




kirkyg
Members
-
Joined
-
Last visited
-
On a similar topic i have specific use case where media that is 'new content' if you will gets read very often and to avoid spin up and down array drives often id like to have this initially stored on a cache drive (ssd or nvme) (or unassigned disk if there is no other way) that can handle alot of IO and then after say 30-90 days when that content is no longer read often push it to the array. What is the best way to set this up? I was concerned about the consequences of not having access to user shares might do if unassigned disk is the only way to do this. I guess my lack of undersatnding of the details of how mover works may be clouding my visibility to a solution.
-
I noticed that my proxmox instance had some small cpu load and I had disconnected from my windows 10 vm which was doing nothing at the time. The only other thing running was my unraid VM so i was looking in to it to see how much cpu utilization there was. I currently have an lsi hba card passed through that is running preclear on one 14TB drive. I logged into the VM and see 2 cores I have allocated showing one at 100% pegged and the other moving between about 40-90%. When I run htop command in the terminal, as you can see below, there are only 2-3 processes above 0% and the preclear activity is top one with only 5-7% cpu utilization. Is this a reporting issue in the VM where its looking at the entire cpu capacity and reporting against all cores even though only 2 should be allocated as available resources? I also would not expect a preclear operation to max out two cores of a zen 3 5800x - any ideas?
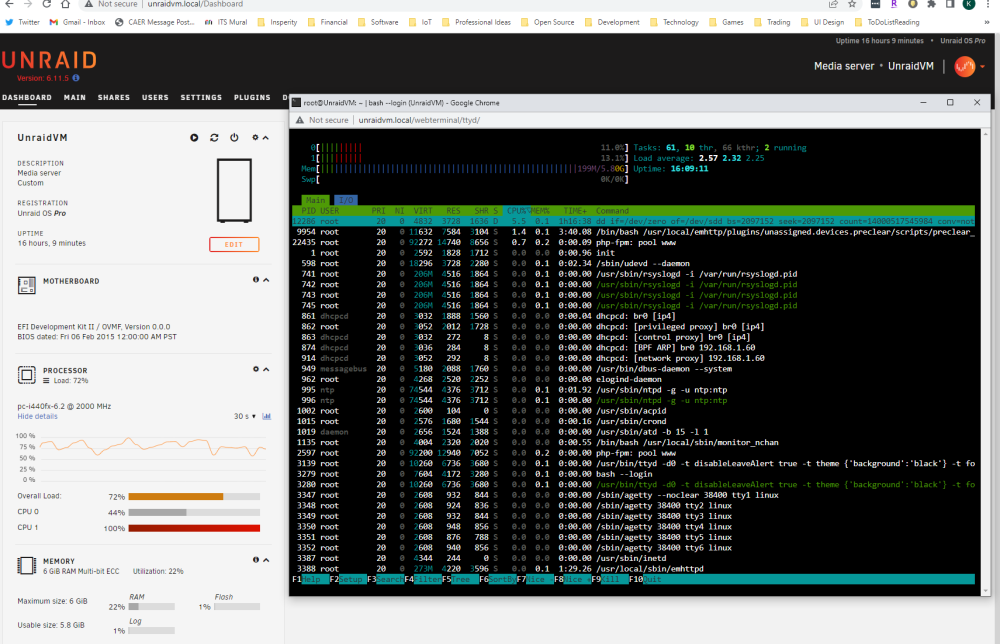
-
Well after some digging i realized that under tools it has a preclear view on the drives and based on this it looks like it was successfully precleared atleast based on status (see attached image). I tried to view the logs and download the logs as well and they are blank for preclearing. Is it normal for it to clear the logs once its successful and/or once a reboot of the machine/vm happens?
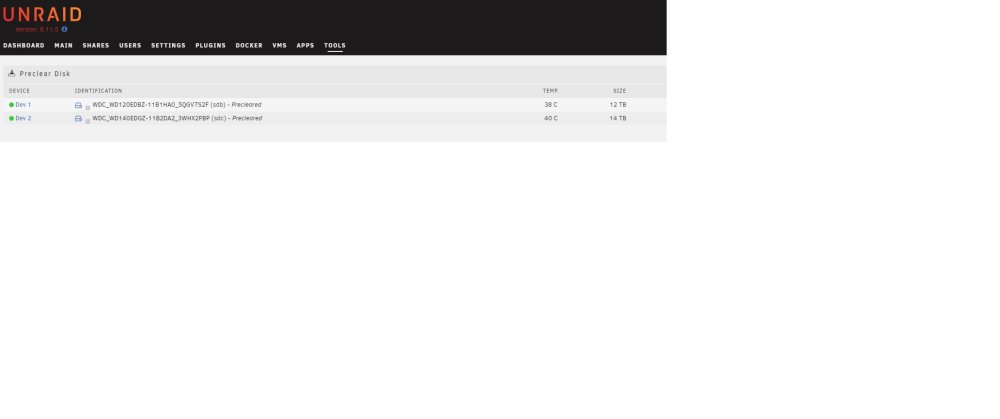
-
So i have recently setup proxmox and installed UD in a VM. Everyone was moving along smoothly...my setup is as follows: Guest has 2 cores and 4gb of ram Passed through lsi HBA card with a 12tb and 14tb drives (WD schucked easystore drives) UD is running off a 64gb samsung usb passed through as well default nvme virtual disk of 10g created when vm was created (unused - i have since removed this disk) I ran preclear process on both drives and it completed the write process successfully after about 20 hours and then it started the read portion (part 4) and was moving along just fine. I went to bed last night and when i woke up my unraid VM was shutdown. So i looked at the logs and saw an error increment early this morning related to the nvme storage which isn't mounted or being used (not sure what that's about). I can't tell any specific reason that the vm shutdown and im just learning how to read all this so thats that. Back to unraid - I'm trying to understanding if it shutdown before or after my drives completed the preclear read. Based on the time it should have finished the read process well before the timestamp of the error if that had anything to do with unraid VM shutting down. -My first specific question is how can I view logs on the preclear process; what i see in shown in the attached jpg file it is not mountable and it looks like it wants me to run preclear again? -My second question is for those that run their's in proxmox is there a straight forward way to see why the VM shutdown granted that it was a 12 hour period that it could have actually shutdown I can provide logs or whatever just walk me through exactly what to capture. Thanks in advance! kirkyg
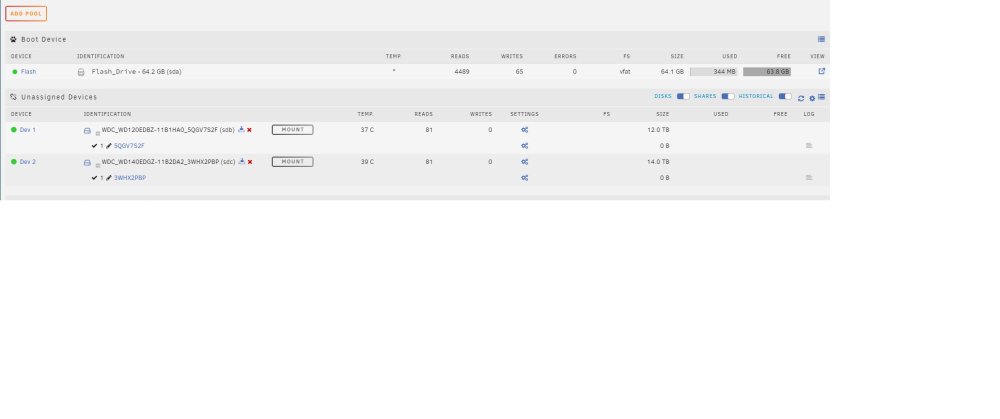
-
I'm setting up an unraid server in a proxmox vm. Currently, I have 6 hds - 4TB x 2, 8TB x 2, 10TB x 1, 12TB x 1 and these drives are in a windows system on a stablebit drive pool. One of the 4tb drives I will remove going forward due to some errors indicating its about to fail soon. Part of the new server migration includes installing a new 12 TB and new 14TB drive the latter of which I would like to be parity so I can try to over time move to mostly 14TB drives. I will pass through an lsi hba card and connect the drives to it. What is the best way to migrate over from the drive pool and start moving the drives over? Is there a way to start moving the data and then enable the parity drive once I have enough drives in the pool to copy all the remaining data?
