

-C-
-
Posts
91 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by -C-
-
-
2 hours ago, JorgeB said:
That seems very unlikely to me, my first guess would be a disk problem.
Thanks Jorge, I don't know much about the inner workings, but I figure if I can take this disk out of use and try deleting all links to it from Unraid, then try again as if it was a fresh disk to Unraid- if it continues to have issues then I know it's disk issues, if not then it was a software issue. It certainly isn't happy as it is and causing system-wide issues, so I have to do something.
2 hours ago, JorgeB said:Not sure what you mean, it's reporting 800KB/s, not MB/s.
Haha- oh yes, it was late! Still shouldn't have been anything accessing that drive (the only things that are left on there are old archive files), yet it's had this constant read rate at idle for a while now. Nothing listed for this HDD under disk activity or Open Files.
Can you help with how to remove, clear and replace/ retry?
Thanks
-
Following multiple strange issues with my server and increasing weird things going on with this drive, I became ever more suspicious of it. Some examples:
- Unreliable reading or writing and huge usage of resources when attempting to
- unable to copy files off it using Unbalanced (it would eventually time out while doing its initial scan of certain directories and return to its start page).
- Strange permissions issues or permissions changing and trying to set a chmod command would hang indefinitely.
- If I tried to get the size of a directory using File Manager's calculate button on certain directories, it would hang indefinitely.
- There are some directories I've successfully used Unbalanced to clear files out of and onto another drive, but now can't delete the empty directories, even via CLI.
So I've been moving data off. Long, slow process as I'm not sure whether a move is going slowly due to large backup image files, or whether it has hung.
I've nearly finished and what's left on there is of low importance, so I'm about to remove the drive.
My suspicion though is that there's something wrong with Unraid's management of the file system/ FUSE regarding this particular disk and it's been causing huge performance issues system-wide. For another clue to something being awry, have a look at the transfer rate of it, taken a few minutes ago (there was no actual activity on that drive that I know of):

This is a regular SATA HDD- there's no way it could ever attain that kind of speed.
Now that I've got any valuable data off and am at a point of being able to clear it, what is the best method of clearing the drive completely so that any FUSE linking to it is destroyed and I can try it again as if it was a fresh drive to Unraid?
-
I followed this YouTube video to install Immich-
Used the docker apps from the standard Unraid Apps page:
- Immich
- Postgres 15
- Redis
I configured them as directed, only a minimal amount of config was needed in the Docket templates, but Immich wouldn't start up as it was meant to. I didn't have much time to troubleshoot, so gave up for the day.
I found the following day that Nextcloud wouldn't start, and had numerous issues since:
-
Nextcloud wasn't available. I found that MariaDB-Official wouldn't start. The solution to getting that running again seemed to be a combination of reverting to an earlier ZFS snapshot, installing the rc version, then multiple directories in the docker were read-only:
2024-02-27 20:37:36 0 [Warning] Can't create test file '/var/lib/mysql/1dd699d8d500.lower-test' (Errcode: 13 "Permission denied") 2024-02-27 20:37:36 0 [Note] Starting MariaDB 11.4.1-MariaDB-1:11.4.1+maria~ubu2204-log source revision fa69b085b10f19a3a8b6e7adab27c104924333ae as process 28 2024-02-27 20:37:36 0 [ERROR] mariadbd: File './binlog.index' not found (Errcode: 13 "Permission denied") 2024-02-27 20:37:36 0 [ERROR] Aborting 2024-02-27 20:38:09+00:00 [ERROR] [Entrypoint]: Unable to start server. 2024-02-27 20:37:27+00:00 [Note] [Entrypoint]: Entrypoint script for MariaDB Server 1:11.4.1+maria~ubu2204 started. 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: MariaDB upgrade information missing, assuming required 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: Starting temporary server 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: Waiting for server startup
Once I'd chmod 777'd the directories, it started and was OK. -
Once that was fixed, I was getting this error when trying to load Nextcloud:
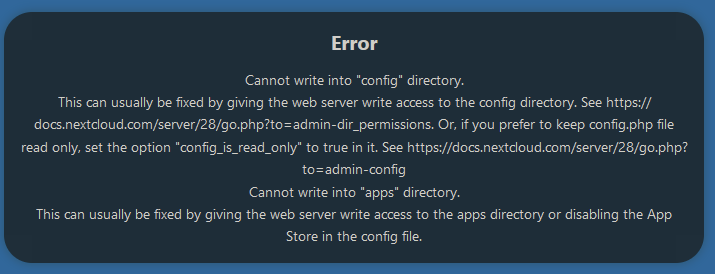
To fix that, I had to chmod 777 those directories.
Following that, Nextcloud would start up, but it's running far slower than it used to.
-
Plex was running fine initially, albeit loading pages slower than usual and the content on its home screen not displaying on first load, but would load after going to another page and then back again. Then a few days ago, it stopped playing files altogether. I got a "Critical: libusb_init failed" in its log. I managed to fix this by doing a "force update" from the Docker page. It pulled some files and worked fine for a few hours. Now today when we tried it again, it's loading pages, but not playing any files, the "Critical: libusb_init failed" error is back, and doing a "force update" isn't pulling files or making any difference.
Generally, everything feels slower. I have tried rebooting twice while trying to troubleshoot since this began, each time I got an unclean shutdown.I understand that it could be complete coincidence that things went wrong just around the time that I'd tried to install Immich, and I'm not saying 100% that's what caused any of this, but as far as I'm aware, that's the only thing that I'd touched on the server before these issues started happening.
Weirdnesses:
- How did installing 3 Docker apps affect anything else? Isn't the whole point of Docker that it's containerised and messing with an App shouldn't be able to affect anything else? I particularly don't get how the directory permissions in appdata of unrelated Docker apps (MariaDB and Nextcloud) were changed when I'd never had any need to go into those directories.
- Even if it wasn't anything to do with installing Immich, how could those permissions change?
- After I restored from the Mariadb ZFS snapshots, I still had permissions issues. I didn't think this was possible- shouldn't a snapshot restoration put everything back to exactly how it was when the snapshot was taken?
- How was Plex slow, but usable for a few weeks, then required a "force reinstall" to start working, which only worked temporarily and now it won't play media at all?
tower-diagnostics-20240312-0057.zip
I also have syslog enabled, so have logs of the whole timespan.
-
23 hours ago, Gvon said:
Did you set Generate Random Password to yes ? If so check your password in the mariadb log overy time you restart the password will change
Thanks- I'm not seeing the password on restart, but I was able to log in with the nextcloud acct rather than root.
I'll figure out the root password another time.
-
14 hours ago, Gvon said:
Restore your snapshot first then change to this repository "mariadb:latest" after that click check for update you will see new version available to update
Unfortunately, that hasn't worked- rolled back to an earlier snapshot, then did as you said but didn't get a new version when I switched to :latest
Everything looks to start up fine in the Mariadb log, but still not able to log in (tried console & Adminer). -
Thanks-
All files under /mnt/user/appdata/mariadb-official are now like this:
-rwxrwxrwx 1 999 users 8192 Jan 23 2023 column_stats.MAD*
Mariadb's running, but Nextcloud still isn't working. I'm getting this in the Mariadb log:
2024-02-28 22:49:12 14 [Warning] Aborted connection 14 to db: 'nextcloud' user: 'nextcloud' host: '172.17.0.1' (Got an error reading communication packets)
I then tried logging in with Adminer, which got this error in Adminer and the same in the Mariadb log:
Access denied for user 'root'@'172.17.0.1' (using password: YES)
My understanding was that a ZFS snapshot would put everything back exactly as it was when the snapshot was taken. How could the permissions be different, and why would they have changed anyway when I haven't been anywhere near that directory?
Any ideas?
-
I've now tried upgrading to 11.4.1-rc and downgrading to 11.2.3 and it's still refusing to start.
Seems to be falling over on startup with the same "Can't create test file" error.
Here's the complete log:
2024-02-27 20:37:36 0 [Warning] Can't create test file '/var/lib/mysql/1dd699d8d500.lower-test' (Errcode: 13 "Permission denied") 2024-02-27 20:37:36 0 [Note] Starting MariaDB 11.4.1-MariaDB-1:11.4.1+maria~ubu2204-log source revision fa69b085b10f19a3a8b6e7adab27c104924333ae as process 28 2024-02-27 20:37:36 0 [ERROR] mariadbd: File './binlog.index' not found (Errcode: 13 "Permission denied") 2024-02-27 20:37:36 0 [ERROR] Aborting 2024-02-27 20:38:09+00:00 [ERROR] [Entrypoint]: Unable to start server. 2024-02-27 20:37:27+00:00 [Note] [Entrypoint]: Entrypoint script for MariaDB Server 1:11.4.1+maria~ubu2204 started. 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: MariaDB upgrade information missing, assuming required 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: Starting temporary server 2024-02-27 20:37:35+00:00 [Note] [Entrypoint]: Waiting for server startup
I've got multiple daily appdata backups going back months- from both the appdata backup plugin, and ZFS snapshots.
I've tried reverting to a snapshot from before the problem, but it's not making any difference.
I've never had to repair/ restore a broken docker app before. Is there something I'm missing?
Could the snapshot restoration not be working because I've changed the versions in the docker script which is causing a mismatch?
Would really appreciate some help with getting this back up as I have a few other things (mostly Nextcloud) that are depending on it.
Thanks
-
Could be a dodgy drive.
Have a read of this: -
On 2/22/2024 at 5:26 AM, Gvon said:
update MariaDB 11.4.0 up seem fix the problem no need to add this to Post Arguments: --transaction-isolation=READ-COMMITTED --log-bin=binlog --binlog-format=ROW --character-set-server=utf8
I've checked for updates on the Docker page, it's saying I'm on the latest version, but when I check the log I seem to be stuck on 11.3.2:
2024-02-25 15:34:48 0 [Warning] Can't create test file '/var/lib/mysql/37ddd26137c4.lower-test' (Errcode: 13 "Permission denied") 2024-02-25 15:34:48 0 [Note] Starting MariaDB 11.3.2-MariaDB-1:11.3.2+maria~ubu2204-log source revision 068a6819eb63bcb01fdfa037c9bf3bf63c33ee42 as process 1
How do I get 11.4.0?
ThanksEdit: I've tried added the post arguments with 11.3.2and still getting the errors.
-
On 2/9/2024 at 5:23 PM, knights_of_pine said:
i am on postgres 15. i am having the same ownership problem. the container works fine with my other containers useing it as a database.
however i can not view it appdata in krusader and it will not back up with appdata backup since it will not let it open its appdata folder.
i have the appdata to mnt/cache in the template not user share.
can someone help me? thank you!
I think this is because it's now outside the share/fuse appdata location.
I'd try changing the appdata backup Appdata source(s) to use mnt/cache rather than mnt/user/appdata or whatever share location you're using for appdata.
-
On 1/6/2024 at 10:09 PM, -C- said:
Have had NC working on Unraid for the last 10 months without too many issues. Now trying to get v28 working. It was initially stuck in maintenance mode, but when I manually took it out of that via CLI, it would load up OK, but the admin status page would show the error "Your web server is not yet properly set up to allow file synchronisation, because the WebDAV interface seems to be broken."
For anyone else having this problem, I've finally managed to fix it.
It turned out to be due to the Groupfolders app.
I was alterted to this from this error;
Some files have not passed the integrity check. Further information on how to resolve this issue can be found in the documentation ↗. (List of invalid files… / Rescan…)When I click the List of invalid files link, I get to <<mynextcloud.url>>/settings/integrity/failed
And that's showing:
Technical information ===================== The following list covers which files have failed the integrity check. Please read the previous linked documentation to learn more about the errors and how to fix them. Results ======= - groupfolders - FILE_MISSING - l10n/hy.json - l10n/ia.js
Followed by a long list of files.
So I could see there was an issue with the Groupfolders app. I updated it through the Nextcloud interface to the latest version and it didn't resolve the issue. But when I disabled the app, suddenly the clients on my devices started syncing and the WebDAV /CalDAV etc. errors were gone.
-
On 1/7/2024 at 5:15 AM, blaine07 said:
Not positive but last few updates have said to update the default.conf. I swear on that I saw some specific things about WebDAV. How old is your default.conf? Very first line should date it..
Maybe your solution though; not positive.

Thanks- I had these 3 that were well out of date:
┌────────────┬────────────┬────────────────────────────────────────────────────────────────────────┐ │ old date │ new date │ path │ ├────────────┼────────────┼────────────────────────────────────────────────────────────────────────┤ │ 2022-08-16 │ 2023-04-13 │ /config/nginx/nginx.conf │ │ 2022-08-20 │ 2024-01-03 │ /config/nginx/site-confs/default.conf │ │ 2022-08-20 │ 2023-08-13 │ /config/nginx/ssl.conf │ └────────────┴────────────┴────────────────────────────────────────────────────────────────────────┘
Have now replaced all 3 with the latest samples and that warning's not displayed in the startup log, but unfortunately it hasn't resolved the WebDAV issue.
-
Have had NC working on Unraid for the last 10 months without too many issues. Now trying to get v28 working. It was initially stuck in maintenance mode, but when I manually took it out of that via CLI, it would load up OK, but the admin status page would show the error "Your web server is not yet properly set up to allow file synchronisation, because the WebDAV interface seems to be broken."
Not turning up anything of use by searching for that error.
I've updated my appdata/nextcloud/www/nextcloud/config/config.php based on the latest config.sample.php file and I'm still getting the same error. Here's my config.php - anything wrong/ missing from here, or other ideas of what could be causing the problem?
<?php $CONFIG = [ 'instanceid' => '****', 'passwordsalt' => '****', 'secret' => '****', 'trusted_domains' => [ '192.168.3.4:3443', 'server.com' ], 'datadirectory' => '/data', 'version' => '28.0.1.1', 'dbtype' => 'mysql', 'dbhost' => '192.168.3.3:3306', 'dbname' => 'nextcloud', 'dbuser' => 'nextcloud', 'dbpassword' => '****', 'dbtableprefix' => 'oc_', 'installed' => true, 'default_language' => 'en_GB', 'force_language' => 'en_GB', 'default_locale' => 'en_GB', 'default_phone_region' => 'GB', 'force_locale' => 'en_GB', 'default_timezone' => 'Europe/London', 'mail_domain' => 'server.com', 'mail_from_address' => '****', 'mail_smtpmode' => 'smtp', 'mail_smtphost' => 'smtp.server.com', 'mail_smtpport' => 465, 'mail_smtpauth' => true, 'mail_smtpsecure' => 'ssl', 'mail_smtpname' => '[email protected]', 'mail_smtppassword' => '****', 'mail_sendmailmode' => 'smtp', 'overwritehost' => 'server.com', 'overwriteprotocol' => 'https', 'bulkupload.enabled' => false, 'maintenance' => false, 'loglevel' => 0, 'theme' => '', 'filelocking.enabled' => 'true', 'memcache.locking' => '\\OC\\Memcache\\APCu', 'memories.exiftool' => '/config/www/nextcloud/apps/memories/bin-ext/exiftool-amd64-musl', 'memories.vod.path' => '/config/www/nextcloud/apps/memories/bin-ext/go-vod-amd64', 'memories.vod.ffmpeg' => '/usr/bin/ffmpeg', 'memories.vod.ffprobe' => '/usr/bin/ffprobe', 'updater.secret' => '****', 'upgrade.disable-web' => true, ];
-
I'm seeing this for the disk

There are no SMART errors.
Is it worth trying a different SATA cable, or is there no way it's a cabling issue if it's syncing at 6 Gb/s?
-
6 hours ago, JorgeB said:
it's filesystem agnostic.
As I had hoped/ assumed, which begs the question- what else could be causing this?
-
In July I added a new 18TB Toshiba MG09ACA18TE.
I was pleased with its speed- as good as, if not better than the 20TB WD drives I have, which were pretty speedy.
Since then, any array operations have felt painfully slow. With 20TB parity drives, the last parity check took over 4 days and the one that's currently running is estimated to take over 5 days. It's fluctuating between 35 & 100 MB/sec.
Diskspeed docker is showing that its speed is now less than half of what it was when first installed:
.thumb.png.d764cb4e3003119463d8caf45ecccce3.png)
The most recent test (Nov 15) was made with all other Docker apps disabled and the VM service off.
Speeds of the other disks have remained stable.
Only thing I can think that happened between the Jul & Sep tests is that I cleared the drive and formatted it as ZFS- could that have had this affect? If so, is there anything I can do about it?
-
This looks like it'd be super useful for me, but I've had no luck trying to get it up and running.
Before I try the 2.1 version as above, wondering whether there's been any advances on getting the latest versions working in the last 6 months.
-
I have some services that automatically save files into a few Dropbox directories.
I'm looking for a way to auto-download just these directories to my Unraid for safe keeping.
I see there a number of Dropbox compatible Docker apps, but not sure which would suit my purpose best.
Any recommendations/ advice most appreciated.
-
55 minutes ago, da02uk said:
I wouldn't judge your dumbness by anything I do, I set a really low bar
Did someone say bar? Great idea!
-
Having read about people having array drives come up as unavailable due to power issues, or other temporary issue, and turn out to be fine, I figured I'd stick the failed drive in a USB caddy, just to see if there were any signs of life. It's come up as fine, passed quick SMART test. So it may well have been a power glitch or something and a reboot would have fixed it.
Not sure whether I should try to use this drive any more, in case there is something up with it.
Here's its attributes:
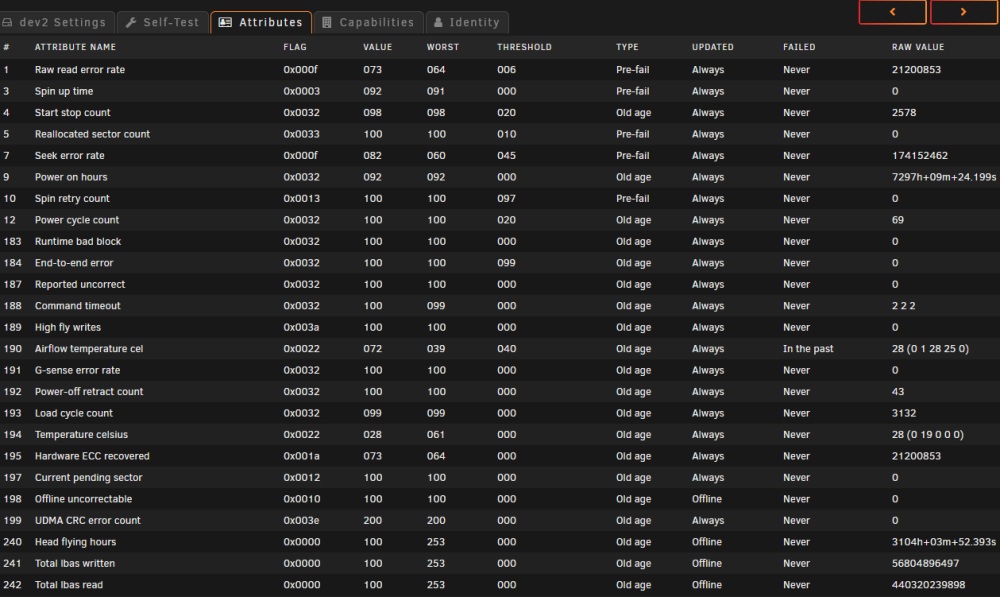
I can browse it and access files no problem.
Is there any way to put this back into the array with its data intact, or am I better off copying the data onto the disk that's now in the array?
So a few lessons learned here- triple read and have a good think about anything array related when there's any possibility of data being lost, and always try turning it off and on again!
-
1 hour ago, da02uk said:
I was replacing an older disc and also wanted to update the file system, so have done the same.
Makes me feel slightly less dumb if someone else has done the same thing!
Good luck, I hope you can put that disk in, but I'll leave that to someone more knowledgeable. -
2 hours ago, JorgeB said:
There already is a warning not to format disks during a rebuild, and the txt changed a couple of times to make as clear as possible, but it seems it doesn't help in some cases.

I took that as a standard "formatting will remove all data on this disk" type warning. I didn't think any of that was relevant to what I was doing- I had an empty disk with no data on it to worry about. To me "...will normally lead to loss of all data on the disk being formatted" is about losing any data on the disk being added, it doesn't mention anything about a different format breaking the rebuild process.
-
Thanks Jorge,
I followed the official guide here: https://docs.unraid.net/unraid-os/manual/storage-management/#replacing-faileddisabled-disks
I had missed the point in the notes there "The rebuild process can never be used to change the format of a disk - it can only rebuild to the existing format."
I wasn't using the process to change the format, it was to replace a failed drive, so I skipped over this point. Then when it came to adding the new disk, I figured that as I was having to format the disk anyway, i might as well switch to ZFS so I can take advantage of some of its benefits over XFS like replication from cache etc.
Now that I think about how parity works, I realise that there was no way it could have worked with a different format type. It was my mistake. This was the first time I rebuilt a disk from parity, so it was all new to me. Fortunately, none of the data on that disk was irreplaceable and I have a backup of most of it.
I do think that there should be a bigger warning about this in the manual to make it clearer that a change of format will stop the rebuild from being able to work. Especially now that I'd imagine there are others like me who'd like to take advantage of ZFS since 6.12 and may be tempted to do what I did.
Even better would be if there's a way for the system to check whether you're trying to rebuild onto a disk with a different format than the one being replaced when attempting to start a rebuild and give a nice clear data loss warning. -



.png.496cbb436595faa6c86e46fd71a395d5.png)


6 month old Toshiba disk running at < 50% of its original speed, array operations painfully slow.
in General Support
Posted
OK, thanks. I will remove it and see how that goes. I don't have a spare drive and prices are not favourable at the moment, so I won't be buying another. If this drive's bad, I'd like to get it replaced by Amazon or the manufacturer.
My worry is- how do I prove there's an issue when there are no SMART errors or anything other than poor performance to show there's an issue with it?