




Christopher
Members
-
Joined
-
Last visited
Everything posted by Christopher
-
Any luck with this? I'm having the same issue.
-
When I navigate to http://192.168.0.111:7700 I get {"status":"Meilisearch is running"}. How can I access the mini dashboard?
-
Yes! Thanks for the correction. I updated my original post.
-
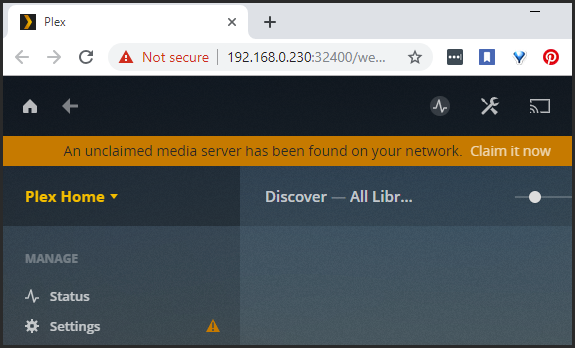
I'm having an issue where my Plex Server no longer being recognized. Plex is seeing my server as a new instance with a message on top saying, "An unclaimed media server has been found on your network. Claim it now". My Libraries are missing because it think it's a new server. Here's what led up to this below... 1) I had several cache drive BTRFS errors in my log. Docker apps to would stop or not respond. 2) Searched the forums and found post with similar issues. I tried a few things to fix it with no success. 3) I decided to recreate my cache drive. I disabled docker and VM and moved all cache folders/files to the array. 5) I cleared my cache configuration and deleted partitions on those my 4 cache SSDs. 6) I setup the 4 SSD drives as cache again and formatted. 7) Copied all files back to the cache array. Restarted server. 9) Deleted my docker.img 10) Enabled docker. Docker created new empty docker.img 11) Installed Plex from previous Apps. Config pointed to original folders 12) Started Plex Any ideas? Is there a way to get Plex to see this as my original instance? If I proceed with this new instance and add existing libraries, will Plex automatically use the existing database/files in my config folder? If I proceed with this how will it effect my Tautulli database? Your help is appreciated!
-
Thanks for your pgAdmin4 template. Do you have any plans to upgrade from pgAdmin4 version 2.1 to the latest 3.4?
