

skoub
-
Posts
66 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by skoub
-
-
Hi everyone!
I wanted to create a new share on my array but it doesn't work. The error doesn't show on the UI but if I check the log, I see "emhttpd: error: shfs_mk_share, 6450: No space left on device (28): ioctl: /NewFolder".
I tried to restart the array, reboot the server but without any success. I have enough space on my array and also on my USB key so I don't know how to solve it.
I have attached the diagnostic file.
Thank you for your help!
-
Just wanted to say that everything is back to normal now. Thank you again for all the support!
-
 2
2
-
-
The disk is now in the rebuilding process. By curiosity, what kind on information you where searching in the my diagnostics file?
Thank you all for your help!
-
-
I've unassigned the disk #2 and I can browser the emulated disk.

-
I've done the filesystem check without the -n switch but no luck, the disk is still in "invalid partition layout" state. Here's the result:
Phase 1 - find and verify superblock...
- block cache size set to 148496 entries
Phase 2 - using internal log
- zero log...
zero_log: head block 2270027 tail block 2270027
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
Phase 5 - rebuild AG headers and trees...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- reset superblock...
Phase 6 - check inode connectivity...
- resetting contents of realtime bitmap and summary inodes
- traversing filesystem ...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify and correct link counts...XFS_REPAIR Summary Thu Aug 4 17:42:27 2022
Phase Start End Duration
Phase 1: 08/04 17:42:04 08/04 17:42:13 9 seconds
Phase 2: 08/04 17:42:13 08/04 17:42:14 1 second
Phase 3: 08/04 17:42:14 08/04 17:42:18 4 seconds
Phase 4: 08/04 17:42:18 08/04 17:42:18
Phase 5: 08/04 17:42:18 08/04 17:42:26 8 seconds
Phase 6: 08/04 17:42:26 08/04 17:42:27 1 second
Phase 7: 08/04 17:42:27 08/04 17:42:27Total run time: 23 seconds
doneSo my last option is to rebuild my disk? Can someone confirm the steps please?
- stop the array
- unassign the disk
- start the array without the disk
- format the disk with the option that is shown "Format will create a file system in all Unmountable disks"
- stop the array
- reassign the disk
- start the array
- let the system rebuild my disk
-
I don't mind losing the data on this disk if I can get it back by rebuilding the array but if I can fix it without doing that, it would be great. Here's the result for the Check Filesystem:
Phase 1 - find and verify superblock...
- block cache size set to 148496 entries
Phase 2 - using internal log
- zero log...
zero_log: head block 2270027 tail block 2270027
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.XFS_REPAIR Summary Tue Aug 2 22:21:54 2022
Phase Start End Duration
Phase 1: 08/02 22:21:48 08/02 22:21:48
Phase 2: 08/02 22:21:48 08/02 22:21:49 1 second
Phase 3: 08/02 22:21:49 08/02 22:21:53 4 seconds
Phase 4: 08/02 22:21:53 08/02 22:21:53
Phase 5: Skipped
Phase 6: 08/02 22:21:53 08/02 22:21:54 1 second
Phase 7: 08/02 22:21:54 08/02 22:21:54Total run time: 6 seconds
-
Hi everyone,
I have checked my server today and discovered that one of my disk show the message "Unmountable: Unsupported partition layout". This is not a new disk. It is there for many years now and I don't know why I got this message today.
I have the option to format the disk but I'm not sure it's the way to go. What steps should I do to fix this? I have attached my diagnotics file in case it can help.
Thank you for your help!

-
My shares doesn't use the cache drive. But to push the test further, i tried to write directly to the cache drive.
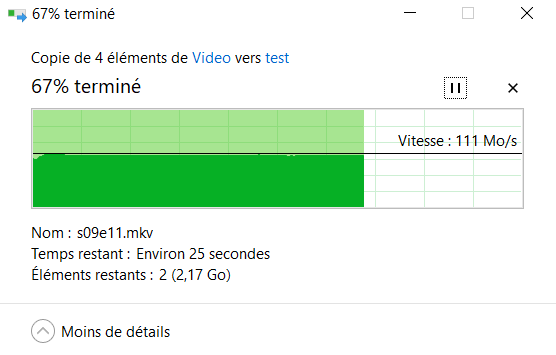
This test is with a new share with the option "Use cache disc" to "Only". I obtain a stable 111mb/sec.
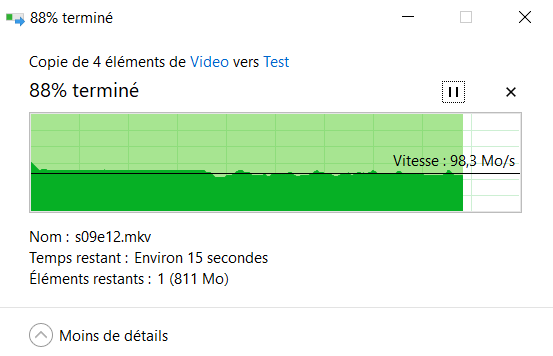
This test is with a new share with the option "Use cache disc" to "Yes". The transfert is not as smooth varying from 92mb to 111mb/sec
-
@Frank1940, i'm copying large files >2GB. The spikes that I get is during the transfert of the same file.
And thank you for the tip about posting updates on a new post! It make sens!
-
25 minutes ago, BRiT said:
Most troubleshooting helpers will need your full Diagnostics file to be posted.
done!
-
Hi everyone!
When i write to my shares, i do not get a smooth write speed. It always fluctuate up and down from 18mb/sec to 38-39mb/sec. I'm alone on my network, using an USB3 Gigabit Ethernet adapter. Is it possible to test write speed on my shares without using my laptop so i can remove my Ethernet adapter from the equation?
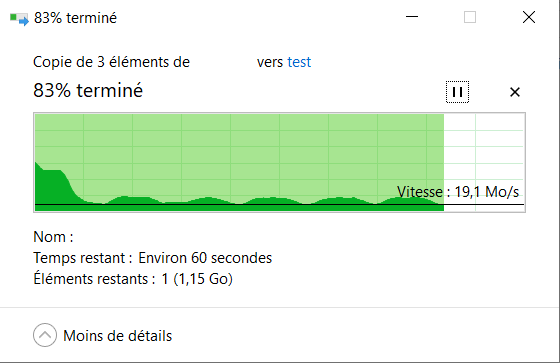
Here's my server:

-
Thank you. I have proceeded to the repair and it went well. I will check this week if it come back.
About the system share and was on disk1, in fact, it was only the empty folder that i forgot the delete. I have moved everything to the cache drive.
-
Hi everyone,
In my system log, I have these lines that have been reported a few times tonight. Any idea what it means? I'm running v6.7.0-rc7. I have attached my diagnostic files.
Apr 18 19:47:53 Tower kernel: XFS (sde1): Metadata corruption detected at xfs_buf_ioend+0x4c/0x95 [xfs], xfs_inode block 0x2550fe0 xfs_inode_buf_verify Apr 18 19:47:53 Tower kernel: XFS (sde1): Unmount and run xfs_repair Apr 18 19:47:53 Tower kernel: XFS (sde1): First 128 bytes of corrupted metadata buffer: Apr 18 19:47:53 Tower kernel: 000000004eca1978: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 0000000023f3193a: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 0000000048db5825: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 00000000bd20adf2: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 0000000056452f65: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 00000000c54d7f15: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 00000000e84aeba6: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: 000000003e6a07a7: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Apr 18 19:47:53 Tower kernel: XFS (sde1): metadata I/O error in "xfs_trans_read_buf_map" at daddr 0x2550fe0 len 32 error 117 Apr 18 19:47:53 Tower kernel: XFS (sde1): xfs_imap_to_bp: xfs_trans_read_buf() returned error -117.
Thank you very much for your help!
-
Thank you. The rebuild have started!
-
I only have the choice to do a "read-check". But this read-check doesn't read the faulty disk at all. So how do I do a rebuild?
-
I've reboot the server and I wasn't able to run the SMART test. The SMART feature as disabled. I had to enable it and then i've been able to run the quick test. I have attached the new diagnostic report.
-
Hi everyone,
This morning we have lost electricity. When the electricity came back, i started the array and a parity check automaticly started. After 2-3 minutes, i had a read error on one of my disk and the parity check has stopped. The disk that had a read error is now disabled by unraid. I wanted to do a SMART test but i get this error message: A mandatory smart command failed. To continue, add one or more '-T permissive' options. I haven't rebooted the server yet. What should I do?
I have attached my diagnostic file.
-
I remember that on a old 6.x version of Unraid, the S3 Sleep plugin was working flawlessly. After an update, it was broken. So i don't know if Unraid have changed how he read the hdd info (SMART properties) and cause the disk to be in active state.
So is it considered a bug from Unraid or a bug from S3 Sleep? How i should ask for help?
-
Hi everyone!
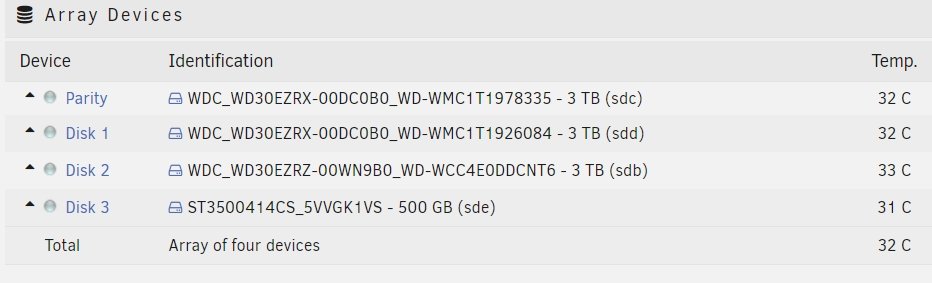
I have the Dynamix S3 Sleep plugin that doesn't always work. Sometimes, the log file says that there's still harddrive activity even if all my drives are spun-down. I have noticed that the plugin will only work if unraid doesn't report the Temp of the drive (the Temp column will show the * character). As soon as unraid can show the Temp, Dynamix S3 Sleep reports that my harddrive are still actives.
Any idea why and what i should do to fix this issue?

-
22 hours ago, Frank1940 said:
Look back four posts to one that I made regarding a similar issue. There were a lot things that were required in some cases for a successful upgrade from 6.1.9.
well, good news. I've found my problem. In the "go" file, i was installing a few packages by default and one of them was causing an issue with unraid from 6.2.x and up. I have commented everything and now i can communicate with my shares without any problems!
-
On 21/02/2017 at 9:53 PM, jonp said:
Nothing in your logs stands out. Can you access the webGui for the server in a browser (http://hostname or http://ipaddress)? I don't believe anyone else has reported this issue either. So are you stating that on 6.1.9, everything works, then if you upgrade the server to any newer version (6.2.x or 6.3.x), SMB access stops working, and if you drop back down to 6.1.9 everything comes back again?
Exactly. And i can't revert back to 6.1.9 by just replacing the bzroot & bzimage files. When unraid is booted, the array is not set at all. It have lost all my array config. Since that i've done a backup of my usb drive before the update, i did restore everyting to the key.
So yes, i can access the webGuy with either the hostname of the ipaddress. With the 6.2.x version, i remember that my share was accessible for a few seconds and then the bug appeared. This is like if the SMB service wasn't responding after a few seconds.
Maybe what i can do is to update to the version just after 6.1.9, one by one, and see on which version the problem appear. Where can i download all versions after 6.1.9?
-
9 minutes ago, jonp said:
Have you tried browsing by IP? If IP works but hostname does not for accessing shares, let us know.
tried to browser by IP and hostname without success. I rebooted my computer just to be sure before doing the test.
-
hi everyone.
Since the update to 6.3.2, i can't access my shares anymore from any device on my network.
- windows 10 can't access the shares
- android phone
- linux box
telnet from my windows 10 work perfectly and i can navigate to the unraid dashboard with my browser. I had this problem with the 6.2.x branchs too and the last version that is working without any problems for me is 6.1.9.
Any idea?









error: shfs_mk_share, 6450: No space left on device (28)
in General Support
Posted
I've put 50GB and it solve the problem but I don't understand why. All my shared are set to 0 and it worked but maybe I had more space at that time. What is the purpose of this setting? It's to be sure that there's always a space available to this folder?