




Earan
Members
-
Joined
-
Last visited
-
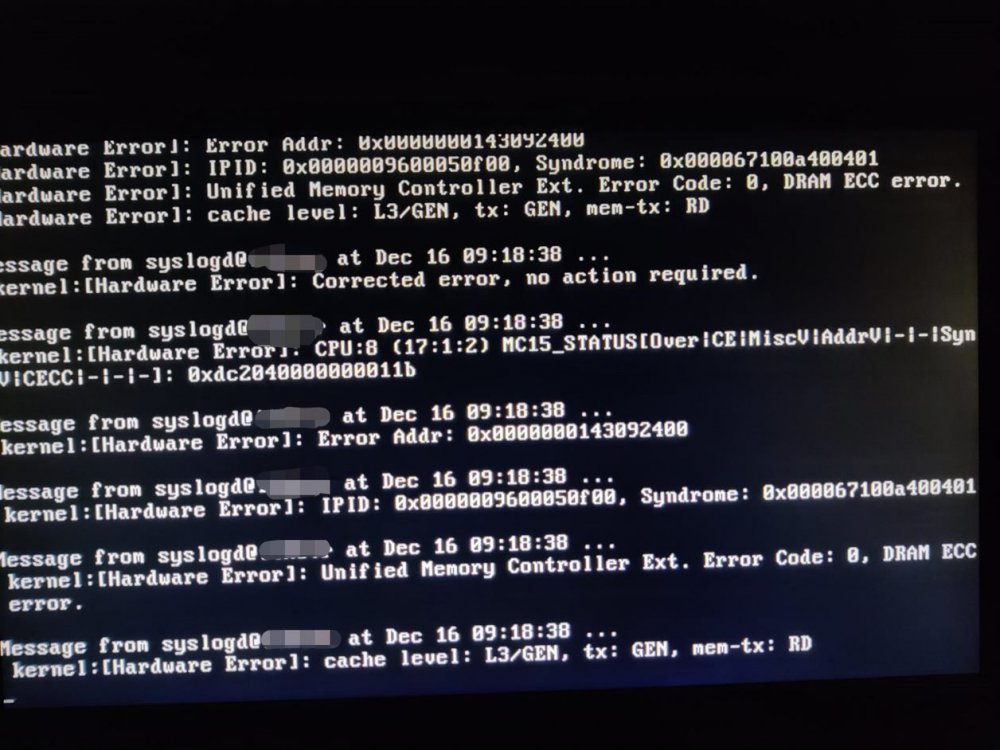
Neither on the CLI with IPMITool from the Nerdpack, nor with the IPMI support plugin can I see any RAM Related issues. Downloading the full syslog I see quite a few events like the one on the screen, but all of them say, [Hardware Error]: Corrected error, no action required. also not really stating which RAMslot it is, or atleast, I cannot make it out. this is one full event: Dec 16 21:46:50 itXsvr kernel: mce: [Hardware Error]: Machine check events logged Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: Corrected error, no action required. Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: CPU:8 (17:1:2) MC15_STATUS[Over|CE|MiscV|AddrV|-|-|SyndV|CECC|-|-|-]: 0xdc2040000000011b Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: Error Addr: 0x0000000143092400 Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: IPID: 0x0000009600050f00, Syndrome: 0x000067100a400401 Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: Unified Memory Controller Ext. Error Code: 0, DRAM ECC error. Dec 16 21:46:50 itXsvr kernel: EDAC MC2: 1 CE on mc#2csrow#1channel#0 (csrow:1 channel:0 page:0x973092 offset:0x400 grain:64 syndrome:0x6710) Dec 16 21:46:50 itXsvr kernel: [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD
-
Hi Everyone, for a while now, my unraid server throws hardware errors, every now and then, which seem to be RAM related. I recently saw this on the screen it's attached to: Here's the parts that I'm using: Supermicro MBD-H11DSi-NT-B 2x AMD Epyc 7301 8x16 GB of Kingston Server Premier KSM26RD8/16HAI DDR4-2666 regECC One RAM stick seems to have issues, since the server reports as 112GB of Memory sometimes, and not 128GB after a reboot. How do I find out which RAM stick it is, since those errors come up infrequently? Are there other issues in the logs on the screen?
-
First, the following is my opinion, my experience and my understanding of how things went wrong. My conclusions of how things work, and why things failed, might be utterly wrong, but this is how I solved it. Feel free to enlighten me if I got technical things wrong. So as it turns out, it was an issue with the SSDs caching strategy, or rather, how inadequate Quad Level Cell (QLC) SSDs are for "heavy" VM usage. The SSD in question, the QVO 860 2TB from Samsung has a 2GB DRAM Cache, 6GB of dedicated SLC Cache, and a dynamic 72GB SLC Cache which it takes from the 2TB of main storage. The dynamic Cache obviously is scaled down as the free space gets smaller. To resolve my slowdown issue, I added another SSD to the system, and mounted it via the Unassigned Devices Plugin, so it was free to use however I wanted. It was only 120GB in size, but that's enough to move atleast 3 of my Windows VMs on there. And while it isn't the best performance I've ever seen, since it's quite an old one already, it outperformed the cache drive by a lot in it's current state. After cleaning the images from the cache for these 3 VMs, and also delete a few others which I didn't need necessarily, I got the cache drive down to 70% usage at which point it started to behave normal again. The other VMs sprung back to life, being super responsive again. Great I thought, fixed the problem, so I did some Updates on the VMs at which point everything slowed down again. At this point, I've apparently done enough writes and deletes on the drive for the day, that the caches of the drive were full, and its only option was to directly write to the main QLC storage. After midnight, which is when I got the daily TRIM setup via the Dynamix SSD TRIM Plugin, I looked at the Drive Log and saw that it had "trimmed" 575GiB (617GB) of storage, which was all of the remaining free storage. This means, that this slowdown happened, because the drive is not only directly writing to QLC space, but also has to delete old stuff first, before being able to write, which is slower than normal write, from what I've read. I wouldn't have expected it to become 5MB/s slow though. After that Trim, everything went back to normal again. I am now monitoring the situation, and another 512 GB MLC SSD is underway to replace that smaller 120GB drive so that the cache drive will have more free space to work with. Also need to look into what exactly is causing most of the garbage that gets trimmed every night, and try to reduce that, not only for performance, but also longevity.
-
Hi, I'm currently trying to troubleshoot a severe slowdown problem that I have. in short, I have a unraid server on a dual socket Epyc 7301, 128Gb of ram 4 4TB WD Gold drives, and a 2TB QLC Samsung SSD as a cache drive. On that we are running several containers, Gitlab, nextcloud a few mysql dbs, and also quite a few VMs, some Windows machines, a few linuxes, 23 VMs in total. The containers and VMs are stored on the cache drive only to increase speed. Only a select few running all the time, and most being shut down most of the time. With all that, we got 1.5 TB of those 2TB of the cache drive filled. A few weeks ago, I noticed a severe slowdown in everything but Gitlab (which probably stems from them using in-memory DBs). All the DB containers, all the VMs are multiple times slower than what we were used to, almost rendered useless. One thing that happened before the slowdown, was that I accidentally duplicated one of the VM disks on the cache drive, which resulted in the drive being completely full. I removed it, and brought it back to where it was, and nothing happened directly after that, the slowdown set in later. Also one more thing I noticed is, that now the nightly scheduled TRIM of the SSD apparently trims 100-120GB each night, be it weekdays or weekends. Does anyone know, either what the reason for the slowdown is, or where/what I can look into? Unraid is at 6.9.2 Cache fs is btrfs Array fs is xfs
