





Dragonwyntir
Members
-
Joined
-
Last visited
-
Hello and Happy Holidays, Unraid Folks! Have a weird one that I'm hoping is easy to fix. A couple of months back, I started the road to upgrade my Unraid array with larger drives. The original config of the array was: 1 Parity Drive: One 6TB 4 Array Drives One 4TB One 4TB One 4TB One 4TB Several weeks ago, I went through upgrading the parity drive to a 10TB parity drive. Went very smoothly, with the array looking as follows: 1 Parity Drive: One 10TB 4 Array Drives One 4TB One 4TB One 4TB One 4TB I received three more 10TB drives, and have begun the process of swapping out the array drives. I started by using "unbalance" to clear off the first drive in the array, and this afternoon I swapped out disk 1 in the array with a 10TB drive. After swapping that drive out (following the normal and easy swap procedure), the array now looks like this: 1 Parity Drive: One 10TB 4 Array Drives One 10TB One 4TB One 4TB One 4TB I started the server and array, and it is now performing a format/data rebuild on disk 1. Everything seems to be looking just fine, except for my Plex docker container, which has just completely disappeared? I see, under the Docker Advanced View, that there is now an orphaned container for Plex, which I'm assuming is the droid I'm looking for, but I'm not sure how to recover that, or why it was the one on the chopping block. Can I assume the container will magically reappear after the rebuild? Is there another step to retrieve that orphan? And is there something I can do to avoid that happening in the future (almost assuredly something I messed up this time!) since I have three more drives to upgrade in the array? Thanks to everyone for your help in advance!
-
Hi Jorge, Thanks for your help on this. I was able to get the data backed up, the pool reformatted and then move the data back. Really appreciate the responses! Question: I moved back to btrfs for now because of how potentially catastrophic that was - is that me being too cautious?
-
Hi Jorge, Good thinking on this, but I might be missing a step somewhere. I was able to back up (copy) the data off of the pool, and I'm now ready to format the pool. When I try to do that (check "Yes I want to do this" and click "Format"), it thinks for awhile and then errors out. Do I need to take the pool out of read-only mode?
-
Hi Jorge, That worked - the array is up and I can poke around now (including seeing what is on the ssd_pool) - it shows that the pool is Unmountable in the Main Unraid tab, and it gives me options to format all three.
-
Well damn, I came across another person with the exact same issue. Starting array after upgrading to 6.12.1 stuck at Mounting ZFS Cache Pool (VERIFY3 failed) - General Support - Unraid I'm not sure if I'll be able to follow the same steps, but I don't currently have a backup of what's on that cache pool, so I'd love to get any pointers about getting everything off of there before blowing it all away. And should I stay away from ZFS for the cache pool and head back to btrfs?
-
Hello fine folks, This afternoon, my Unraid server seized, becoming unresponsive even at the terminal. I restarted it, and it came back up, but when it begins to start the array, it hits one of my cache pools and stops there, never finishing mounting. Unfortunately that has a few critical items on it, so I am not sure how to proceed. I set it up as a ZFS pool a little while ago, with three 1TB SSDs, configured as "raidz". The first of the three disks seems to be where it stops mounting, but that may be anecdotal in the GUI. I do see in the attributes of that disk that *Reallocated sector count* has a raw value of 1, while the others are at 0. I've attached the most recent logs - hopefully someone has an idea on how I can get this back up and running. Of course I'm leaving out of town for four days starting tomorrow at 11AM, so the timing is *chef's kiss* - happy to plug away at it tonight if anyone has any thoughts. Thanks everyone for reading! dragonvault-syslog-20230917-0026.zip
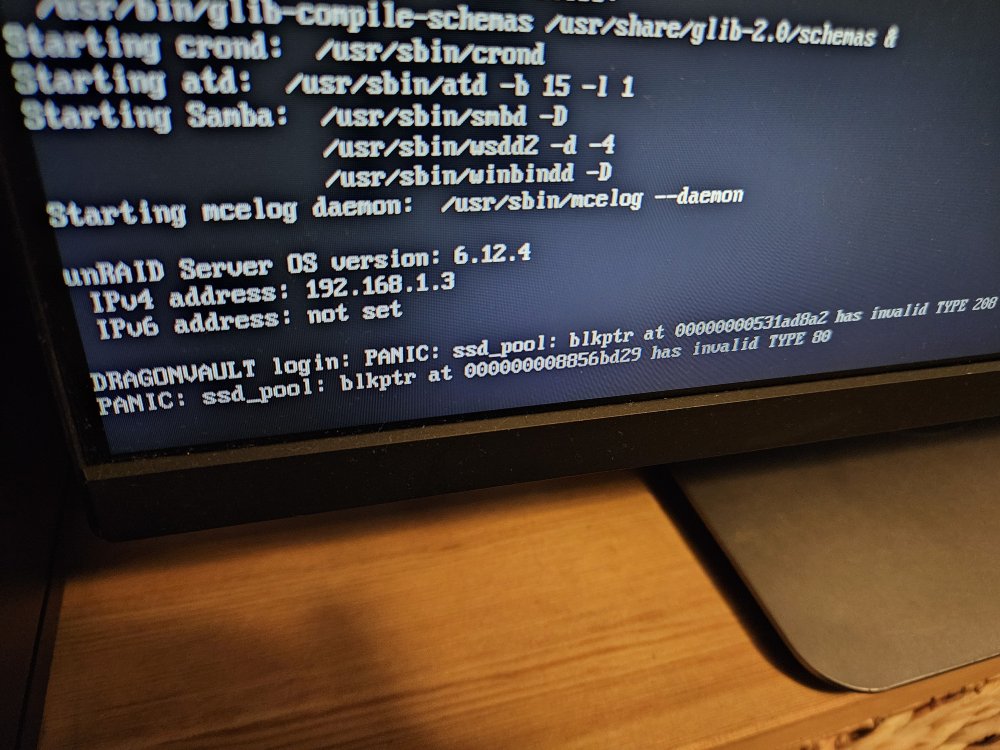
-
@MAM59 Yeah, I get your point, totally. The Docker implementation here isn't perfect (we use Docker extensively at my day job). I think for the occasional container fun and light duty stuff it is fine though. What I'd really like to see is some more direct understanding within Unraid of VMs/containers that are infrastructure-dependent (like pfSense and piHole) that can be temporarily bypassed for boot and then relied upon when they are awake. Would be a pretty bespoke thing at the OS level I'd imagine, though, but that would help to deal with the chicken&egg issue. My ideal thought about it would be to have a rasp pi or nuc or mini-pc that runs a hypervisor with the primary infrastructure stuff running, and then have those paired with VMs/containers in Unraid for an active/passive failover in the event the primary infrastructure stuff needs patching/maintenance/whatever. I'm hoping to give that a whirl when money is more fluid after Christmas. This is all over-engineered silliness for a home lab, but I assume I'm in good company here for that kind of fun.
-
JorgeB, I'm getting a little sick and tired of you being right all the time. That worked a treat. Down and back up in 2 minutes flat (a few more seconds for array starting). I think I am all good! Thanks so much for sticking with me on this. Cheers and happy holidays!
-
Good to know about the port down - that should fix itself when I get to binding those ports to the VM. It is not set to the pfSense VM, but I have it set to a pihole Docker container, which is not live at boot time (obviously), so maybe that's the hangup? Is that why it stops at that winbindd prompt? Should I just drop in some OpenDNS servers in the Network Settings for Unraid?
-
IP is set statically for Unraid on the onboard NIC. The server does have internet access during boot (at this point). One of my issues/frustrations with pfSense is that it is a VM, which doesn't get any love until after the array is started, so if that's the only way internet access is handled, I wouldn't be able to have that work. I'm going to try to set up an active/passive pfSense configuration when I have more hardware to play with, but that's definitely after Christmas, so at this point I'm not using pfSense at all, and the routing is being handled by my Asus router upstream.
-
Hi JorgeB, thanks again for your help - things have been working great since changing away from that slot (upgraded Unraid twice since then, and reconfigured/upgraded my array & cache drives a couple of times to maximize/add space. I'd say the build is solid again, so thank you! Two questions for you to get back to one of the purposes of my original post: - I reinstalled the dual-port NIC, putting in PCIex1-Slot1 - it does start out with both ports "down", but when I go to settings, it seems that I can put them to "port up" in the configuration if I wish. Eventually I'll be pulling these out of boot and adding them to a VM for pfSense (I had done this awhile back and I'd like to get back to it now that the build is steady), but I just want to be sure I'm not experiencing any weird behavior at this point in that slot. - I tried to research this in other threads, but I'm not getting any traction: it seems that, way more than ever before, my boot times have climbed significantly, topping out at nearly 8 minutes (30 seconds on the way down, another minute to regain ping, and then almost six minutes to get to GUI, with an additional 40 seconds to finish starting the array). The almost exclusive majority of that boot time is getting "stuck" on starting winbindd. I can't seem to see anything that is strange about what I have set up at this point, so I'm not sure what caused it to spike so. This obviously makes it difficult to rely on the Unraid box as a pfSense router with 8 minute boot times. I played with the SMB settings but it doesn't seem to have helped. Any thoughts? Thank you again for your help here. dragonvault-diagnostics-20221121-0934.zip
-
Dragonwyntir changed their profile photo
-
JorgeB, you're a gorram genius! Moved the LSI HBA card to PCIex16 Slot 2 and it's working a treat, zero issues. (I did try to push/reseat the card while in Slot 1 but it was in there snug, so perhaps an issue with that slot?) Things have been working beautifully at this point, but perhaps because of the jacking around earlier one of my data drives was marked as Disabled. I'm rebuilding it now, currently at 31% rebuilt. Thank you again for all your help with this - I'll head back down the road of re-adding the dual-NIC to the mix once this "new build" has been vetted for a day or two (Uptime Is Law™), and I'll report back if I get stuck there.
-
Hey JorgeB, thanks for sticking with me on this. Attached latest diags I pulled when I was on lunch. Hoping for a magical fix! dragonvault-diagnostics-20221108-1402.zip
-
Hi Jorge, Sorry for the long wait in reply. I was able to test an onboard port to see the drives were working (makes sense - the entirety of this array worked great and was recognized in the last server, so it'd be scary if all 7 drives did during the switch). I fell down a couple of rabbit holes (isn't that what we do here with homelabs?) and found this on "the other guy's" forum: TrueNAS Scale with ASM1062 SATA not detecting disks | TrueNAS Community It turns out this card runs for 2-port ASM1061 controllers to multiply the ports out, and I've seen warnings across the forums to avoid these sorts of multipliers (and at that link too). So I moved along to find an LSI card with IT-crossed firmware flashing (that topic has been a hell of a ride!), and I now am the proud owner of an LSI 9240-8I card, with 20.00.07.00 IT firmware-flashed before it even got to me. The good: the drives all came up immediately, recognized and happy...for a minute. The bad: I've now immediately started seeing I/O errors reported on some of the drives, which is again weird (this whole build is new, btw, less than a year old, just moved to this new MB and case recently). These I/O errors seem to be severe enough that I can't get my Docker containers started either. Kinda confusing. Anecdotally I've seen that this is a "good" FW to be on, but I am trying to see if there is a newer one maybe? I'll try to attach updated diagnostics after work today, but I just wanted to keep the thread alive. Thanks so much for helping!
-
Sure thing - I actually did do that final change (moved the dual-NIC up) and I FINALLY have GUI access, (no controller access still), so I was able to export these. dragonvault-diagnostics-20221105-1259.zip


