

-
Posts
55 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by rainformpurple
-
 Cool, thanks.
Cool, thanks. -
Yeah, no, me neither Here's basically what I did: 1. Stop array & shut down server 2. Add drive cage with 3x18TB drives 3. Start server 4. Unassign 6TB parity drive 5. Assign 18TB as new parity drive 6. Start array in maintenance mode & rebuild parity for 25 hours 7. Stop array 8. Assign new 2x18TB drives + old 6TB parity drive to array 9. Start array in normal mode, let disk sync run for 27 hours I haven't stopped the array since the disk sync.
-
Sure: The drive is currently a member of the array, is active and works fine. The other three 18TB drives I installed also showed up under HistDev, and I was able to remove those by clicking the X.

-
Drive stuck under Historical Devices
rainformpurple replied to rainformpurple's topic in General Support
Thanks, I've reposted in the support thread. -
Hi all, I recently upgraded my server with more storage space, and decided that in order to maximize storage space, I would add the old 6TB parity drive as a storage drive alongside the new drives. Apart from a DOA drive, this went well and after 25 hours of parity rebuild followed by 27 hours of disk clear/parity sync, everything works. However, the old parity drive, which obviously was known to the system, is now stuck in Historical Devices. The Remove button/cross doesn't work and is white rather than red. When I point to it, the cursor doesn't change, indicating there is no link to whichever function will trigger when clicked. Is this something a reboot will fix? Or stop the array, remove drive from HistDev, then restart the array? If so, I'll just leave it until my replacement 18TB arrives, as I will have to stop the array to add the new disk at that point anyway.
-
Hi all, I recently upgraded my server with more storage space, and decided that in order to maximize storage space, I would add the old 6TB parity drive as a storage drive alongside the new drives. Apart from a DOA drive, this went well and after 25 hours of parity rebuild followed by 27 hours of disk clear/parity sync, everything works. However, the old parity drive, which obviously was known to the system, is now stuck in Historical Devices. The Remove button/cross doesn't work and is white rather than red. When I point to it, the cursor doesn't change, indicating there is no link to whichever function will trigger when clicked. Is this something a reboot will fix? Or stop the array, remove drive from HistDev, then restart the array? If so, I'll just leave it until my replacement 18TB arrives, as I will have to stop the array at that point anyway.
-
RandomNinjaAtk *arr-extended docker containers
rainformpurple replied to rainformpurple's topic in General Support
I can definitely empathise with his reasons, but it was very sudden. Hopefully someone else will pick it up and continue the builds. -
Hi, I couldn't find any support threads for randomninjaatk's docker containers (lidarr-extended, radarr-extended, sonarr-extended), so I'll try here. I'm running lidarr-extended and sonarr-extended and they now appear as "Not available" in my docker list. They are also removed from Community Apps and I can't find them on Docker Hub anymore either. The GitHub page at https://github.com/RandomNinjaAtk/docker-sonarr-extended states that the repo is deprecated and will be archived. I guess that goes for lidarr-extended and radarr-extended as well. Does anyone know the reason for this? Is there a replacement for these docker containers? The extended features of these containers were really useful in grabbing Youtube series and things like that, and it's too bad randomninjaatk decided to deprecate the containers.
-
Yeah, it was a rollercoaster. I thought I'd get away with a quick 30 minute upgrade, but it turned into a 4 hour forensics job. Today I've been slowly fixing docker issues that popped up because I forgot that newer versions of unRAID weren't happy about how things were on 6.9. As I don't trust automated scripts I don't know what actually do, I'm changing the permissions by hand for the shares I know I have to change, and then I'll see about the rest later, if at all necessary.
-
Yeah, that went straight to hell in a handbasket. Upon rebooting into the supposedly upgraded system, the console starts spewing error messages stating GLIBC_2.34 cannot be found (required by rm and sleep). My USB key has also been blacklisted for some reason, and no dockers nor VMs are started. The WebUI is only half-way functioning and doesn't display any meaningful data (no disks show up, no server stats, no plugins show up, no controls work, nothing. Exactly what I was afraid of what would happen, in other words. I'm not saying it's related to the tailscale plugin in any shape way or form, just to make that clear. Currently trying GUI safe mode to see what's going on and to see if I can get it working enough to contact Limetech support to have un-blacklist my USB drive. Edit 1: Downgrading to 6.9.2 got rid of the error spewing, and it appears my USB drive isn't blacklisted anymore... I'm not entirely sure what's going on, but something isn't right. As a curious aside, the tailscale plugin now works and I've re-registered my server with the Tailscale mothership and everything works as expected. Edit 2: I couldn't let this lie and had to tinker with it. I nuked all my plugins and now it works with 6.11.5, so I'm adding back the plugins one by one to see which (if any) breaks my server. Edit 3: The culprit is a user script I have written, which tries to install some packages and that breaks everything, requiring a hard reboot to get out of. The script is now disabled and things look fine. Edit 4: The problem was that I for some ducked up reason installed a package named aaa_glibc_somethingsomething.txz that apparently worked enough on 6.9.2 to allow the audio tools I installed via the same script to work. That caused various problems when installed on 6.11.5, as the installed version of glibc is newer. After booting into safe mode a number of times I have verified that this was indeed the cause and that package is no longer installed on boot. I'm currently working my way through the list of packages to find compatible versions, and I feel that this is something that maybe could be installed via Nerd Tools. The mismatched glibc also caused all the other problems with the unRAID WebUI, registration retrieval status, network issues, etc. My USB key is not blacklisted, the mismatch caused the verification to fail miserably and probably receiving garbage data back, leading it to think that the USB key was blacklisted. That is sorted now and everything works. In any case, my server is now finally upgraded to 6.11.5 and the tailscale plugin works perfectly
-
The plugin didn't make any difference, so I'm currently upgrading my server to 6.11.5, which I should've done many moons ago anyway. I'll report back once the upgrade is complete.
-
Yeah, I keep putting off updating, because I never seem to find the time to deal with eventual problems that may arise by doing so. I should probably just do it. Some day. I'll install the Unassigned Devices Preclear plugin and see if that fixes it temporarily. Thanks!
-
Sure thing. aram-diagnostics-20230510-1429.zip
-
I just converted my 6.11.5 server from the Docker container to the plugin and it worked flawlessly. However, when trying to do the same on my 6.9.2 server at home, I get this: # tailscale up failed to connect to local tailscaled; it doesn't appear to be running I then uninstalled and reinstalled the plugin: plugin: installing: https://raw.githubusercontent.com/dkaser/unraid-tailscale/main/plugin/tailscale.plg plugin: downloading https://raw.githubusercontent.com/dkaser/unraid-tailscale/main/plugin/tailscale.plg plugin: downloading: https://raw.githubusercontent.com/dkaser/unraid-tailscale/main/plugin/tailscale.plg ... done plugin: downloading: https://pkgs.tailscale.com/stable/tailscale_1.40.0_amd64.tgz ... done plugin: downloading: https://raw.githubusercontent.com/dkaser/unraid-tailscale/main/packages/tailscale-utils-2023.04.26a.txz ... done +============================================================================== | Installing new package /boot/config/plugins/tailscale/tailscale-utils-2023.04.26a.txz +============================================================================== Verifying package tailscale-utils-2023.04.26a.txz. Installing package tailscale-utils-2023.04.26a.txz: PACKAGE DESCRIPTION: Executing install script for tailscale-utils-2023.04.26a.txz. Package tailscale-utils-2023.04.26a.txz installed. starting tailscaled... plugin: tailscale.plg installed Updating Support Links Finished Installing. If the DONE button did not appear, then you will need to click the red X in the top right corner ...and then tried tailscale up once more: # tailscale up failed to connect to local tailscaled; it doesn't appear to be running Still no juice. Is there a way to start tailscaled manually in a way that it will restart automatically on boot? I'd really like to avoid rebooting the server as it's in use. I've started tailscaled with # tailscaled & (to run it in the background) and then # tailscale up That works, but I'm not feeling confident that it will restart on system reboots.
-
Hi, I've run into a weird problem. Actually, I've had this problem for a while now, but it's now gotten to the point where it is really starting to annoy me. At home I have an unRAID 6.9.2 server that should probably be upgraded, but it's working mostly fine so I don't want to rock the boat too much. The server is accessible from wherever I am via Tailscale (previously via VPN), so naturally I administer it from work, as that's when I actually have the time to do such things. At work I have a 6.11.5 server that's basically just a backup dump site for data I prefer not to lose. However, whenever I create/modify/update a docker container or a plugin on my home server from work, I get a white progress dialog on my screen in lieu of the output from the commands being ran in the background. Everything works, it's just not able to show me what it's doing. Screenshot: The most curious thing is that it works fine when I'm at home. Always has. It's just when I use my workstation in the office that this happens. As you can see in the screenshot, there is a light band that goes across the screen. I get that at home too, but at least the progress dialog shows what's going on. That band is only visible on the home 6.9.2 server, not on the work 6.11.5 server. At work I'm using the latest version of Firefox on Windows 10 22H2. I do have a number of addons installed, all of which have been disabled and then reenabled one by one to see if I could catch the offender. No luck. It's the same in Chrome and Vivaldi. All browsers have been run in private/incognito mode and there is no change in behaviour. The backup 6.11.5 server does not display such anomalies in behaviour. Workstation: Dell Precision Tower 3620 Core i7-6700 64GB ram Nvidia Quadro M2000 graphics card Windows 10 22H2 Firefox 112 with these addons: AdBlocker Ultimate Bitwarden cookies.txt Dark Reader Facebook container Honey I still don't care about cookies Return Youtube Dislike SponsorBlock for YouTube Tampermonkey Torrent Control Translate Now uBlock Origin Privacy badger Sync tab groups Home laptop: Lenovo Thinkpad T480s Core i7-8665 40GB ram Onboard Intel graphics Linux Mint 20.3 Firefox 112 with these addons: AdBlocker Ultimate Bitwarden cookies.txt Dark Reader Facebook container Honey I still don't care about cookies Return Youtube Dislike SponsorBlock for YouTube Tampermonkey Torrent Control Translate Now uBlock Origin Privacy badger Sync tab groups The Google machine indicates that this is a problem that has persisted for quite a few years and that reportedly was fixed back in the 6.3/6.4 days, so I'm wondering what has triggered this on my computer. And, more importantly, how to make it go away.
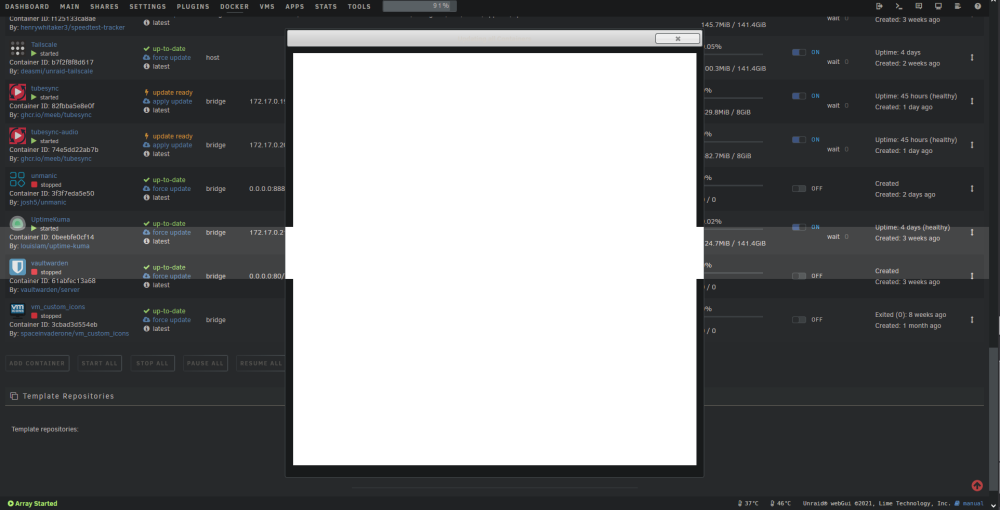
-
Update Container - no progress in window
rainformpurple replied to stormshaker's topic in Docker Engine
I have this issue as well, on one of my servers. At home, I run a 6.9.2 server, and updating docker containers from my Linux Mint laptop in Firefox works fine. I can see the update text rolling by as the update is performed. There is a white band across the screen that I have no idea where comes from, but it may be an artefact of a Dark Mode addon I use. At work, running Windows and connecting over a VPN link, also using Firefox - with the same addons installed and basically the same profile - the update dialog is white and no text is seen as the update is performed. On my backup server, hosted at work, running 6.11.5, I have no problems with updating from either client. -
I just tried this, and it still works. It's amazing how infuriatingly difficult Microsoft insists on making every single thing just because, when things do not need to be this hard. In any case, I just wanted to extend a heartfelt THANK YOU for this. Absolute legend!
-
[SOLVED] WebUI and docker issues, unRAID 6.9.2
rainformpurple replied to rainformpurple's topic in General Support
I figured this one out as well, with help from other posts on the forum. The culprit was that "Enable bonding" was, well, enabled. As I replaced a disk last night and everything else has been down most of the day, I figured I'd look into the network settings again based on posts I found when searching. Disabling bonding solved the issue - I now have the option to use "Custom: br0" as a docker container network and can thus once again assign static IP addresses to docker containers. -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
Disk reconstruction has completed with no errors! It took about 9,5 hours, but that's fine. All's well that ends well. Again, a big thank you to all who responded! -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
Yep, it looks pretty much like it did on Saturday, so I think this will be fine. I'll still keep the docker containers stopped until the reconstruction is complete just to ease my paranoia. The fewer things that can go wrong at the same time, the better -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
Time for an update. The failed disk has been pulled and the new one installed. The disk's contents are being reconstructed as we speak and is estimated to take just shy of 8 hours. So far, so good. The VMs are running as I need them for DNS and adblocking and things of that nature, but I'll leave the docker containers disabled for now and deactivate tonight's Mover run as well, to make sure no new data interferes with the reconstruction. Thanks for all your help, highly appreciated. -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
That's the plan, I am just waiting to get home from work While I wait, is it safe to cancel the parity check? As I understand it, the chances of it completing at this point are slim to none. -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
Okay, SMART data collection is done: root@aram:~# smartctl --all /dev/sdc smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.10.28-Unraid] (local build) Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: HGST Product: HUS726060AL5210 Revision: A907 Compliance: SPC-4 User Capacity: 6,001,175,126,016 bytes [6.00 TB] Logical block size: 512 bytes Physical block size: 4096 bytes LU is fully provisioned Rotation Rate: 7200 rpm Form Factor: 3.5 inches Logical Unit id: 0x5000cca2424dba1c Serial number: NAHBS4ZY Device type: disk Transport protocol: SAS (SPL-3) Local Time is: Tue Mar 7 10:29:31 2023 CET SMART support is: Available - device has SMART capability. SMART support is: Enabled Temperature Warning: Enabled === START OF READ SMART DATA SECTION === SMART Health Status: FIRMWARE IMPENDING FAILURE DATA ERROR RATE TOO HIGH [asc=5d, ascq=62] Current Drive Temperature: 48 C Drive Trip Temperature: 85 C Manufactured in week 52 of year 2015 Specified cycle count over device lifetime: 50000 Accumulated start-stop cycles: 621 Specified load-unload count over device lifetime: 600000 Accumulated load-unload cycles: 2578 Elements in grown defect list: 509 Vendor (Seagate Cache) information Blocks sent to initiator = 9574154483269632 Error counter log: Errors Corrected by Total Correction Gigabytes Total ECC rereads/ errors algorithm processed uncorrected fast | delayed rewrites corrected invocations [10^9 bytes] errors read: 0 1690116 0 1690116 41747712 206550.071 89 write: 0 47 0 47 2831239 32983.083 0 verify: 0 42893 0 42893 119043714 9119.288 49 Non-medium error count: 399 SMART Self-test log Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ] Description number (hours) # 1 Background short Completed - 45459 - [- - -] # 2 Background short Completed - 45459 - [- - -] Long (extended) Self-test duration: 48442 seconds [807.4 minutes] -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
I'm trying to retrieve SMART data from the drive, but it's taking its sweet time... -
[SOLVED] Parity check takes forever
rainformpurple replied to rainformpurple's topic in General Support
Yes, the previous check 2 months ago completed with no errors.




