




xinil
Members
-
Joined
-
Last visited
Everything posted by xinil
-
Thanks trurl, very enlightening! That answers my question perfectly. Follow up question - is the only way to 'fix' the redundancy issue to replace the missing disk? Can I remove the disk someway to rebuild the metadata without it? Pros/cons, would take too long, not worth struggle (e.g. just get another disk?) Thanks!
-
Hello I'm running 6.11.5 (haven't bitten the bullet for 6.12.# yet, but SOON. I have two 14tb parity drives. Last week one of my array 6tb drives with zero data (clicking on 'View icon' in 'Main' screen array devices area shows zero files/folders) stopped showing as installed/available. I don't have any other 6tb drives on hand so I added a new 14tb drive to my array. Wouldn't you know it, as soon as I spin the server back up one of my other 14tb array drives starts making crazy squealing/clicking noises. So now two drives are dead, fml. I remove the faulty 14tb drive, reboot and reassign the new 14tb to the previous failed disk #. I now have a 'Data-rebuild in process' with about 2days needed to complete. This all makes sense to me. What I don't understand is the warnings I see on my "Shares" screen saying "Some or all files unprotected." I've technically lost two drives, but only one had data (~11tb) and the other had none (6tb empty.) Why cannot my parity safely emulate the data without there being an unprotected phase while data rebuild is in progress? Current array screen, Disk 6 is the faulty 6tb I haven't removed from the array yet. Disk 1 is the new 14tb rebuilding.
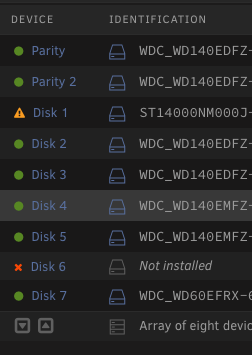
-
Just wanted to chime back in on progress info. I've replaced one NVME SSD (the most recent one with errors) and switched to a different adapter card for the other NVME SSD. It's been 48 hours and not a single error has occurred yet. Crossing fingers it was just hardware that needed swapping! If I don't reply again, assume everything is fixed!
-
I wiped the nvme1 drive, rebalanced with the nvme0 (uncorrupted). Rebooted and within about an hour seeing errors again on nvme1. [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 [/dev/nvme1n1p1].write_io_errs 368768 [/dev/nvme1n1p1].read_io_errs 26856 [/dev/nvme1n1p1].flush_io_errs 3918 [/dev/nvme1n1p1].corruption_errs 0 [/dev/nvme1n1p1].generation_errs 0 This is what I have in the Linux config default menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label Unraid OS menu default kernel /bzimage append initrd=/bzroot nvme_core.default_ps_max_latency_us=0 pcie_aspm=off label Unraid OS GUI Mode kernel /bzimage append initrd=/bzroot,/bzroot-gui nvme_core.default_ps_max_latency_us=0 pcie_aspm=off
-
Ok, done, but before I reboot, is there any guidance on what to do with this situation? root@StreamingTower:~# btrfs dev stats /mnt/cache [/dev/nvme1n1p1].write_io_errs 47025602 [/dev/nvme1n1p1].read_io_errs 20207911 [/dev/nvme1n1p1].flush_io_errs 462569 [/dev/nvme1n1p1].corruption_errs 6 [/dev/nvme1n1p1].generation_errs 0 [/dev/nvme0n1p1].write_io_errs 0 [/dev/nvme0n1p1].read_io_errs 0 [/dev/nvme0n1p1].flush_io_errs 0 [/dev/nvme0n1p1].corruption_errs 0 [/dev/nvme0n1p1].generation_errs 0 Scrub with repair produces: UUID: 03b3fe98-f7a1-4dc4-b69b-661202e041e1 Scrub started: Fri Jan 27 13:06:14 2023 Status: finished Duration: 0:04:07 Total to scrub: 137.79GiB Rate: 571.23MiB/s Error summary: read=17972852 super=3 Corrected: 0 Uncorrectable: 17972852 Unverified: 0 Should I disconnect nvme1 and do what I've always done?: Rebuild with the non-corrupted drive.
-
It's not always the same one. You can see in my first post it mentions nvme0n1p1 with the errors (from a past issue I saved), but in the logs it's now nvme1n1p1. It seems to 'focus' on one for a good while (it was months last time before 'both' became corrupted.
-
Shoulda included that in the first post, apologies, here they are. xtower-diagnostics-20230127-1101.zip
-
Hey all. First time poster, long time Unraid user. A few years ago I set up a streaming/automation server with 3 dockers (plex/jellyfin/telegraf) and 1 vm (home assistant). This have worked ‘well’ for a while, but for at least the past year I’ve been fighting a BTRFS cache pool corruption problem. The server works wonderfully….so long as I do not reboot. As soon as I reboot the VMs/Dockers will not start. My cache shows like this: [/dev/nvme1n1p1].write_io_errs 0 [/dev/nvme1n1p1].read_io_errs 0 [/dev/nvme1n1p1].flush_io_errs 0 [/dev/nvme1n1p1].corruption_errs 0 [/dev/nvme1n1p1].generation_errs 0 [/dev/nvme0n1p1].write_io_errs 1408272649 [/dev/nvme0n1p1].read_io_errs 820356362 [/dev/nvme0n1p1].flush_io_errs 40914172 [/dev/nvme0n1p1].corruption_errs 1630001 [/dev/nvme0n1p1].generation_errs 15037 So my ‘fix’ for this corruption (that I've done maybe 3 times in as many months) was to remove corrupted nvme0n1p1 from the pool, start the array, add it back to the pool (overwriting corrupted data) and then rebalance with the clean nvme1n1p1. The problem recently has been at some point BOTH nvme drives have started to become corrupt. Performing a scrub with ‘repair corruption’ checked does not fix the issue (even if I do it immediately after errors are detected. I installed a user script to monitor btrfs dev stats /mnt/cache so I’m aware of when the errors appear (usually many a day.) What can I do? I ‘ve read on these forums that it could be memory issues. So I ran a memtest (free version 4 pass, came out 100% pass zero errors.) I’ve read it could be cable issues. But these are m.2 nvme drives, one connected directly to the motherboard and another connected via a PCIe 3.0 x4 adapter card. I’ve tried the latency change in the Linux config as well. Temps do regularly spike around 50-60C, but I figured that’s within normal range? One card is a Pony 1tb and another is Team 1tb. Any advice would be greatly appreciated. I’m on Unraid 6.11.5.

