



TQ
Members
-
Joined
-
Last visited
-
Summary: Support Thread for Sportarr Application: Sportarr Github: https://github.com/Sportarr/Sportarr Sportarr automatically tracks and organizes live sports events across all major sports - combat sports, basketball, football, hockey, motorsports, and hundreds more.
-
Boxarr solves the problem of keeping your media library current with popular movies without manual intervention. It automatically tracks what's trending at the box office and ensures your Radarr library has the movies people actually want to watch. GitHubGitHub - iongpt/boxarr: Boxarr is an automated box office...Boxarr is an automated box office tracking application that integrates with Radarr to monitor, add, and manage the latest theatrical releases. It provides a beautiful dashboard showing the current ...
-
Original repo is removed. Updated to point to https://github.com/henrywhitaker3/adguard-exporter
-
@NY152 You got it. Updated. CA should pick it up soon.
-
Purgarr is a lightweight companion to your Arr stack designed to keep your torrent queue clean and ready for high quality downloads. Features Include: Cleans your torrent client of media imported by Sonarr and Radarr. Detects and removes stalled torrents. Adds stalled torrents to Sonarr's and Radarr's blocklist. Triggers a search to replace low quality torrents. Application: https://github.com/steveharsant/purgarr ENV Variables: https://github.com/steveharsant/purgarr?tab=readme-ov-file#environment-variables
-
Just pushed the fix. Thanks for reporting.
-
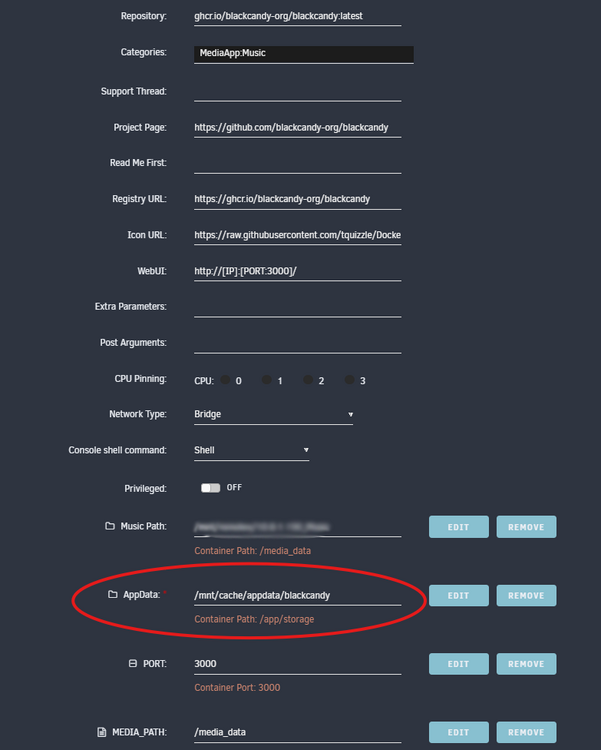
For clarity's sake, here is how you must get the appdata dir set so this app runs. Before running the application, you need to chown the "AppData" path to user/group 1000:1000. For my example, I'd need to run this from the terminal and the application will run upon subsequent starts. chown 1000:1000 /path/to/blackcandy/AppData -R
-
Black Candy is a self-hosted music streaming server, your personal music center. Github: https://github.com/blackcandy-org/blackcandy
-
If you're not using the script provided, you can check all clamscan parameters to see what else you might want to add. https://linux.die.net/man/1/clamscan
-
Yes, I meant to call out the lack of multi-thread but the need for CPU pinning in the event that you have a large scan set and not a lot of cores. ClamAV will take what it can get, so limiting it to a sane set of defaults helps. Thanks for the kind words.
-
On my Github page, I've called this out. docker run -d --name=ClamAV \ --cpuset-cpus='0,1' \ -v /path/to/scan:/scan:ro \ -v /path/to/sig:/var/lib/clamav:rw \ tquinnelly/clamav-alpine -i --log=/var/lib/clamav/log.log --max-filesize=2048M

-
Missed that. All sorted. Thanks
-
MySQL, PostgreSQL, MS SQL, Oracle, MongoDB, SQLite and others Application: https://dbgate.org/ Docker Hub: https://hub.docker.com/r/dbgate/dbgate All Environment Variables: https://dbgate.org/docs/env-variables.html
-
SideQuests - Objective Tracker SideQuests provides an intuitive and mobile friendly web-interface for managing tasks and objectives. App/Github: https://github.com/need4swede/SideQuests
-
Nexterm Server management The open-source server management software for SSH, VNC & RDP App: https://docs.nexterm.dev/ Github: https://github.com/gnmyt/Nexterm



