




DizRD
Members
-
Joined
-
Last visited
Everything posted by DizRD
-
Absolutely, Backups have been made, but I'm more curious about if the system is fault tolerant enough to operate if the cache drive dies or if the system halts, since I don't know how long it would take me to get a replacement cache drive.
-
Thanks, I'd heard of Dynamix but was kind of worried about manually changing permissions to get it to work in 10.3 in case that messed with any default permission configurations needed for upgrade paths in the future. Some of my system shares are told to prefer cache.. What happens if cache really fails? Will the system no longer be operational until I replace the cache drive or disable cache?
-
Interesting! I will try the update. I had updated to 10.3 before, but ran into surprise permission issues on shares and rolled back to my previous Unraid version and the permission issues went away. I guess I will have to see if they are fixed in the newest version
-
Here's the Diagnostic after the reboot and things seem operational. Btw I haven't moved any cables or anything, everything hardware wise has been solid until now. deathstar-diagnostics-20220913-2334.zip
-
I went to update the plex app, and it seemed to be stuck there forever. Eventually I reloaded the unraid docker page and it gave me an error on that page, something to the effect of plex.ico was read-only.. Then everything went bonkers. I started seeing errors in the systemlog about my cache drive not being accessible. I exported a diagnostic log at that time<attached>: I went ahead and restarted the server to see maybe the docker container update and put something in a stuck state.. When I restarted, 4 of my pool drives said they were unmountable. I searched and found a thread about booting into maintenance mode and running xfs_repair on the drives. It fixed some things and then I rebooted. Everything seems fine now, but i'm worried. I ran a smart test on the cache drive, and it said it had errors, but I've never had good luck with my smart reports in unraid<attached>: Anyone want to chime in on health insights or other suggestions? Some of my system shares are told to prefer cache.. What happens if cache really fails? Will the system no longer be operational until I replace the cache drive or disable cache? deathstar-diagnostics-20220913-2024.zip deathstar-smart-20220913-2221.zip
-
So my VMs have worked fine in the past with VNC or Spice. I haven't updated anything recently, but I've noticed when I connect to any of my VMs with VNC or spice, the session halts/freezes/stalls after 20 seconds or so. I can immediately reconnect and continue on where I left off. I haven't seen any error in the unraid host logs, nor in any of the remote clients that are connecting (remmina, tigervnc, remote-viewer). The VNC clients just sit there until I close them. But remote-viewer after closes itself like it loses connection after the stall has happened for a bit. When I reconnect, I dont see any issue with time in the system and processes seem to continue even when the display stalls. I've tried running ping while connecting and my connection to the server never drops any packets or has huge spikes. Any thoughts? deathstar-diagnostics-20220720-2347.zip
-
@trurl Thanks for the extra insight, I appreciate the context in case that's a problem in the future. In my scenario it seems to be that the size 0 files were created when the disk got full before I had limits set on the shares. Removing the size 0 files from the disk and restarting the copy process to the share is working as expected. Thanks!
-
So I think I figured out how to solve the problem, even If I don't know what caused the problem.. It seems like somehow size 0 files were created on one of the near full disks. It may have been from powerloss a couple of weeks ago, or maybe then I first was trying the copy but didn't have min size limits at the time.. It "seems" like the system was locked into putting the files on that disk because of those size 0 files, but because of min size limits it would fail? That's my theory anyway. Removing the size 0 files and starting the copy again seems to be working normally now.
-
I have no minimum space set for the cache drive, and it's got 1.7TB free when trying to perform the copy operation. I tried changing the allocation strategy on the share to "most free", but it didn't seem to make a difference either. Attaching Diag deathstar-diagnostics-20220714-1833.zip
-
@JorgeB Thanks for the response! I bought another 8TB drive to add to the array. It's all added and fine for the array. I started the copy process again. It put about 400GB on the new drive before coming back with the "no space left on device" error. I decided to eliminate Docker from the equation to see if that made a difference and ran rclone natively pointed at my /mnt/user/video share.. The "no space left on device" error is still returned even thought I have 17TB available on my array. Any thoughts on what to check next?
-
Anyone have suggestions?
-
I have a docker container that runs rclone to pull down files from my gdrive and put them on my unraid server. My array has 13.8 TB free and my 'unprotectedcache' for the share has 1.79 TB free: I have a /mnt/user/video share mounted in the container as /cdata. inside the container the df -h returns: Filesystem Size Used Available Use% Mounted on /dev/mapper/sdt1 1.6T 230.6G 1.4T 14% / tmpfs 64.0M 0 64.0M 0% /dev tmpfs 125.9G 0 125.9G 0% /sys/fs/cgroup shm 64.0M 0 64.0M 0% /dev/shm shfs 86.4T 73.8T 12.6T 85% /cdata shfs 1.6T 230.6G 1.4T 14% /config shfs 1.1P 60.7T 1.0P 6% /data /dev/mapper/sdt1 1.6T 230.6G 1.4T 14% /etc/resolv.conf /dev/mapper/sdt1 1.6T 230.6G 1.4T 14% /etc/hostname /dev/mapper/sdt1 1.6T 230.6G 1.4T 14% /etc/hosts tmpfs 125.9G 0 125.9G 0% /proc/acpi tmpfs 64.0M 0 64.0M 0% /proc/kcore tmpfs 64.0M 0 64.0M 0% /proc/keys tmpfs 64.0M 0 64.0M 0% /proc/timer_list tmpfs 125.9G 0 125.9G 0% /sys/firmware pdrive2: 1.1P 60.7T 1.0P 6% /data The rclone move command to pull down from my gdrive is returning this error with all files it's trying to transfer down(filename changed manually by me in this log clip): 2022/06/17 14:54:13 ERROR : FILE.mkv: Not deleting source as copy failed: multpart copy: write failed: write /cdata/video/FILE.mkv: no space left on device 2022/06/17 14:54:13 DEBUG : FILE.mkv: Failed to pre-allocate: no space left on device Share is configured with minimum 160GB free: Actual disk utilizations: Any thoughts or suggestions?

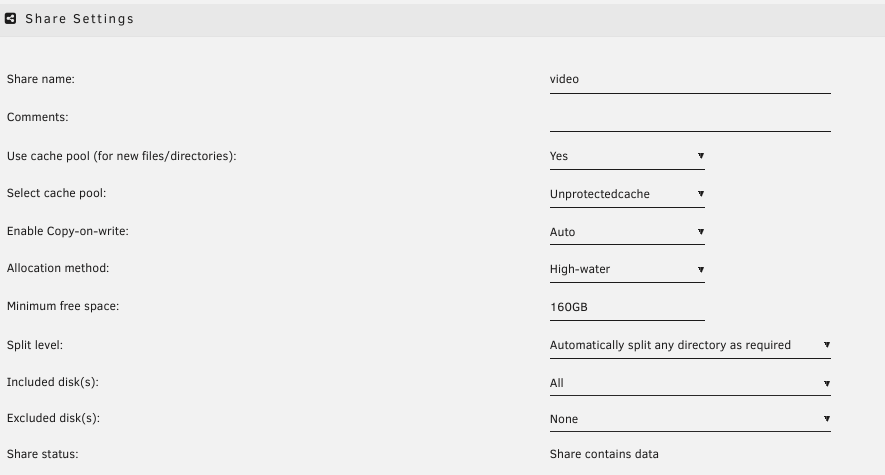
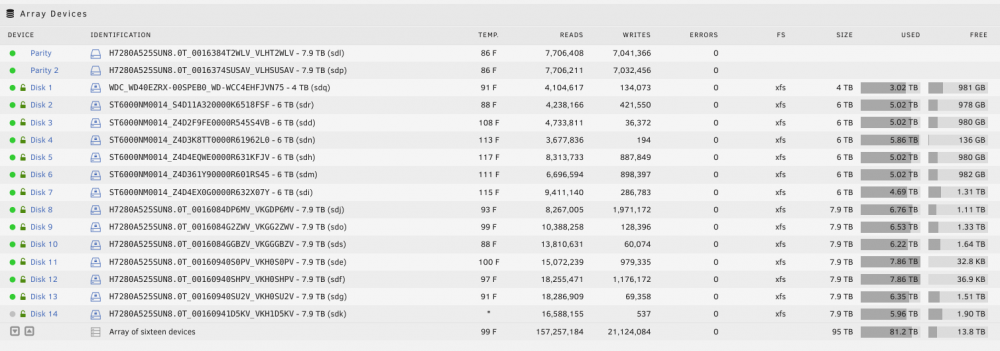
-
Which logs should I upload to help? the general plex media server log and the transcoder log maybe?
-
Using the Plexinc Plex Container, I didn't see a thread for it in the container section and honestly i'm not sure if it's a container specific issue. Server Version#: 1.26.0.5715 Player Version#: Plexweb 4.81.1 I don’t see any obvious errors in the logs, so I’m not sure what to check next. Setup info: Unraid server, plex running from a docker share /mnt/user/appdata/Plex set to prefer cache drive, Plex data is at /mnt/user/video/shows,movies and is set to Cache yes and the cache drive is an unencrypted seperate cache drive. I have a RTX 2060 as a hardware transcoder that seems to work fine. I’m also pulling down alot of data from my google unlimited drive, but the hardware doesn’t seem to be overtaxed. Any ideas on where to start troubleshooting?
-
sometimes when I'm connected to the web terminal or over SSH it will stall out. My network isn't dropping packets, I can immediately reconnect back. Sometimes when I reconnect, I will have about 20 seconds before it stalls again. I've been trying to setup this rapidly so I can move away from Gdrive. I restarted the last time it happened which triggered a parity check cause I'm still tuning my shutdown times. Things that may or may not be related: 1)I have a large number of drives with large capacity, so Parity checks take forever. I haven't been able to correlate if parity checks are running when this is happening yet or not because the parity checks take so long I haven't been able to compare running vs not running parity to see if it impacts the shell. 2) I added a linux compatible USB3 pci card for fast transfer, it seems like it's good so far, but no idea if it's a contributing factor. 3) I installed a RTX 3060 for transcoding and ML work. No idea if related. Any thoughts?
-
Your first paragraph was what I was trying to communicate wasn't true in my case. That being said, I didn't setup the custom networks with different physical ethernet ports. Do you have link(s) to share or would searching with "custom network" "physical ethernet ports" be the next best choice?
-
Hi, New unraid user here. I'm not sure, but I think I have a fairly basic setup of unraid so far, but before I start getting friends and family to use my server, I'm wanting to tighten up security. It seems docker containers are able to talk to each other on my unraid container networks and the unraid host itself. Here's the advanced network settings from my unraid docker tab: Host access to custom networks: Disabled Preserve user defined networks: No However, even with those settings a container on a custom network was able to access other containers via host exposed port and the containers were able to reach other ips in my actual lan range. I tried disabling ICC when creating the network to improve isolation, like: docker network create -o "com.docker.network.bridge.enable_icc"="false" isonet1 docker network create --internal nonet1 I eventually got a block working by using iptables directly: iptables -A INPUT -s 172.18.0.0/24 -d 192.168.1.0/24 -j DROP <Thanks to: > What I noticed is that stops containers from accessing exposed ports on the unraid host, but doesn't stop local lan access. So a compromised container would allow an attacker to use that container to attack my router or other network devices. So I tried: iptables -A FORWARD -s 172.18.0.0/24 -d 192.168.1.0/24 -j DROP Which seems to work, but also kills network access out to the internet. I'm curious if people have suggestions on better iptables commands to block host and lan access but still allow internet access. This would allow me to create relatively isolated networks for different container groups that I could route to with NPM.



