rhodo
Members
-
Joined
-
Last visited
-
Marking this topic solved. I discovered that the reason the cache drive filled up is because I recently installed a docker that was dumping a bunch of video files on the cache. The mover problem had been a longstanding (but unrecognized) issue caused by misconfigured mover settings of the docker/VM folders (appdata, domains, system). In case this helps anyone with cache drive issues, below is what I did to resolve this situation. STEP 1: CHECK --readonly -- This confirmed the data corruption on the cache drive -- This may have been caused by me attempting to manually delete files off the cache drive while it was in a self-imposed read-only state -- I since learned that btrfs will put itself into a read-only state to prevent further data corruption STEP 2: CREATE BACKUP OF CACHE DRIVE -- mkdir /temp -- mount -o rescue=all,ro /dev/sdX1 /temp (replace "X" with your drive letter) STEP 3: TRY SCRUB -- System in maintenance mode -- btrfs scrub start -Bd /mnt/cache -- Fails because file system is read-only STEP 4: CHECK WITH REPAIR -- Finds and repairs errors -- Takes file system out of read-only mode STEP 5: REBOOT STEP 6: SCRUB -- Confirms errors have been repaired and cache drive is now happy STEP 7: CORRECTLY CONFIGURE OFFENDING DOCKER -- The offending docker was p-streamrec. By default all its recording are placed in its appdata folder on the cache -- Enable docker -- Set data folder to reside on array -- Disable docker -- Use midnight commander to move its data off cache STEP 8: CORRECTLY CONFIGURE MOVER SETTINGS -- Set cache as primary and array as secondary for the appdata, domains and system folders -- Run mover
-
Thank you, JorgeB. I have successfully repaired the cache drive, and scrub is no longer reporting errors. However, the mover still refuses to move. It is still unhappy about these VM images on the cache. MOVER LOG Jun 8 08:22:50 phil move: mover: started Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/2025-05-03--generate.running No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/memory2025-05-03--generate.mem No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/vdisk1.2025-05-03--generateqcow2 No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/vdisk1.img No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/2025-06-07--generate.running No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Windows 10/vdisk1.2025-06-07--generateqcow2 No such file or directory Jun 8 08:22:50 phil move: move: /mnt/cache/domains/Ubuntu 24.04/2025-06-07--generate.running No such file or directory Jun 8 08:22:50 phil move: mover: finished NOTE: I was previously able to manually delete all of the Ubuntu VM files except the "--generate.running" one from the cache drive. The system is configured such that the domains folder should not exist on the cache drive. So I am puzzled as to why these files are on the cache to start with. Is it ok to simply delete these files now that the cache is not stuck in read-only mode? Alternatively, I am ok with simply removing and reinstalling these VMs if that will solve the problem.

-
I noticed recently that my cache drive was at 100% capacity. Mover would not move any files. I uninstalled Mover Tuning and mover still failed. The mover log indicated that the problem seemed to be related to VM images that were residing on both the cache drive and the array. I disabled VMs and was unsuccessful in my attempts to delete the images from the cache drive because they were read-only -- even after chmod-ing them to 755. In maintenance mode I check the file system of the cache drive and the output is below. [1/8] checking log skipped (none written) [2/8] checking root items [3/8] checking extents data extent[328848568320, 20480] referencer count mismatch (root 257 owner 260 offset 1215193088) wanted 0 have 1 data extent[328848568320, 20480] bytenr mimsmatch, extent item bytenr 328848568320 file item bytenr 0 data extent[328848568320, 20480] referencer count mismatch (root 321 owner 260 offset 1215193088) wanted 1 have 0 backpointer mismatch on [328848568320 20480] ERROR: errors found in extent allocation tree or chunk allocation [4/8] checking free space tree [5/8] checking fs roots [6/8] checking only csums items (without verifying data) [7/8] checking root refs [8/8] checking quota groups skipped (not enabled on this FS) Opening filesystem to check... Checking filesystem on /dev/sdg1 UUID: f296ff39-0784-48e7-a757-99d0ffd864d2 found 949109067776 bytes used, error(s) found total csum bytes: 837853060 total tree bytes: 1728331776 total fs tree bytes: 709705728 total extent tree bytes: 107560960 btree space waste bytes: 212508862 file data blocks allocated: 1332012232704 referenced 930064150528 After all of this, my Plex docker has stopped working. It's logs show the following: PMS: failure detected. Read/write access is required for path: /config/Library/Application Support/Plex Media Server Unraid version: 7.2.4 Thanks in advance! phil-diagnostics-20260607-1608.zip
-
Posting this here in case it might help someone. After getting my dockers back up I noticed that Plex refused to play several random video files through my Roku that played fine through the Plex web interface. Nothing seemed to help and there did not seem to be any pattern as to which files were affected. I even replaced the affected video files with fresh copies and they still didn't play through the Roku. All I got was the dreaded "Playback Error: Playback has stopped due to multiple playback errors. Please check your connection and try again". Out of desperation I consulted ChatGTP which came up with the below solution. The codec files in the Plex "Library/Application Support/Plex Media Server/Codecs" folder (located on the Unraid cache pool) may have been corrupted during the cache pool failure that I suffered. Recovering my cache pool and Plex docker did not detect/replace the corrupt codec files. After (1) stopping the Plex docker, (2) deleting all files in the Codec folder, and (3) restarting Plex (which automatically downloaded fresh codecs) everything worked normally again.
-
Using the GUI, I deleted the docker.img from the Docker settings and the libvirt.img from VM settings. That resulted in the Docker service starting. I was then able to restore the dockers from Apps > Previous Apps. I have not yet rebooted to see if the BTRFS errors are still showing up, but I have my dockers back, so, at least for now, I'm happy.
-
Scrub ended without errors: UUID: f296ff39-0784-48e7-a757-99d0ffd864d2 Scrub started: Thu May 22 14:05:55 2025 Status: finished Duration: 0:13:04 Total to scrub: 387.43GiB Rate: 506.03MiB/s Error summary: no errors foundI noticed that the Docker service has failed to start. Found this in the syslog: May 22 15:13:01 phil root: mount: /var/lib/docker: can't read superblock on /dev/loop2. May 22 15:13:01 phil root: dmesg(1) may have more information after failed mount system call. May 22 15:13:01 phil root: mount error May 22 15:13:01 phil kernel: BTRFS error (device loop2): open_ctree failed: -5 phil-diagnostics-20250522-1513.zip
-
Awesome! This brought my cache drive back. Is it now safe to recreate my dockers and VMs? I tried to recreate my Plex docker while the RAM was still corrupt, so that may be a goner. I understand I may need to reinstall Plex from scratch. I am hoping I can do a reinstall of the other dockers and preserve the data I had. Can the VMs be recovered? I had snapshots. If not, no biggie. Thanks again!!! phil-diagnostics-20250522-1352.zip
-
Diagnostics attached. Appreciate your assistance with this. phil-diagnostics-20250522-1336.zip
-
I have added new RAM, booted into Unraid and started the array. The cache drive is listed as "Unmountable: Wrong or no filesystem". Please let me know what would be the next steps to get thing up and running again. Thanks.
-
Memtest found a ton of errors. I am ordering new ram. When I went to scrub the cache drive I find that it is now listed as unmountable. Any way to recover it? Updated diagnostics attached. Thanks for your help. phil-diagnostics-20250520-1257.zip
-
I am running Unraid 7.1.2. Every few days the docker service crashes. I am getting BTRFS errors from my cache drive in the log. I have deleted the docker.img file but that has not resolved the problem. It is image file is 50GB so I have not attempted to make it any larger. I ran the "Check Filesystem Status" on the cache drive and it found errors, so I ran it in repair mode. The errors were repaired and the system rebooted fine. But after several days the docker service crashed again. The cache drive is a 6yo Samsung EVO 870 1TB SSD. If these errors are a sign that the drive is dying then I will replace it. Thanks! phil-diagnostics-20250520-0847.zip
-
Recently suffered a power outage while I was away for the Thanksgiving weekend. While most of my machines came back up without issue, my Win10 VM on unraid was hosed. I just finished creating a new Win10 VM and Googled "unraid vm snapshot" which brought me here. In my eyes, VMs are a core feature of unraid, along with mass storage and dockers. Please make this feature a higher priority.
-
Why do the containers have different IP's (54, 55, 56)? They would normally all have the same IP as the UNRAID server, just each on a different port
-
Just writing to confirm the experience of DuzAwe -- Docgyvers SSH plugin solves the issue of not being able to ssh into unraid v6.11.1 using key exchange. I have a number of scripts that rely upon being able to ssh into unraid without a password. These worked fine until upgrading unraid. I tried all the fixes I could find in these forums without success. The unraid syslog.txt gave the error: Authentication refused: bad ownership or modes for directory / Weird, since I had already set permissions to 700 for the .ssh directory and 640 for the .ssh/authorized_keys directory as part of my troubleshooting the issue. Anyhow, the plugin places an SSH icon in Settings > Network Services. Just open it and hit "Apply" without changing anything. Now everything just works.
-
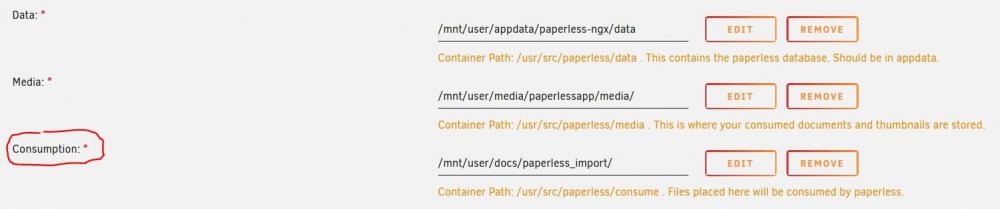
No... Not the data folder. The consumption folder is placed in a public unraid share that is accessible on the LAN. In my case, the unraid "docs" folder is a public folder that is accessible to everyone on the LAN. Inside this folder I placed the "paperless-import" folder. Anyone can drop files into that folder and they will be imported to paperless.