



Sk8rSeth
Members
-
Joined
-
Last visited
-
really thats awesome! do you have any documentation for how to do that? would i need to add them back to the server internally, or could i drop them into an external usb interface? how do i pull data off them and onto the array? sorry for all the questions, im learning so much!
-
not currently, but thats in my plan. if i were to go buy a spare disk or two to trade these out, and would need the data thats on the old disks im replacing, how would i access it? i like the idea of not overwriting it by building on top just in case but i have no idea how i would do anything with those old drives?
-
irreplaceable stuff, yes. but not all my important stuff (plus its just simply a LOT of data) so i would really want to take the least risky path to maintain data. its good to know i can stop the rebuild and start it again, but i am still not sure of the problem itself. is there any way to narrow it down to cables or maybe the h200 is bad, or something like that? if im rebuilding two disks at once, that means im out of redundancy and the whole array is at risk right, and since those SATA cables from the h200 are in groups of four, that would mean a bad cable could spell the end of 4 drives at worst case scenario right? is this the kind of thing where if i start a rebuild, and another drive, or two goes down just like this disk1 and disk4 situation, that i can stop the rebuild assume its a bad cable and replace the cable without losing all my data?
-
i have custom power cables that i made myself, and have been working flawlessly for over a year now, but i also reseated every connection to all the HDDs earlier when i started this diagnosis, so i suppose i could have not reseated them properly, however unlikely that might be? i also have all the drives in a fractal design node 304 case, which has two 'banks' of four drive cages. and the right most drive cage sites pretty close above the PSU, allowing for little room for SATA cables to bend around and find theyre way. they didnt seem under any stress to me, but these mini-sas to SATA cables for the h200 are new to me, is it possible theyre just way more fragile than i thought? do i need to wait the 19 more hours for this current rebuild to complete, hoping no other disks fail in that time before i can try to mess with the cables more? or can i pause the rebuild and try to fix the connections, then restart the rebuild? i am deeply nervous about the fact that two drives are in a failed state, which means with two parity my whole array is at the limits of its protection. stressful. attached is new diagnostics i just pulled, but im still not familiar enough to understand all im looking at. datass-diagnostics-20220613-1353.zip
-
Sk8rSeth changed their profile photo
-
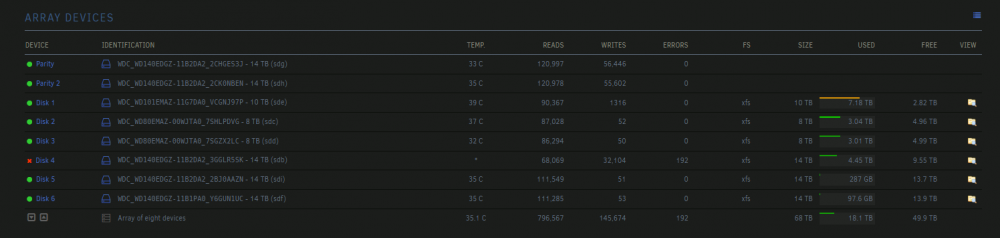
okay well i think i have a bigger problem than just the connections. after reseating the cables on both ends, and starting the rebuild for disk4, another disk is throwing a bunch of errors. specifically: Jun 13 12:24:38 DATAss kernel: md: disk1 write error, sector=2021486584 a ton of times. does this mean maybe a bad cable set? im using these cables, so its possible both of those drives are part of the same cable chain. also how do i deal with this now that im over an hour into the rebuild of disk4? do i let the rebuild continue? pause it? i have no idea what to do
-
oh sweet thank you!
-
do i need to remove the 'config' from the Historical Devices section (which i believe is just Unassaigned Devices plugin?) and more importantly, do i need to unassign the disk before starting the array? upon startup of the server again, the disk4 still shows the 'device is disabled' red X before starting the array. im not sure the procedure here, and the last time i messed with things i didnt really know, i lost an entire disk's worth of data. so im trying to be especially cautious here
-
awesome thanks! is there any test or procedure i can use to test the disk/array after reseating the cables and restarting to see if that was actually the problem? will unraid throw the same error immediately and disable the disk like before if the connections werent the issue?
-
yes, taken right as i posted this. i will shut down the whole thing and reseat the cables, and see if that fixes the issue. the random high write count made me think maybe it wasnt the 'thing i last changed'. @JorgeBhow can you tell the actual disk looks fine? is it just the lack of SMART errors or something else that i can start checking in these situations?
-
ah! sorry, its still physically in the server and such, just no longer being read/write to in the array. the device was _disabled_ is what i should have said
-
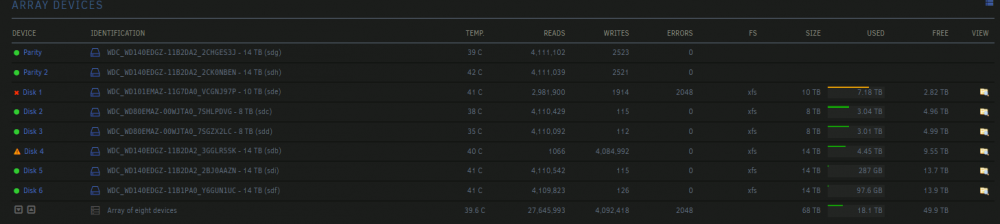
woke up this morning to a nasty red common problems error message. it appears that one of my disks is having problems but i cant figure out exactly what it is. i just switched my sata connections from one of these nvme breakout boards to one of these H200 in IT Mode and everything seemed to be going well yesterday. no issues at all that i could find. but today i noticed (im pretty sure this part is not new) that disk4 has way more writes than any non-parity disk in the array and im not sure why? (also attached the view of the array) and then obviously today its been pulled disabled from the array and is not showing any errors that i know how to recognize in the Tools > Diagnostics files (attached). disk4 is the only one not labelled as such, ID ends in R5SK can anyone shed some light on what might have happened? is this a bad cable/connection or does the disk need replacing? im still fairly new to the diagnostics part of server management so any help and education would be greatly appreciated datass-diagnostics-20220613-0924.zip
-
Yeah, i got a bunch of read and seek errors, then i reassigned it and did smart tests that returned successful mostly, except one extended test that returned like 100 errors, read, seek and sector errors, but i tried to rebuild the array with the disk anyway to see if it was a weird fluke (after getting several error-free SMART tests, and the rebuild failed. after that the drive became almost unrecognizable. i couldnt reassign it, or do any smart tests, or even use it as an external attached to the server. everything was unrecognized. even macos disk utility wouldnt recognize it at all. i didnt hear any clicking or anything physical but nothing i did in any system i had could get the disk to show up at all
-
yeah and i thought that was only for the cache drive since that was the only one i saw listed to the left, the disk4 hard drive wasnt listed on the left so i assumed it wasnt included in the format. is that wrong? was the drive formatted as well which resulted in the loss of all the data that happened to be on that particular drive when it died. which is why i have a weird gap in data?
-
yes i replaced disk4, which was a 10tb, and replaced with a 14tb. i am pretty sure i formatted it, but now that im trying to remember, i only remember seeing the format checkbox (down in the array operations section) with the new cache showing there. i cant recall seeing the 14tb for formatting, but it says the filesystem on that disk is xfs like the rest of my array so i assume it has to be formatted into that FS. im not sure why it would be so empty, except that the size used vs the new size available is just smaller. doesnt the array rebuild replace the data on that drive from the parity? also i have a parity 2 and not 1, because i had an 8tb parity drive, that i 'replaced' with a 14tb parity, and since its just a single parity replacement it was just added as parity 2 and i dont think i can change it. should i? here is a screenshot of the array for more clarity
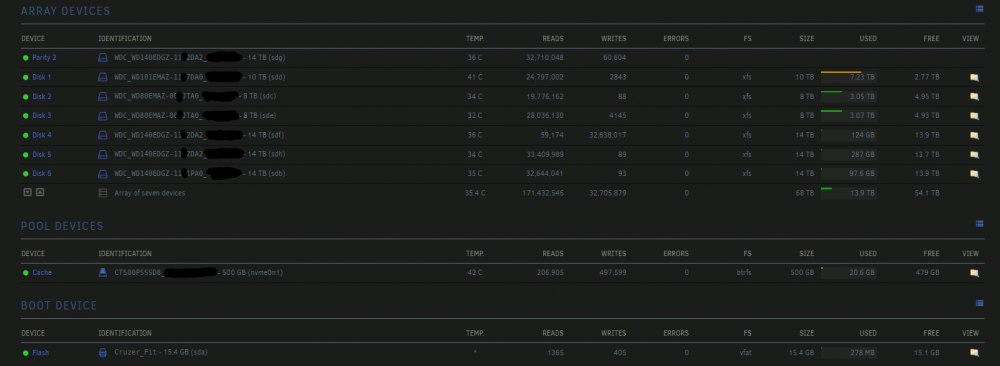
-
i have the affected shares set to cache : yes, not prefer. and i cant imagine they would have been open anyway since i only have the singular PC that accesses the server and i have definitely shut down that PC in the months during the missing data. could it be 'open' somewhere else? is there a way for me to see what files are in cache instead of on disk? why would some files from recently be good to go as normal, but then theres a gap, before returning to normal? if it was a 'cache hasnt been moved to disk' problem, wouldnt that also include the recent files too? datass-diagnostics-20220323-0900.zip


