

Christopher
-
Posts
35 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Christopher
-
-
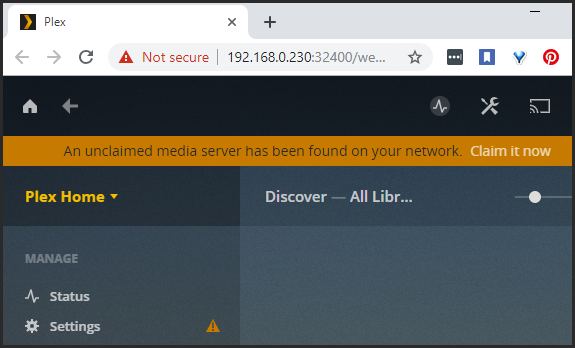
I'm having an issue where my Plex Server no longer being recognized. Plex is seeing my server as a new instance with a message on top saying, "An unclaimed media server has been found on your network. Claim it now". My Libraries are missing because it think it's a new server. Here's what led up to this below...
1) I had several cache drive BTRFS errors in my log. Docker apps to would stop or not respond.
2) Searched the forums and found post with similar issues. I tried a few things to fix it with no success.3) I decided to recreate my cache drive. I disabled docker and VM and moved all cache folders/files to the array.
5) I cleared my cache configuration and deleted partitions on those my 4 cache SSDs.
6) I setup the 4 SSD drives as cache again and formatted.
7) Copied all files back to the cache
array.") Restarted server.
Restarted server.
9) Deleted my docker.img
10) Enabled docker. Docker created new empty docker.img11) Installed Plex from previous Apps. Config pointed to original folders
12) Started Plex
Any ideas?
Is there a way to get Plex to see this as my original instance?
If I proceed with this new instance and add existing libraries, will Plex automatically use the existing database/files in my config folder?
If I proceed with this how will it effect my Tautulli database?
Your help is appreciated!
-
Thanks for your pgAdmin4 template. Do you have any plans to upgrade from pgAdmin4 version 2.1 to the latest 3.4?
-
+1.
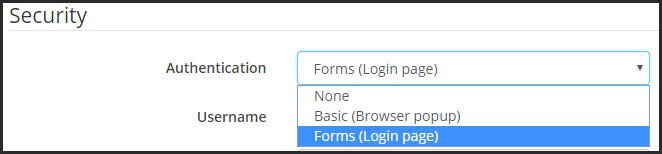
Maybe unRaid can have an option to login with basic http authentication or a forms login page. Sonarr has this option.
-
 1
1
-
 1
1
-
-
I figured it out. I assumed the default user in the container was jovyan so I didn't set it. After reading the docs again, I explicitly set the NB_USER and now it works.
Extra Parameters:
--user root -e NB_USER="jovyan" -e NB_UID="1000" -e NB_GID="100"
-
I'm trying to mount a local unRAID appdata folder to the working folder in docker container jupyter/scipy-notebook. The container runs and works fine except my work is not being saved to my volume mount. I believe the problem has to do with incorrect values in the "Extra Parameters" section for the User Id and Group Id. I've tried 99 and 0 as values. Can anyone help me get this working? Your help is appreciated! Thanks!
Documentation for volume mounts on this image:QuoteHost volume mounts and notebook errors
If you are mounting a host directory as
/home/jovyan/workin your container and you receive permission errors or connection errors when you create a notebook, be sure that thejovyanuser (UID=1000 by default) has read/write access to the directory on the host. Alternatively, specify the UID of thejovyanuser on container startup using the-e NB_UIDoption described in the Common Features, Docker Options section2Docker Options for this Image:
https://jupyter-docker-stacks.readthedocs.io/en/latest/using/common.html#Docker-Options
My Configuration:
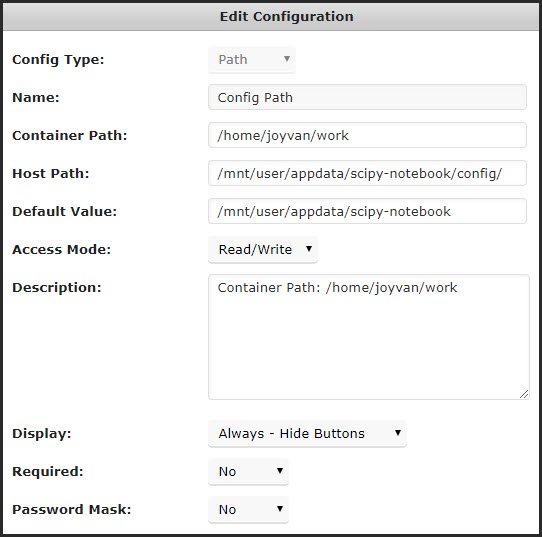
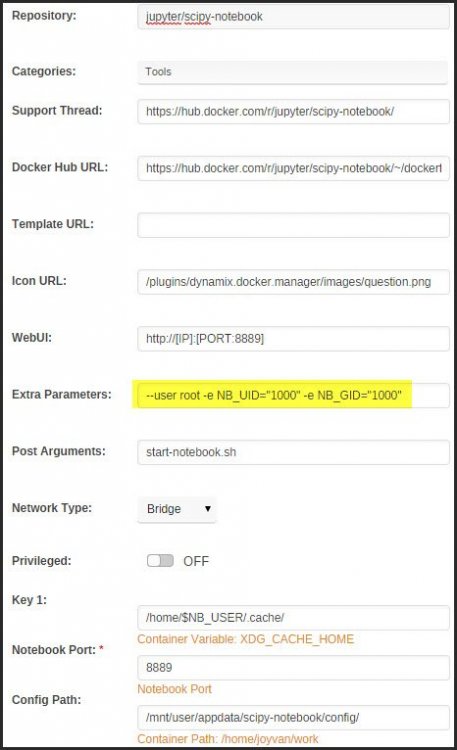
-
-
A Friend let me borrow a smaller drive and I was able to complete the process. Thanks for you help!
-
The parity drive I want to use to restore disk13(3TB) is 4TB. I would like to replace disk13(3TB) with a new drive but my only spares are 5TB. Is there anyway I can make the 5TB appear to be 4TB or 3TB? This is just temporary so I can rebuilt disk13.
Thanks,
Christopher
-
One big difference between RAID5 and unRaid is that with RAID5, the redundancy is always correct. With unRaid, a user has the power to slap in a parity drive, tell unRaid to trust it, and then the array work for months or years with no data corruption and appears all is great. Until a drive fails and unRaid's simulation of it is crap. Unless you run a parity check, you would never be able to tell that parity is totally useless!
Be careful trusting parity! As suggested, rebuilding it might be smarter than trusting it. But if you think the old parity is close, trusting it should be fine so long as you immediately do a correcting parity check and allow it to correct some of the parity blocks. This could be faster than a complete rebuild.
Thanks for the info bjp999!
If its an old parity drive, why would you want unRaid to trust it? The data on it is going to be invalid. You're going to be better off not trusting it and having unRaid build the parity info on it.
Here's the reason why I want to do this:
[*]Initial state of my server was perfect. I had just done a parity check and all was well.
[*]I upgraded my parity drive from 4GB to 5GB, Unraid started building parity.
[*]In the morning I saw disk13 was redballed and parity build did not complete. Nothing has been copied/deleted/edited to the server since.
I did not trust my old parity because events happened between steps 1 and 2 that wasn't sure about and I don't recall the details of. So I used reiserfsck to recover disk13 data and it restored about 2/3 of it. I copied the restored data to a local disk on my PC. Now I want to try to rebuild disk13 from my old parity. I realize that it the parity info might be invalid. But I wanted to give it a shot.
Once I rebuild it I want to do an md5 comparision with the reiserfsck recovered data.
Can you point me to the procedure?

Thanks,
Christopher
-
My system currently doesn't have a parity drive. I want to install an old parity drive and have unraid trust it. When I start the array with the old parity drive I want this think everything is normal.
Can someone point me to the link for this procedure?
Thanks,
Christopher
-
Is the above guess about disk13 being red-balled and there being problems with either the parity disk or another data disk valid?
Your right on both points. Thank you very much for your explanation!
-Christopher
-
I'm not having any serious issues I need help with. I just want to understand how the following works:
1) I used reiserfsck to recover data from a disk13
2) reiserfsck recovered 2/3 of the files and created a lost+found folder.
3) I followed the 'Trust My Array' procedure to reset my entire array.
4) I reassigned all the disks to the same slots minus the parity drive. I matched all serials to the old slot and triple checked against a screenshot. Yes, i'm unprotected.
5) I started the array.
6) Now my disk13 shows the original file structure with 100% of the files. I tested a few files that were missing after the reiserfsck rebuild and they work fine.
My assumption was that disk13 would still show the reiserfsck rebuilt folder/file structure even after the 'Trust My Array' procedure.
How did 100% my original disk13 folder/file structure return after the "reiserfsck --rebuild-tree /dev/md13" rebuilt and created 2/3 the original folder/file structure?
Thanks,
Christopher
-
I went ahead and restarted the server and now disk13 is no longer showing as unformatted but still has a red ball. The reiserfsck tool recovered about 2/3 of my files. I've copied the recovered files using terracopy to a drive on my PC.
I want to attempt to rebuild the disk13 by putting my old parity drive in. I know that my new parity is not correct. To do this I need to remove the disk13 red ball. Unraid will not let me put back my old parity drive with a red ball. The reason I didn't do a rebuild initially was because the events leading up to disk13 failure were obscure in my mind. Therefore I didn't trust my old parity drive.
The reason I want to do a parity(old) rebuilt after a reiserfsck recovery: I want to md5 compare reiserfsck recovered files with parity(old) rebuilt files. If I see that the md5 matches for all or most files, then this give me confidence in the parity(old) rebuilt disk13 data.
I found this information below but I wanted to confirm with you before I move forward. Also I have Unraid version 5.0.6. Whats the best way to remove the redball and put my old parity drive back?
Thanks,
Christopher
-
On Main->Array Operations there is a checkbox under the button for starting the array to start in Maintenance mode. Perhaps you checked and do not remember?
I'm pretty sure I didn't check it but you never know.

If in a terminal session use the 'df' command. If in Maintenance mode the you will not see any disks mounted. If running in normal mode you will see all the disks are mounted.
Here's the df output. md13 is the only one not mounted. I read in another thread that the "unformatted" label in the webgui should really read "unmounted". So the array is in normal mode with all disks mounted except md13. Perhaps reiserfsck didn't complain because the device it was operating on was already unmounted? I've attached a few webgui screenshots. Should I stop the array and then restart the server?
root@FileServer02:~# df
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 131072 600 130472 1% /var/log
/dev/sda1 1957600 633120 1324480 33% /boot
/dev/md1 2930177100 2891592192 38584908 99% /mnt/disk1
/dev/md2 2930177100 2918796832 11380268 100% /mnt/disk2
/dev/md3 2930177100 2912435808 17741292 100% /mnt/disk3
/dev/md4 2930177100 2792846216 137330884 96% /mnt/disk4
/dev/md5 2930177100 2859854476 70322624 98% /mnt/disk5
/dev/md6 2930177100 2906808036 23369064 100% /mnt/disk6
/dev/md7 2930177100 2922271496 7905604 100% /mnt/disk7
/dev/md8 2930177100 2898554888 31622212 99% /mnt/disk8
/dev/md9 2930177100 2930177100 0 100% /mnt/disk9
/dev/md10 2930177100 2898371724 31805376 99% /mnt/disk10
/dev/md11 2930177100 2923205360 6971740 100% /mnt/disk11
/dev/md12 2930177100 2930177100 0 100% /mnt/disk12
/dev/md14 3906899292 3906899292 0 100% /mnt/disk14
/dev/md15 2930177100 2624423100 305754000 90% /mnt/disk15
/dev/md16 3906899292 3524213932 382685360 91% /mnt/disk16
/dev/sdo1 234423872 189317232 45106640 81% /mnt/cache
shfs 45906100884 44840627552 1065473332 98% /mnt/user0
shfs 46140524756 45029944784 1110579972 98% /mnt/user
root@FileServer02:~#
Thanks,
Christopher
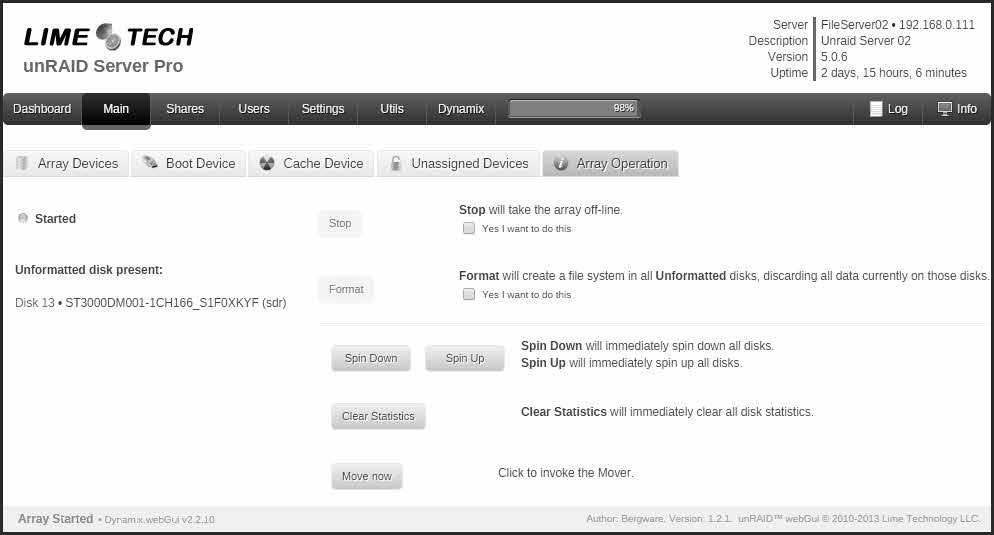
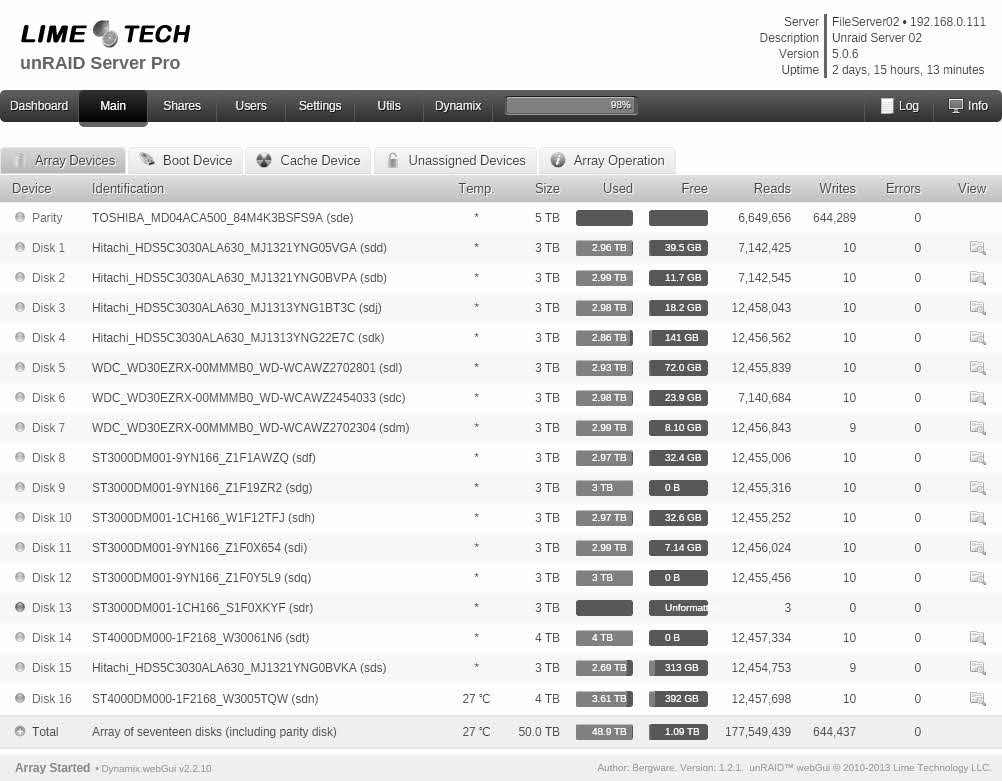
-
The normal procedure would be to stop the array (which was expected to be in Maintenance mode) and restart it in normal mode. That is probably what you need to do (but see the next point).
Perhaps I was already in Maintenance mode and I didn't know it? Can Maintenance mode be automatically enable by a redball, parity build or some failure event? I don't see anything regarding Maintenance mode in the Dynamix webgui. Is there cmd I can run in the terminal to show if its in Maintenance mode or not?
I thought that reiserfsck would refuse to run against a mounted file system so not quite sure how you managed to run it against a 'md' type device if it was not in Maintenance mode. If you did not run against a 'md' type device then perhaps you better tell us what actually happened before proceeding.
I did run reiserfsck against md device md13 as shown below. reiserfsck didn't refuse to run or mention anything about Maintenance mode. What's you recommendation moving forward?
Replaying journal: Done.Reiserfs journal '/dev/md13' in blocks [18..8211]: 0 transactions replayed
###########
reiserfsck --rebuild-tree started at Fri Jun 19 13:16:07 2015
###########
Pass 0:
####### Pass 0 #######
Loading on-disk bitmap .. ok, 678797287 blocks marked used
Skipping 30567 blocks (super block, journal, bitmaps) 678766720 blocks will be read
0%. left 586061335, 4043 /sec
-
The array should have been running in Maintenance mode while you were doing this? Are you saying that stopping the array from running in Maintenance mode and restarting it in normal mode is still showing the disk as unformatted (it should not)?
No. I have not restarted the array yet since reiserfsck completed. I'm asking if there's anything else I should do before a restart? Also, I did not run reiserfsck in Maintenance mode. My mistake. What's are negative effects of this?
-
The reiserfsck process just finish and the end of the report is shown below. The web front end still shows the drive as unformatted. The wiki says I should restart the array after reiserfsck completes. Please confirm if there's anything else I should do before a restart? Also what exactly does "Deleted unreachable items 40581" and "Empty lost dirs removed 2" mean from the report? Thanks!
Flushing..finishedObjects without names 1329
Empty lost dirs removed 2
Dirs linked to /lost+found: 17
Dirs without stat data found 8
Files linked to /lost+found 1312
Pass 4 - finished done 501821, 11 /sec
Deleted unreachable items 40581
Flushing..finished
Syncing..finished
###########
reiserfsck finished at Sat Jun 20 23:34:12 2015
-
This is going to take a long time.
 Is there anyway to disable parity while during the reiserfsck process? I can build the parity drive after. I don't think my parity is correct anyways based on the "mdcmd status" results in my original post above. Thanks.
Is there anyway to disable parity while during the reiserfsck process? I can build the parity drive after. I don't think my parity is correct anyways based on the "mdcmd status" results in my original post above. Thanks.Current reiserfsck Status:
Replaying journal: Done.Reiserfs journal '/dev/md13' in blocks [18..8211]: 0 transactions replayed
###########
reiserfsck --rebuild-tree started at Fri Jun 19 13:16:07 2015
###########
Pass 0:
####### Pass 0 #######
Loading on-disk bitmap .. ok, 678797287 blocks marked used
Skipping 30567 blocks (super block, journal, bitmaps) 678766720 blocks will be read
0%. left 586061335, 4043 /sec
-
Here's the result of "reiserfsck --check /dev/md13":
###########reiserfsck --check started at Fri Jun 19 00:57:26 2015
###########
Replaying journal: Done.
Reiserfs journal '/dev/md13' in blocks [18..8211]: 0 transactions replayed
Checking internal tree.. \block 602112004: The level of the node (28661) is not correct, (4) expected
the problem in the internal node occured (602112004), whole subtree is skipped
finished Comparing bitmaps..vpf-10640: The on-disk and the correct bitmaps differs.
Bad nodes were found, Semantic pass skipped
1 found corruptions can be fixed only when running with --rebuild-tree
###########
reiserfsck finished at Fri Jun 19 01:18:49 2015
###########
Should I proceed and run "reiserfsck --rebuild-tree /dev/md13"?
Thanks,
Christopher
-
I'm running the check command as "reiserfsck --check /dev/md13" and will report the results in the morning. Thanks.
-
I ran reiserfsck --check /dev/sdr and here's the output:
reiserfs_open: the reiserfs superblock cannot be found on /dev/sdr.Failed to open the filesystem.
If the partition table has not been changed, and the partition is
valid and it really contains a reiserfs partition, then the
superblock is corrupted and you need to run this utility with
--rebuild-sb.
-
I started by running a parity check on existing 4GB parity drive. Then I followed the steps described on the forum to upgrade my parity drive from 4GB to 5TB. I left it building the parity drive. After a day or so I check to see what the status was. It was complete but disk13 has a red ball with 200K+ errors reported in the Dynamix web gui. I tried accessing the drive and was able to list and open files. When I attempted to get the system log I got some memory error. It was getting late so I decided to shutdown the server pick up in the morning. I turn on the server this morning and disk13 is showing as unformatted. I'm not sure how to interpret the mdcmd results below but I don't think it's good.
 Please let me know if the mdcmd status is ok and I can rebuild disk13 using the new 5GB parity drive. If not, what other options do I have to recover the data? Also, I still have the old 4GB parity drive.
Please let me know if the mdcmd status is ok and I can rebuild disk13 using the new 5GB parity drive. If not, what other options do I have to recover the data? Also, I still have the old 4GB parity drive.Below is a link to the system log and smart report . The smart report is from a prior test. I didn't run a smart test since this happened. I wasn't sure if it would make the situation worse.
Thanks,
Christopher
Unraid Version: 5.0.6
System log and smart report:
https://drive.google.com/file/d/0B00Diiihkv_qSmY5YXpHaFM4VkU/view?usp=sharing
/root/mdcmd status | egrep "mdResync|mdState|sbSync"
sbSynced=0
sbSyncErrs=0
mdState=STARTED
mdResync=0
mdResyncCorr=1
mdResyncPos=0
mdResyncDt=0
mdResyncDb=0
This looks like the error in the system log:
Jun 18 14:43:52 FileServer02 emhttp: shcmd (10217): mkdir /mnt/disk13Jun 18 14:43:52 FileServer02 emhttp: shcmd (10218): set -o pipefail ; mount -t reiserfs -o user_xattr,acl,noatime,nodiratime /dev/md13 /mnt/disk13 |& logger
Jun 18 14:43:52 FileServer02 kernel: REISERFS (device md13): found reiserfs format "3.6" with standard journal
Jun 18 14:43:52 FileServer02 kernel: REISERFS (device md13): using ordered data mode
Jun 18 14:43:52 FileServer02 kernel: reiserfs: using flush barriers
Jun 18 14:43:52 FileServer02 kernel: REISERFS (device md13): journal params: device md13, size 8192, journal first block 18, max trans len 1024, max batch 900, max commit age 30, max trans age 30
Jun 18 14:43:52 FileServer02 kernel: REISERFS (device md13): checking transaction log (md13)
Jun 18 14:43:52 FileServer02 kernel: REISERFS (device md13): replayed 2 transactions in 0 seconds
Jun 18 14:43:53 FileServer02 kernel: REISERFS warning: reiserfs-5090 is_tree_node: node level 28661 does not match to the expected one 4
Jun 18 14:43:53 FileServer02 kernel: REISERFS error (device md13): vs-5150 search_by_key: invalid format found in block 602112004. Fsck?
Jun 18 14:43:53 FileServer02 kernel: REISERFS (device md13): Remounting filesystem read-only
Jun 18 14:43:53 FileServer02 kernel: REISERFS error (device md13): vs-13070 reiserfs_read_locked_inode: i/o failure occurred trying to find stat data of [1 2 0x0 SD]
Jun 18 14:43:53 FileServer02 kernel: REISERFS (device md13): Using r5 hash to sort names
Jun 18 14:43:53 FileServer02 logger: mount: /dev/md13: can't read superblock
Jun 18 14:43:53 FileServer02 emhttp: _shcmd: shcmd (10218): exit status: 32
Jun 18 14:43:53 FileServer02 emhttp: disk13 mount error: 32
Jun 18 14:43:53 FileServer02 emhttp: shcmd (10219): rmdir /mnt/disk13
-
NewEgg has 20% off on all Norco server chassis and $75 off the RPC-4224. Promo code WWHUY685
http://www.newegg.com/Server-Chassis/BrandSubCat/ID-10473-412
-Christopher
-
Make sure to read the responses on the slickdeals.net forum for this deal.
- Only 1 year warranty
- "The drive specs total hours break out that if your computer was on 24/7 that this drive would be dead in 3 months"
- 37% failure rate
http://slickdeals.net/f/5160460-Newegg-Special-3TB-Seagate-HDD-for-124-95?
- Only 1 year warranty








 Is there anyway to disable parity while during the reiserfsck process? I can build the parity drive after. I don't think my parity is correct anyways based on the "mdcmd status" results in my original post above. Thanks.
Is there anyway to disable parity while during the reiserfsck process? I can build the parity drive after. I don't think my parity is correct anyways based on the "mdcmd status" results in my original post above. Thanks.
[Support] Linuxserver.io - Plex Media Server
in Docker Containers
Posted
Yes! Thanks for the correction. I updated my original post.