to re-add the old drive that still has data on the drive to my raid? I can see the data still intact on them.
-
One thing that make me think the PCI card is bad is that when I boot up the drive sometime the port checking on the PCI would not complete and hangs. I can see the server output when I hook a monitor to it.
-
Sounds like the drive is losing connectivity with the computer. Could be anything - bad controller, bad sata cable, bad power splitter, bad backplane, bad PSU, bad drive, etc. May take some experimenting to figure out.
lol, great.... Well I at least know my motherboard, CPU, PSU and 6 drives are good since I have not see any problem since I rebuild the parity with those drive. I have a 700W PSU think that's enough to power 14 drives? Some are 2TB green and 1.5TB seagate 7200. Think I will get a new PCI card and see if that will take care of the problem.
Thanks for ur help.
-
You should post a smart report of the disk. I suspect either the disk is failing or you have a cabling problem to the disk. If the smat report is clean you should try shutting down the server and resecuring (or replacing) the cables to this disk.
You don't think there is some wrong with my PCI card?
-
I did check the smart report and sometimes it would not report anything at all on the ones that's mark as unformatted. I did check the cables the they all seems to be well secured. The cable I use for my PCI card is the 1 to 4 cable so it would be kind of hard to change it individually and they are not cheap
 . What are the best way to add my drive back to the unraid and preserve the data on the drive that will be added, since I have new parity that does not include the seven drives that's offline now . Thanks.
. What are the best way to add my drive back to the unraid and preserve the data on the drive that will be added, since I have new parity that does not include the seven drives that's offline now . Thanks. -
keep getting the follow error and got a drive showed up as disabled.
Jun 25 20:00:35 Tower kernel: ata16: exception Emask 0x10 SAct 0x0 SErr 0x90202 action 0xe frozen
Jun 25 20:00:35 Tower kernel: ata16: irq_stat 0x00400000, PHY RDY changed
Jun 25 20:00:35 Tower kernel: ata16: SError: { RecovComm Persist PHYRdyChg 10B8B }
Jun 25 20:00:35 Tower kernel: ata16: hard resetting link
Try to correct it by unassign and reboot then reassign, while it's rebuilding something happen and I end up had to uninstall all the drives hooked up to my Supermicro AOC-SASLP-MV8 8-Port SAS/SATA card and just boot up with the drives that's hooked up to the motherboard. Rebuild the parity so I can use those drives. I think there is something wrong with the PCI card or one of the drive is broke. How should I go about find out which one is causing the problem? Thanks for the help.
-
Use SeaTools and "Set Capacity to Max Native"
http://seagate.custkb.com/seagate/crm/selfservice/search.jsp?DocId=201271&NewLang=en
Be careful that your motherboard (Gigabyte) does not create a new HPA.
I don't have any PC here
I did boot up with my Mac with bootcamp but seatools get stuck on searching for devices......DOS version does not recognize the USB mouse and keyboard. I also tried HDD Factory Capacity Restore, it gave a an error about not able to restore the device. I am in the process of replacing my MoBo, so I am not going to reboot until I get that new MoBo. I am not sure if I can recover the data on that drive now. Unfortunately, I did initconfig and resync the parity of the drive I had working (did not want to lost what I still have). 4.7 update killed me
Is there any other way in regaining the full drive capacity, since I can't really save the data on the drive any more? Does simple reformat the drive work?
-
Anyone got recommendation in how to repair my harddrive that show less space then what it should be? Read a few post up please.
-
Yes, you can do it without losing data.
Try this:
hdparm -N p1953525168 /dev/sdf
Follow it with
hdparm -N /dev/sdf
to see if it took effect.
I had ran into HPA problem which did not surfaced until I updated to 4.7. I have a friend also had the same problem. I had 2 drives that reported problem after I updated to 4.7. I follow the above instructions and was able to correct one of the drive but the other drive is WD EARS 1.5TB without jumper on it
(did not know about the jumper until now). After I issue the commends to the WD drive it came back with only 409GB on the drive and I can't seems to be able to fix it./dev/sde: setting max visible sectors to 2930277168 (permanent) max sectors = 799570736/11041584, HPA setting seems invalid root@Tower:~# hdparm -N /dev/sde /dev/sde: max sectors = 799570736/11041584, HPA setting seems invalid root@Tower:~# hdparm -i /dev/sde /dev/sde: Model=WDC WD15EADS-00P8B0 , FwRev=01.00A01, SerialNo= WD-WCAVU0423882 Config={ HardSect NotMFM HdSw>15uSec SpinMotCtl Fixed DTR>5Mbs FmtGapReq } RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=50 BuffType=unknown, BuffSize=32767kB, MaxMultSect=16, MultSect=?16? CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=799570736 IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120} PIO modes: pio0 pio3 pio4 DMA modes: mdma0 mdma1 mdma2 UDMA modes: udma0 udma1 udma2 udma3 udma4 *udma5 udma6 AdvancedPM=no WriteCache=enabled Drive conforms to: Unspecified: ATA/ATAPI-1,2,3,4,5,6,7root@Tower:~# hdparm -I /dev/sde /dev/sde: ATA device, with non-removable media Model Number: WDC WD15EADS-00P8B0 Serial Number: WD-WCAVU0423882 Firmware Revision: 01.00A01 Transport: Serial, SATA 1.0a, SATA II Extensions, SATA Rev 2.5 Standards: Supported: 8 7 6 5 Likely used: 8 Configuration: Logical max current cylinders 16383 16383 heads 16 16 sectors/track 63 63 -- CHS current addressable sectors: 16514064 LBA user addressable sectors: 268435455 LBA48 user addressable sectors: 799570736 device size with M = 1024*1024: 390415 MBytes device size with M = 1000*1000: 409380 MBytes (409 GB)
I accidentally reformat the drive that I correct so I am in the process of rebuilding it. I had to unassign the WD EARS and initconfig the server to force it to resync.
My question is, is there a way to fix my WD EARS drive and rebuild the data somehow? I also order a different MB which will prevent HPA from being a problem in the future.
Update:
Further observation showed there are now 2 partitions on the WD EARS drive now?? I was able to mount one of the partition and access some of the data but I get errors
Feb 7 12:31:42 Tower kernel: attempt to access beyond end of device Feb 7 12:31:42 Tower kernel: sde1: rw=0, want=1423801160, limit=799570673 Feb 7 12:31:42 Tower kernel: REISERFS error (device sde1): vs-13070 reiserfs_read_locked_inode: i/o failure occurred trying to find stat data of [5 1323 0x0 SD]
root@Tower:~# fdisk -l /dev/sde Disk /dev/sde: 409.3 GB, 409380216832 bytes 1 heads, 63 sectors/track, 12691598 cylinders Units = cylinders of 63 * 512 = 32256 bytes Disk identifier: 0x00000000 Device Boot Start End Blocks Id System /dev/sde1 2 46512303 1465137496 83 Linux Partition 1 does not end on cylinder boundary.
So the question now is how did I get the 2 partitons with the original commend and how do i make it into 1 partition again?
Thanks for the reply!
-
NVM, I figured it out. Had to type http:// in front of it to make it work. Can't just type //tower/
-
Follow the instruction and still getting error? typed //tower/ in safari and the url becomes file://tower/ and error, no file exist. Any idea?

{kind=link}
Rebuild drive keep failing
in General Support
Posted · Edited by T3nchu
Not sure if this a hardware or software issue. I keep getting error when I try to rebuild a drive. I usually preclear the drive once. The rebuild would fail at different point each time. Thanks
syslog.txt