




bassy
Members
-
Joined
-
Last visited
-
I'm out of ideas and not sure where to keep looking for this issue, I tested out the User Share Copy Bug: `cp /mnt/cache/Media/testing.txt /mnt/user/Media/testing.txt` & vs versa, causes the data basically to become 0 bytes. The difference here is that for the data I can see in /mnt/user/Media/ everything looks intact, however none of this data appears on the disks or cache, after doing a `$du` of the directories I'm seeing 0 bytes so Windows is lying to me when it says that these objects are 1GB or whatever. I'm at the point now where I'm almost ready to just start again with building back up my data, but I'm afraid I'll run into this issue again, any other ideas on where to look or what check to avoid this again? I'm revisiting the Docker setups separately, I want to do more research on that first and check out if it was one of the containers that caused it or not..
-
Is it possible by having the "Use cache pool (for new files/directories): Prefer" setting and then triggering 'Mover' I somehow moved everything off my array to the cache pool and was overwriting as we went? I'm thinking it has something to do with this or how I mounted this share within docker. I have found that it was in fact only the 'Media' share that was affected.
-
Okay I'll bench this one for now and do that later. --- I've done a reboot, configure the network settings (as this was the original goal) brought everything back online, started the array (it's doing a parity check). As it stands: - Dockers are all running again. - VMs are running (except plex don't want to kill the DB there if I can recover media) - `/mnt/user/Media/.....` still shows that it has nearly 4.5TB when inspected in windows, but the array is showing only about 400GB across Disk1+2. I guess in about 8.5 hours we'll see if the parity check fixes anything or if I'm truly restarting Wanna also say thanks for your quick replies and information
-
Okay let me a take a look and see about this. I don't think it was a hack, but I'm currently reading the user share copy bug and suspect this could be it, but need to confirm, this also happened when all dockers/VMs were stopped. When you say misconfigured docker/app, should I be mounting in this way in docker? volumes: - /mnt/user/appdata/<docker>/config:/config - /mnt/user/<share>/data:/data That's what I suspected too. --- One thing worth noting the array started inflating on used space, Disk1 is up to 320GB but I suspect this is from the mover running on the cache and it seems to have stopped now.
-
I guess here comes the dumb question. Is there anyway to recover the 4.6ish-TB I've lost? I agree looks that data is gone, however if I list /mnt/user/<share>/ I see it, now I did a quick `$ ls >> list.txt` so I at least have a somewhere to start in re-acquiring. Also what are the some ways? I definitely do not want to encounter this again! I remember doing a scrub or balance on the cache and changing the cache for the share from prefer to yes. Surely this wouldn't have destroyed the 4+TB across the disk array? I'm so confused, I feel I'm in the 7 stages of grief at the moment lol
-
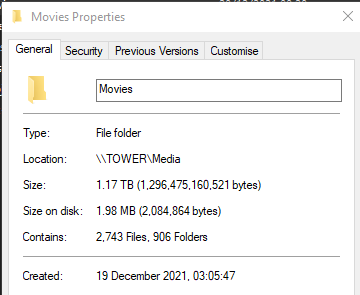
When you say the array is basically empty? Are you telling me all my data is gone? I've tried playing media from the windows share and it fails saying it's corrupted. This is a screenshot of the share from windows side: At this point I don't even care about the dockers or VMs, I'm freaking out because I think I've lost all of my media
-
Hey all, I'm pretty new to unraid been using it now on a trial for about a week, plan to buy it after the trial but need a little help. I definitely feel as though this is 100% my fault... I'll try and go through as much of what I can remember I did below. So some days ago before I started fully setting up my VMs and Dockers, I for some reason thought it would be a great idea to remove the bridging configuration of my NIC, so I have the single onboard NIC and a dual 1GB PCI card. I set up all my dockers, VMs and literally got everything dialed in to where I wanted. Now I was remember I wanted to change that NIC back to bridge mode will all of the NICs or perhaps create a bond. Well I stopped all VMs and Dockers and disabled the services. Made the networking changes and restarted the services. From the Docker tab: "Docker Service failed to start." From the VM tab, there's nothing there now, my VMs are gone. From the virtLog it seems it cannot load the XML configs of the two VMs I have. From here, I assumed a reboot might help, so I simply clicked the "Reboot" button in unraid, assuming it would do a stop of the array and a graceful shutdown and start up. Well it took a sec, think there was network IP hiccup but came back up, when it did come back up the array was showing it was improperly shutdown and wanted to do a parity check, I started this but later stopped it as well there wasn't anything writing or reading prior or during and really I wanted to resolve the VM and Docker issue. I noticed my cache was full, which having some storage knowledge I know to be a good thing, we're utilizing it however I don't know why, maybe the lack of caffeine or sleep or both lead me to believe that because of the cache somehow, Docker couldn't start and my VMs were having issues. I began to try and clear it or something, I click balance realizing this just sets raid mirror on the two SSDs, I then hit scrub, didn't really appear to do anything (that contributed towards solving my issue) so I decided, I'm done bed time look again in the morning. Now I've woken up had a coffee and taken a peek, I now see my array is reporting 1% utilization or 286 GB of 24TB, however I know there to be nearly 5TB of data on there, and when I navigate to the share via Windows network I see all my data. This data also appears to be in /mnt/user/<share>/.... but does not appear to exist on /mnt/cache/ or /mnt/disk*/ (well aside from 1 or 2 items. - Is this due to me cancelling the parity check? - Should I perform a parity check? or would this cause the writes to parity to delete my data? - Was this due to the scrub? - Should I try another reboot? - Should I spend another 3 days copying that data out of /mnt/user/ - I believe I also ran the mover and cache was set to prefer for the share in question. I know this is a lengthy post, apologies, but I've spent nearly a week setting this up and building this and just finished moving all of the data from my old NAS and now I'm literally freaking out. Thanks in advance. Diagnostic file attached. tower-diagnostics-20211221-1019.zip
